
Linguistische Beiträge zur Slavistik
XXVI. und XXVII. JungslavistInnen-Treffen, 6. bis 8. September 2017 in Bamberg und 12. bis 14. September 2018 in Heidelberg
Zusammenfassung
Leseprobe
Inhaltsverzeichnis
- Cover
- Titelseite
- Impressum
- Vorwort
- Inhaltsverzeichnis
- Bamberger Beiträge
- Wie entstehen diakritische Zeichen?
- Clitic Climbing im Tschechischen, Slovenischen und Polnischen: Ein Vergleich
- Fahren wir rijekom Dunavom oder rijekom Dunav entlang? – Appositionen im Kroatischen zwischen Norm und Variation
- Was ist Armeeslavisch?
- Ein methodisches Problem der Linguistic-Landscapes-Forschung: Die Definition einer Analyseeinheit anhand von Beispielen aus der Linguistic Landscape von Minsk
- Perlokutionen in Skandaldiskursen
- Besonderheiten der Valenzmuster der russischen Verben bei Herkunftssprechern des Russischen in Deutschland
- Heidelberger Beiträge
- Die sprachliche Landschaft der Ostslavia zwischen dem 8. Jahrhundert und 1116
- Slavische Mikroliteratursprachen: Status und Ausbaufähigkeit eines Paradigmas
- Sprachliche Landschaften fern der Zentren: Erinnerungsdiskurse im öffentlichen Raum Kroatiens
- Erklärungen für Lautwandelprozesse in der historischen Sprachwissenschaft (am Beispiel des Slavischen)
- Der Feind in der Sprache: Eine linguistische Untersuchung von Feindbildkonstruktionen in der Presseberichterstattung zum Euromaidan 2013-2014
- Die TeilnehmerInnen im Bild
Bamberger Beiträge
←11 | 12→ ←12 | 13→Wie entstehen diakritische Zeichen?
Daniel Bunčić
Abstract
Diacritics have usually been viewed as marks that can be added to an alphabet ad libitum, in any arbitrary shape and for any function that is needed in a given language. This is not the case. Diacritics have a concrete ‘etymology’, which explains the relation between form and function just as etymologies for words explain the relation between signifier and signified. Specifically, diacritics can emerge in four ways: as iconic diacritics, from letters (or parts of letters), from deletion marks, or from disambiguation marks. However, in most cases diacritics are not created from scratch but borrowed from another language, which entails language contact, formal identity, and functional equivalence. (Straightforward functional shifts and formal evolutions are of course possible.)
1. Einleitung
Diakritische Zeichen (Diakritika) werden bisher als eine Art Allzweckwaffe „zur Erweiterung eines Basisalphabets bei zusätzl[ichen] Bezeichnungs- und Differenzierungsnotwendigkeiten durch graph[ische] Zusätze verschiedener Arten“ angesehen, die „auch ganz unsystemat[isch] verwendet werden“ können (Glück 2016: 144). Die Grundidee ist also: Will man eine Sprache verschriften und das vorhandene Graphem-Inventar reicht für das zu repräsentierende Phonem-Inventar nicht aus, so erschafft man neue Grapheme, indem man einzelnen Schriftzeichen irgendwelche beliebigen Punkte, Striche, Häkchen usw. hinzufügt. Das Ziel dieses Beitrags ist es, zu zeigen, dass das eine völlig falsche Vorstellung ist. Vielmehr hat jedes diakritische Zeichen eine ‚Etymologie‘ – das heißt: Trotz der grundsätzlichen Arbitrarität sprachlicher – und somit auch diakritischer – Zeichen in der Synchronie lässt sich der Zusammenhang zwischen Form (signifiant: 〈´〉, 〈¸〉, 〈ˇ〉 usw.) und Funktion (signifié: Langvokal, Sibilant, Palatal usw.) eines jeden Diakritikons diachronisch eindeutig herleiten. Dies soll anhand der europäischen Diakritika (von denen die meisten ja auch in slavischen Sprachen benutzt werden oder wurden) belegt werden (mit gelegentlichen Exkursen zu außereuropäischen Schriften). Konkret scheint es vier verschiedene Typen der Entstehung neuer diakritischer Zeichen zu geben (Kapitel 3). Häufig werden jedoch nicht völlig neue Diakritika kreiert, sondern fertige Diakritika – mit Form und Funktion! – aus einer anderen Sprache entlehnt, was an zwei besonders interessanten und komplexen Fällen demonstriert werden soll (Kapitel 4). Beginnen wir aber mit der Frage, was genau wir unter diakritischen Zeichen verstehen und was nicht (Kapitel 2).
←13 | 14→2. Definitionen
Ein diakritisches Zeichen ist eine „unterscheidende Markierung, die einem Graphem hinzugefügt wird, um ein neues Graphem zu bilden, das innerhalb des sprachspezifischen Schriftsystems distinktiv ist“ (Bunčić angenommen a). Die modifizierende Funktion diakritischer Zeichen kann dabei sehr unterschiedlich sein. Die wohl häufigste bezieht sich auf das phonologische Segment, etwa wenn der Háček im Tschechischen aus dem 〈s〉 für /s/ ein 〈š〉 für /ʃ/ macht: Das Graphem mit dem diakritischen Zeichen bezeichnet ein anderes Phonem als das Grundgraphem ohne diakritisches Zeichen. Ein Sonderfall ist der französische Zirkumflex auf 〈ê〉, der zwar dessen Aussprache als /ɛ/ markiert, sich darin aber nicht vom Gravis auf 〈è〉 unterscheidet. Hier hat der Zirkumflex zusätzlich eine etymologische Funktion, da er den Ausfall eines Lautes bezeichnet (z. B. s bei 〈fête〉 < feste). Nicht selten tragen Diakritika auch suprasegmentale Informationen, z. B. wenn der Gravis in ital. 〈città〉 ,Stadt‘ die Endbetonung dieses Wortes markiert. (Diakritika in dieser Funktion – aber nur diese! – kann man mit Recht Akzentzeichen nennen.) Eine weitere Funktion von Diakritika ist die Unterscheidung homonymer Wörter oder Morpheme, z. B. in frz. 〈où〉 ,wo‘ vs. 〈ou〉 ,oder‘, niederl. 〈één〉 ,ein (Numerale)‘ vs. 〈een〉 ,ein (Artikel)‘ oder im Griechischen des 12.–20. Jahrhunderts bei 〈-ᾳ〉 im Dat. Sg. vs. 〈-α〉 z. B. im Nom. Sg. (also 〈ἡ πολιτεία〉 ,der Staat‘ vs. 〈τῇ πολιτείᾳ〉 ,dem Staate‘).
Von der obigen Definition ausgeschlossen werden 1. Schriftzeichen, die nicht der Modifikation dienen, sondern direkt phonologische Informationen kodieren, und 2. Zeichen, die kein neues Graphem bilden. Von Punkt 1 sind insbesondere die Vokalzeichen im Hebräischen und Arabischen betroffen, die also funktional (entgegen traditionellen Beschreibungen, z. B. Coulmas 1999: 127 oder Thümmel 2002: 162) keine diakritischen Zeichen sind: Der Strich unter dem hebräischen d in  und der Strich über dem arabischen d in
und der Strich über dem arabischen d in 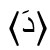 bezeichnen einfach das jeweilige Phonem /a/ und sind damit funktional gleichzusetzen mit Buchstaben wie lateinisch 〈a〉, griechisch 〈α〉 oder glagolitisch
bezeichnen einfach das jeweilige Phonem /a/ und sind damit funktional gleichzusetzen mit Buchstaben wie lateinisch 〈a〉, griechisch 〈α〉 oder glagolitisch 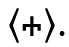 Eine Besonderheit ist lediglich ihre formale Platzierung über bzw. unter einem anderen Buchstaben (sowie ihr Gebrauch nur in bestimmten Kontexten). Aufgrund der funktionalen Autonomie der Vokalisationszeichen werden
Eine Besonderheit ist lediglich ihre formale Platzierung über bzw. unter einem anderen Buchstaben (sowie ihr Gebrauch nur in bestimmten Kontexten). Aufgrund der funktionalen Autonomie der Vokalisationszeichen werden 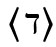 und
und 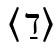 bzw.
bzw. 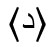 und
und 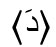 in linguistischen Analysen nie als verschiedene Grapheme angesehen (was die einheitliche Analyse vokalisierter und nicht vokalisierter Texte auch erheblich erschweren würde). Insofern erfüllen die Vokalisationszeichen auch die unter Punkt 2 genannte Anforderung nicht, mit dem Grundgraphem ein neues Graphem zu bilden, – sie sind vielmehr eigenständige Grapheme. Durch diesen Punkt sind außerdem sogenannte Unterscheidungszeichen ausgeschlossen, wie z. B. die ‚u-Flamme‘, die manche Schreiber*innen (früher mehr als heute) handschriftlich über das 〈u〉 ←14 | 15→setzen (also
in linguistischen Analysen nie als verschiedene Grapheme angesehen (was die einheitliche Analyse vokalisierter und nicht vokalisierter Texte auch erheblich erschweren würde). Insofern erfüllen die Vokalisationszeichen auch die unter Punkt 2 genannte Anforderung nicht, mit dem Grundgraphem ein neues Graphem zu bilden, – sie sind vielmehr eigenständige Grapheme. Durch diesen Punkt sind außerdem sogenannte Unterscheidungszeichen ausgeschlossen, wie z. B. die ‚u-Flamme‘, die manche Schreiber*innen (früher mehr als heute) handschriftlich über das 〈u〉 ←14 | 15→setzen (also  1), um die Verwechslung von 〈u〉 und 〈n〉 zu vermeiden, oder der Strich, der in russischer Schreibschrift oft unter 〈ш〉 und über 〈т〉 gesetzt wird (also
1), um die Verwechslung von 〈u〉 und 〈n〉 zu vermeiden, oder der Strich, der in russischer Schreibschrift oft unter 〈ш〉 und über 〈т〉 gesetzt wird (also 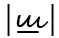 vs.
vs. 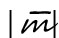 ). Auch der (allerdings heutzutage obligatorische) i-Punkt ist ein solches Unterscheidungszeichen, kein Diakritikon. Solchen Unterscheidungszeichen ist gemein, dass sie kein neues Graphem bilden:
). Auch der (allerdings heutzutage obligatorische) i-Punkt ist ein solches Unterscheidungszeichen, kein Diakritikon. Solchen Unterscheidungszeichen ist gemein, dass sie kein neues Graphem bilden: 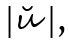
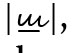
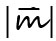 und
und  treten nicht etwa in Opposition zu
treten nicht etwa in Opposition zu 
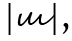
 und †|ı|, sondern sind lediglich verdeutlichende Varianten der Letzteren. (Jedoch können aus Unterscheidungszeichen diakritische Zeichen entstehen, siehe 3.4.)
und †|ı|, sondern sind lediglich verdeutlichende Varianten der Letzteren. (Jedoch können aus Unterscheidungszeichen diakritische Zeichen entstehen, siehe 3.4.)
Formal unterscheidet man diakritische Zeichen nach ihrer Position: superskribierte (auch: supralineare) Diakritika, die (normalerweise mittig) über dem Grundgraphem stehen, wie 〈ä〉, 〈č〉, 〈é〉, 〈ñ〉, 〈ѓ〉, 〈ά〉, 〈 ث〉; subskribierte (oder infralineare) wie 〈ą〉, 〈ç〉, 〈ҙ〉, 〈ῳ〉, 〈ب〉; inskribierte, die in irgendeiner Form in das Grundgraphem hineingesetzt werden oder es durchqueren, wie 〈đ〉, 〈ł〉, 〈ø〉, 〈ҝ〉, 〈ج〉; und adskribierte, die neben das Grundgraphem gesetzt werden, wie 〈ơ〉, 〈ŀ〉, 〈ď〉, 〈Ὤ〉, 〈ぽ〉.
Eine Sonderform diakritischer Zeichen – oder je nach Definition auch eine separate Kategorie – stellen untrennbar mit dem Duktus des Grundgraphems verbundene DIAKRITISCHE ELEMENTE dar, wie etwa in 〈ŋ〉 vs. 〈n〉, 〈щ〉 vs. 〈ш〉 oder 〈ъ〉 vs. 〈ь〉. Diese Kategorie ist jedoch schwer abzugrenzen. Auf der einen Seite wird man z. B. den unteren Balken, der das 〈E〉 vom 〈F〉 unterscheidet, kaum als diakritisches Element ansehen wollen. Hier lässt sich funktional argumentieren, da 〈E〉 und 〈F〉 keinerlei gemeinsame ‚Grundbedeutung‘ haben, die durch den Strich modifiziert werden könnte. Auf der anderen Seite sind auch Querstriche wie bei 〈đ〉, die Cedille wie in 〈ç〉, der Ogonek wie in 〈ą〉 oder das Horn wie in 〈ơ〉 mit dem Grundgraphem verbunden. Die handschriftliche Schreibweise könnte hier ein Kriterium sein: Bei diakritischen Zeichen im engeren Sinne wird abgesetzt und das diakritische Zeichen nachträglich angebracht (man schreibt also erst das 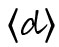 – oft auch erst das gesamte Wort – und setzt dann nach einem Absetzen der Feder den Querstrich
– oft auch erst das gesamte Wort – und setzt dann nach einem Absetzen der Feder den Querstrich 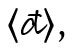 ebenso erst das
ebenso erst das 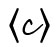 und dann die Cedille darunter
und dann die Cedille darunter  usw.), während diakritische Elemente in einem Zug mit dem Grundgraphem geschrieben werden (z. B.
usw.), während diakritische Elemente in einem Zug mit dem Grundgraphem geschrieben werden (z. B. 

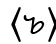 ). Allerdings wird auch der polnische Ogonek, der üblicherweise als diakritisches Zeichen im engeren Sinne angesehen wird, wie ein diakritisches Element in einem Zug geschrieben (z. B.
). Allerdings wird auch der polnische Ogonek, der üblicherweise als diakritisches Zeichen im engeren Sinne angesehen wird, wie ein diakritisches Element in einem Zug geschrieben (z. B. 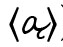 ).
).
Da auch adskribierte Zeichen wie der Punkt in 〈ŀ〉 oder der Apostroph in 〈ď〉 diakritische Zeichen sind, ist der Weg zum ebenfalls horizontal danebengesetzten DIAKRITISCHEN BUCHSTABEN nicht mehr weit. In der Tat haben 〈h〉 in ital. 〈chi〉 ,wer‘, 〈u〉 in frz. 〈guerre〉 ,Krieg‘ und 〈i〉 in poln. 〈się〉 ,sich‘ die gleiche Funktion wie diakritische Zeichen: Sie modifizieren die Bedeutung des vorausgehenden Buchstabens, indem sie klären, dass 〈c〉 für /k/ (und nicht 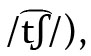 〈g〉 für /ɡ/ (und nicht
〈g〉 für /ɡ/ (und nicht 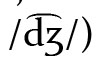 bzw. 〈s〉 für
bzw. 〈s〉 für 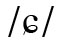 (und nicht /s/) steht. Teilweise werden diese Kombinationen als Digraphen interpretiert, was im italienischen Fall gut funktioniert, hier repräsentiert 〈ch〉 einheitlich /k/. Jedoch steht frz. 〈gu〉 zwar in 〈guerre〉 für /ɡ/, in 〈aigu〉 ,scharf, spitz‘ jedoch für /ɡy/, ebenso wie poln. 〈si〉 etwa in 〈siła〉 ,Kraft‘ nicht für
(und nicht /s/) steht. Teilweise werden diese Kombinationen als Digraphen interpretiert, was im italienischen Fall gut funktioniert, hier repräsentiert 〈ch〉 einheitlich /k/. Jedoch steht frz. 〈gu〉 zwar in 〈guerre〉 für /ɡ/, in 〈aigu〉 ,scharf, spitz‘ jedoch für /ɡy/, ebenso wie poln. 〈si〉 etwa in 〈siła〉 ,Kraft‘ nicht für 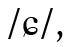 sondern für
sondern für 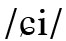 steht. Im Italienischen hat das 〈h〉 fast keine andere Funktion als die diakritische in den Kombinationen 〈ch〉 /k/ und 〈gh〉 / ɡ/. Die einzige andere Funktion außerhalb von Eigennamen und Interjektionen ist die der Kennzeichnung von vier Präsensformen von avere ,haben‘ – ho (1SG), hai (2SG), ha (3SG) und hanno (3PL) –, um sie von Homonymen abzugrenzen (o ,oder‘, ai ,zu den‘, a ,zu‘ und anno ,Jahr‘). In dieser Funktion ist interessanterweise zeitweilig auch der Gravis statt des 〈h〉 benutzt worden, so dass die fraglichen Formen von ,haben‘
steht. Im Italienischen hat das 〈h〉 fast keine andere Funktion als die diakritische in den Kombinationen 〈ch〉 /k/ und 〈gh〉 / ɡ/. Die einzige andere Funktion außerhalb von Eigennamen und Interjektionen ist die der Kennzeichnung von vier Präsensformen von avere ,haben‘ – ho (1SG), hai (2SG), ha (3SG) und hanno (3PL) –, um sie von Homonymen abzugrenzen (o ,oder‘, ai ,zu den‘, a ,zu‘ und anno ,Jahr‘). In dieser Funktion ist interessanterweise zeitweilig auch der Gravis statt des 〈h〉 benutzt worden, so dass die fraglichen Formen von ,haben‘  〈ài〉, 〈à〉 und 〈ànno〉 geschrieben wurden (Bultro et al. 2004–2018). Ebenso wird im Polnischen 〈si〉 nur vor Vokalen geschrieben, während in anderen Positionen gleichbedeutend 〈ś〉 mit Strich geschrieben wird. Die funktionale Äquivalenz von diakritischen Buchstaben und diakritischen Zeichen ist also offensichtlich. In diesem Beitrag wird es jedoch schon deshalb nicht um diakritische Buchstaben gehen, weil deren Herkunft von vornherein klar ist: Sie sind eben Buchstaben. Diakritische Elemente bleiben ebenfalls aus der Betrachtung ausgeklammert.
〈ài〉, 〈à〉 und 〈ànno〉 geschrieben wurden (Bultro et al. 2004–2018). Ebenso wird im Polnischen 〈si〉 nur vor Vokalen geschrieben, während in anderen Positionen gleichbedeutend 〈ś〉 mit Strich geschrieben wird. Die funktionale Äquivalenz von diakritischen Buchstaben und diakritischen Zeichen ist also offensichtlich. In diesem Beitrag wird es jedoch schon deshalb nicht um diakritische Buchstaben gehen, weil deren Herkunft von vornherein klar ist: Sie sind eben Buchstaben. Diakritische Elemente bleiben ebenfalls aus der Betrachtung ausgeklammert.
3. Vier Arten der Entstehung neuer Diakritika
3.1 Ikonische Diakritika
Unter Ikonizität versteht man eine formale Ähnlichkeit zwischen signifiant und signifié. Der wohl bekannteste Fall sind onomatopoetische Wörter wie Kuckuck (russ. kukuška, poln. kukułka, skr. kukavica, frz. coucou, engl. cuckoo usw.), deren lautliche Form den Klang des Bezeichneten nachahmt. Bei ikonischen Diakritika liegt dementsprechend eine visuelle Ähnlichkeit vor.
Eine solche Ähnlichkeit ist bei den griechischen AKZENTZEICHEN zu erkennen, die ursprünglich ikonisch einen steigenden Ton mit 〈´〉, einen fallenden Ton mit 〈`〉 und einen zuerst ansteigenden und dann abfallenden Ton mit  bezeichneten. Dabei beruht die Ikonizität der Zeichen natürlich auf der räumlichen Metapher für Tonhöhe (zu deren Entwicklung vgl. Grutschus ←16 | 17→2009: 147–152). Die Namen dieser diakritischen Zeichen, ὀξεῖα ,spitz‘, βαρεῖα ,schwer‘ und περισπωμένη ,herumgezogen‘ bzw. lateinisch acutus ,spitz‘, gravis ,schwer‘ und circumflexus ,umgebogen‘, beruhen hingegen wohl auf einer anderen Metapher für Tonhöhen, der „haptischen“ (vgl. ebd. 136–140).
bezeichneten. Dabei beruht die Ikonizität der Zeichen natürlich auf der räumlichen Metapher für Tonhöhe (zu deren Entwicklung vgl. Grutschus ←16 | 17→2009: 147–152). Die Namen dieser diakritischen Zeichen, ὀξεῖα ,spitz‘, βαρεῖα ,schwer‘ und περισπωμένη ,herumgezogen‘ bzw. lateinisch acutus ,spitz‘, gravis ,schwer‘ und circumflexus ,umgebogen‘, beruhen hingegen wohl auf einer anderen Metapher für Tonhöhen, der „haptischen“ (vgl. ebd. 136–140).
Als ikonisch ist sicherlich auch das Paar aus MAKRON 〈¯〉 (griechischer Name: μακρά ,lang‘) für Langvokale und BREVE 〈˘〉 (griech. βραχεῖα ,kurz‘) für Kurzvokale aufzufassen. Man denke auch an die schriftliche Darstellung des Morsealphabets, bei der für ,lang‘ ebenfalls ein Strich, für ,kurz‘ allerdings ein Punkt verwendet wird (wobei nicht völlig auszuschließen ist, dass sich auch die Breve womöglich aus einem Punkt *〈˙〉 entwickelt hat, ähnlich wie der von den Hussiten ins Tschechische eingeführte Punkt 〈˙〉 zu einem Háček 〈ˇ〉 geworden ist).
Ein weiteres, auch ursprünglich im Griechischen entstandenes Diakritikon ist das TREMA 〈¨〉 (auch Diärese, griech. διαίρεσις ,Trennung‘), das markiert, dass zwei Buchstaben getrennt zu lesen sind, also z. B. zwei Vokale nicht als Diphthong aufzufassen sind, sondern in verschiedenen Silben stehen. (Das deutsche Wort Trema kommt über frz. tréma von griech. τρῆμα ,Loch, Öffnung, Lücke‘, das vielleicht für einen gefühlten Stimmabsatz oder zumindest einen phonetischen Energieabfall an der Silbengrenze steht.) Hier bezeichnen die beiden nebeneinanderliegenden Punkte offenbar die beiden getrennten Silben, die zu sprechen sind.
Ikonizität ist die einzige Möglichkeit, wie diakritische Zeichen mit einer völlig neuen Form entstehen können. Bei den folgenden drei Entstehungswegen werden bereits existierende Zeichen zu Diakritika umgedeutet – dabei handelt es sich also um Fälle von Funktionswandel.
3.2 Tilgungsdiakritika
Eine solche Gruppe von Zeichen, aus denen diakritische Zeichen entstehen können, sind die Tilgungszeichen. In erster Linie betrifft dies ‚durchgestrichene‘ Buchstaben, so etwa poln. 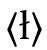 für /w/ (< /ɫ/), niedersorb.
für /w/ (< /ɫ/), niedersorb.  für /ʃ/ (vs.
für /ʃ/ (vs.  für
für  /) oder altnordisch
/) oder altnordisch 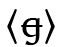 für /ŋ/ (vs. 〈ɡ〉 für /ɡ/; z. B. im Ersten Grammatischen Traktat, S. 88, siehe Haugen 1972: 26 f., 57). Die Grundidee ist hier, dass der jeweilige Grundbuchstabe ‚nicht der richtige‘ ist und deshalb durchgestrichen wird; jedoch gibt es kein anderes Graphem, das besser passt, so dass keine positive Korrektur stattfinden kann und das durchgestrichene Graphem stehen bleibt. Da die Durchstreichung also letztlich nur eine Metapher ist, ist es natürlich wichtig, dass das Grundgraphem trotz der Tilgung gut lesbar ist, und im Laufe der Zeit wird auch wichtig, dass es sich zusammen mit dem Tilgungsstrich gut schreiben lässt. Daher gehen viele dieser diakritischen Tilgungsstriche nicht mittig durch das gesamte Grundgraphem (was die Lesbarkeit, insbesondere handschriftlich, teilweise sehr verschlech←17 | 18→tern würde), sondern durchqueren nur einen Teil davon, so z. B. bei skr. 〈Đđ〉 für
für /ŋ/ (vs. 〈ɡ〉 für /ɡ/; z. B. im Ersten Grammatischen Traktat, S. 88, siehe Haugen 1972: 26 f., 57). Die Grundidee ist hier, dass der jeweilige Grundbuchstabe ‚nicht der richtige‘ ist und deshalb durchgestrichen wird; jedoch gibt es kein anderes Graphem, das besser passt, so dass keine positive Korrektur stattfinden kann und das durchgestrichene Graphem stehen bleibt. Da die Durchstreichung also letztlich nur eine Metapher ist, ist es natürlich wichtig, dass das Grundgraphem trotz der Tilgung gut lesbar ist, und im Laufe der Zeit wird auch wichtig, dass es sich zusammen mit dem Tilgungsstrich gut schreiben lässt. Daher gehen viele dieser diakritischen Tilgungsstriche nicht mittig durch das gesamte Grundgraphem (was die Lesbarkeit, insbesondere handschriftlich, teilweise sehr verschlech←17 | 18→tern würde), sondern durchqueren nur einen Teil davon, so z. B. bei skr. 〈Đđ〉 für 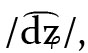 isländisch
isländisch 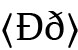 für
für  (aus der insularen Form des 〈d〉) oder maltes. 〈ħ〉 (für /ħ/). Bei manchen Buchstaben sind in unterschiedlichen Situationen verschiedene Möglichkeiten genutzt worden (z. B.
(aus der insularen Form des 〈d〉) oder maltes. 〈ħ〉 (für /ħ/). Bei manchen Buchstaben sind in unterschiedlichen Situationen verschiedene Möglichkeiten genutzt worden (z. B.  in der lettischen Orthographie vor 1921 für /c/,
in der lettischen Orthographie vor 1921 für /c/, 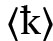 und
und  als lateinische Abkürzungen, z. B. für kalendae oder kapitulum, vgl. Cappelli 1928: 195). Noch verbreiteter als in Orthographien scheint die Durchstreichung in Transkriptionssystemen aller Art zu sein (vgl. z. B. die IPA-Zeichen
als lateinische Abkürzungen, z. B. für kalendae oder kapitulum, vgl. Cappelli 1928: 195). Noch verbreiteter als in Orthographien scheint die Durchstreichung in Transkriptionssystemen aller Art zu sein (vgl. z. B. die IPA-Zeichen 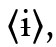
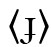 und
und 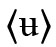 sowie die aus den oben genannten Orthographien übernommenen
sowie die aus den oben genannten Orthographien übernommenen 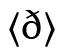 und
und 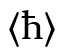 oder in der alten Duden-Lautschrift 〈ch〉 für /χ/, 〈ng〉 für /ŋ/, 〈sch〉 für /ʒ/, 〈th〉 für /θ/ und 〈dh〉 für /ð/, vgl. Duden 1967: 13).
oder in der alten Duden-Lautschrift 〈ch〉 für /χ/, 〈ng〉 für /ŋ/, 〈sch〉 für /ʒ/, 〈th〉 für /θ/ und 〈dh〉 für /ð/, vgl. Duden 1967: 13).
Ein heute nicht mehr gebräuchliches Tilgungszeichen ist das so genannte punctum delens, das in der lateinischen Schreibtradition entweder über oder unter den zu tilgenden Buchstaben gesetzt wurde. Dieser PUNKT wurde vor allem in „ceremonious or artistic manuscripts“ (Barrett & Iredale 1995: 67) benutzt, da eine dezente Markierung wie 〈Feẹhler〉 oder 〈Feėhler〉 die Seite auf den ersten Blick weniger entstellte als 〈Fee̸hler〉 oder 〈Fe■hler〉. Sobald der Leser aber zu der mit dem punctum delens markierten Textstelle kam, sah er es und wusste, dass der entsprechende Buchstabe nicht gelesen werden sollte. Dieser Tilgungspunkt wurde im Altirischen zu einem diakritischen Zeichen entwickelt, dem sogenannten ponc séimhithe [ˈpˠʊŋk ˈʃeːvʲɪhə] ,Lenitionspunkt‘ 〈˙〉 auf 〈ṗ〉 [f], 〈ḃ〉 [w], 〈ṫ〉 [θ > h], 〈ḋ〉 [ð > ɣ], 〈ċ〉 [x], 〈ġ〉 [ɣ], 〈ḟ〉 [w > ∅], 〈ṁ〉 [w̃ > w] und 〈ṡ〉 [h]. Dabei gab es sogar eine zusätzliche Brücke vom Tilgungszeichen zum Diakritikon, denn der Punkt wurde anfangs nur auf 〈ḟ〉 und 〈ṡ〉 gesetzt, von denen das erste komplett geschwunden war und das zweite in bestimmten Fällen ebenfalls nicht gesprochen wurde (vgl. z. B. den Familiennamen McEntegart, der auf mac int ṡacairt zurückgeht, was ,Sohn des Priesters‘ bedeutet (ṡacairt kommt von lat. sacerdos ,Priester‘) und /mak iNt aɡəRdʲ/ gesprochen wurde; McManus 1996: 659). Danach wurde der nun diakritische Punkt analog auf andere Buchstaben übertragen.
Der altpolnische Nasalvokal /ɑ̃/ wurde in Handschriften durch ein durchgestrichenes 〈a̸〉 dargestellt (das bisweilen zu einer Art 〈ø〉 vereinfacht wurde). Die urslavischen Nasalvokale *ę und *ǫ waren ja im Altpolnischen zu /ɑ̃/ zusammengefallen. Durch verschiedene Lautwandel konnte dieser Nasalvokal auch gedehnt als /ɑ̃ː/ auftreten, das einfach durch Verdopplung als 〈a̸a̸〉 (bzw. 〈øø〉) geschrieben wurde. Da am Beginn des 16. Jahrhunderts die Quantitätsunterschiede aber durch Qualitätsunterschiede ersetzt worden waren, schlug Zaborowski (1983 [1514/1518]: 56, 78, 91) in seinem Orthographie-Traktat eine Differenzierung in 〈a〉 mit kurzem Strich oben („semivirgula superior“) und 〈a〉 mit langem Strich („integra virgula“) vor. So erscheint im Druck des Traktats das ehemalige 〈Ra̸ka̸a̸〉 ,mit der Hand‘ (heute 〈ręką〉) als  (ebd.: 71). Aufgrund der Entwicklung des kurzen /ɑ̃/ zu /ɛ̃/ (während ←18 | 19→das lange /ɑ̃ː/ zu /ɔ̃/ geworden ist) führte dann Hieronymus Vietor 1521 parallel zum
(ebd.: 71). Aufgrund der Entwicklung des kurzen /ɑ̃/ zu /ɛ̃/ (während ←18 | 19→das lange /ɑ̃ː/ zu /ɔ̃/ geworden ist) führte dann Hieronymus Vietor 1521 parallel zum 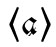 mit kleinem Querstrich ein ebensolches gestrichenes
mit kleinem Querstrich ein ebensolches gestrichenes 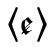 ein (vgl. Bunčić 2012: 235). In der Antiqua wurden die polnischen Nasalvokalzeichen
ein (vgl. Bunčić 2012: 235). In der Antiqua wurden die polnischen Nasalvokalzeichen 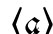 und
und  dann zu 〈ą〉 und 〈ę〉, mit Ogonek. Dieser aber gehört in die folgende Kategorie der Buchstabendiakritika.
dann zu 〈ą〉 und 〈ę〉, mit Ogonek. Dieser aber gehört in die folgende Kategorie der Buchstabendiakritika.
3.3 Buchstabendiakritika
Als Buchstabendiakritika bezeichne ich diakritische Zeichen, die entweder aus ganzen Buchstaben oder aus Teilen von Buchstaben entstanden sind. Auf einen ganzen Buchstaben, nämlich das 〈a〉, geht z. B. der RING im Skandinavischen zurück. Der Laut /aː/ > /ɔ/ > /o/ wurde zunächst (und im Dänischen bis 1948) als 〈aa〉 geschrieben. Dieser Digraph konnte zur Platzersparnis auch vertikal geschrieben werden: 〈aͣ〉. Daraus entstand dann das heutige 〈å〉, mit dem sogenannten Ring als diakritischem Zeichen. Der Ring im Tschechischen hat hingegen eine andere Etymologie: Hier wurde der Diphthong  /, der aus /oː/ entstanden war und sich später zum /uː/ weiterentwickeln würde, zunächst 〈uo〉 geschrieben. Aus diesem entstand dann, ähnlich wie im Skandinavischen, in vertikaler Schreibweise 〈ů〉. Die beiden Ringe sind also homonym: Sie haben unterschiedliche (obschon in diesem Fall sehr ähnliche) Funktionen und nur durch einen historischen Zufall dieselbe Form.
/, der aus /oː/ entstanden war und sich später zum /uː/ weiterentwickeln würde, zunächst 〈uo〉 geschrieben. Aus diesem entstand dann, ähnlich wie im Skandinavischen, in vertikaler Schreibweise 〈ů〉. Die beiden Ringe sind also homonym: Sie haben unterschiedliche (obschon in diesem Fall sehr ähnliche) Funktionen und nur durch einen historischen Zufall dieselbe Form.
Ebenfalls direkt aus einem Buchstaben entstanden sind die deutschen UMLAUTPUNKTE. Noch heute wird statt 〈ä〉 〈ö〉 〈ü〉 ja bei Bedarf auch 〈ae〉 〈oe〉 〈ue〉 geschrieben (z. B. in Internet-Adressen, die keine Umlaute zulassen). Aus Frakturdrucken kennt man auch noch die vertikale Schreibweise 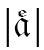
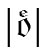 |ü|. Um zu verstehen, wie aus einem 〈e〉 zwei Punkte werden konnten, muss man sich zum einen klarmachen, dass die Punkte |¨| nur eine Vereinfachung der handschriftlich immer noch gesetzten Striche |ʺ| sind, und zum anderen, dass das 〈e〉 in der deutschen Kurrentschrift (die besser unter dem ungenauen Namen Sütterlin bekannt ist) aus genau solchen zwei Strichen besteht:
|ü|. Um zu verstehen, wie aus einem 〈e〉 zwei Punkte werden konnten, muss man sich zum einen klarmachen, dass die Punkte |¨| nur eine Vereinfachung der handschriftlich immer noch gesetzten Striche |ʺ| sind, und zum anderen, dass das 〈e〉 in der deutschen Kurrentschrift (die besser unter dem ungenauen Namen Sütterlin bekannt ist) aus genau solchen zwei Strichen besteht:  So konnte also in der alten deutschen Schreibschrift sehr leicht
So konnte also in der alten deutschen Schreibschrift sehr leicht 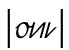
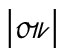
 über
über 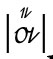

 zu
zu 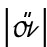

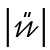 werden.
werden.
Auch 〈n〉 und 〈m〉 wurden schon im Mittelalter oft zur Platzersparnis über der Zeile geschrieben, wobei deren Form zu einer einfachen Wellenlinie 〈˜〉 reduziert wurde. Dieser ‚Nasalstrich‘, der bisweilen auch weiter zu einer geraden Linie |¯| vereinfacht werden konnte, blieb zunächst eine optionale Verkürzung; |tãdẽ|, |tãdem|, |tandẽ| und |tandem| waren also freie, austauschbare Realisationen von lat. 〈tandem〉 ,endlich‘. Im Spanischen ist dann /nː/, das |nn| oder |ñ| geschrieben werden konnte, zu /ɲ/ palatalisiert worden (ebenso wie auch /lː/ 〈ll〉 zu /ʎ/ palatalisiert und dann zu /j/ vereinfacht wurde). Als dann für /ɲ/ nur noch 〈ñ〉 geschrieben und der Nasalstrich nicht mehr in anderen Kontexten benutzt wurde, war die sogenannte TILDE 〈˜〉 zu ←19 | 20→einem diakritischen Zeichen geworden. Etwas Ähnliches geschah im Portugiesischen: Dort wurden Vokale vor /m/ und /n/ im Silbenauslaut unter Ausfall des Nasalkonsonanten nasaliert, z. B. 〈bom〉 /bõ/ ,gut‘. In bestimmten Positionen ist die Schreibung des Nasalkonsonanten als Tilde standardisiert, z. B. 〈nação〉  ,Nation‘ oder 〈nações〉
,Nation‘ oder 〈nações〉 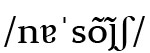 ,Nationen‘. Als Nasalitätszeichen wurde die Tilde auch in andere Sprachen, z. B. das Kaschubische, wo 〈ã〉 für /ɑ̃/ im Gegensatz zu 〈ą〉 für /ɔ̃/ steht, sowie z. B. in das Internationale Phonetische Alphabet (IPA) übernommen.
,Nationen‘. Als Nasalitätszeichen wurde die Tilde auch in andere Sprachen, z. B. das Kaschubische, wo 〈ã〉 für /ɑ̃/ im Gegensatz zu 〈ą〉 für /ɔ̃/ steht, sowie z. B. in das Internationale Phonetische Alphabet (IPA) übernommen.
Ein schönes Beispiel für ein diakritisches Zeichen, das nur aus einem Teil eines Buchstabens entstanden ist, ist die CEDILLE. Sie entstand in Spanien, wo im Mittelalter die sogenannte westgotische Kursive in Gebrauch war. In dieser Variante des lateinischen Alphabets wurde 〈z〉 nicht nur in seiner ‚gotischen‘ Form  geschrieben, sondern hatte zusätzlich noch oben einen Anstrich erhalten:
geschrieben, sondern hatte zusätzlich noch oben einen Anstrich erhalten: 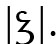 Dieser in der Paläographie copete ,Haube‘ genannte Bogen wurde mit der Zeit immer größer und schließlich zum 〈c〉 umgedeutet, so dass der Rest der zeda copetuda (,z mit Haube‘) nur noch als zedilla ,kleines z‘ unter dem 〈c〉 erschien: 〈ç〉 (Menéndez Pidal 1954: 212–221). In dem Augenblick, in dem man diesen Buchstaben als eine Variante von 〈c〉 interpretierte und nicht mehr als eine Form des 〈z〉, war 〈¸〉 zu einem diakritischen Zeichen geworden.
Dieser in der Paläographie copete ,Haube‘ genannte Bogen wurde mit der Zeit immer größer und schließlich zum 〈c〉 umgedeutet, so dass der Rest der zeda copetuda (,z mit Haube‘) nur noch als zedilla ,kleines z‘ unter dem 〈c〉 erschien: 〈ç〉 (Menéndez Pidal 1954: 212–221). In dem Augenblick, in dem man diesen Buchstaben als eine Variante von 〈c〉 interpretierte und nicht mehr als eine Form des 〈z〉, war 〈¸〉 zu einem diakritischen Zeichen geworden.
Im Italienischen hat das 〈ç〉 hingegen eine etwas andere Funktion. DieRepräsentation von palatalisiertem *k vor hinteren Vokalen ist dort früh durch diakritisches 〈i〉 gelöst worden (z. B. 〈ciabatta〉 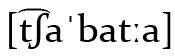 ,Pantoffel; Ciabatta-Brot‘), daher wurde 〈ç〉 dafür nicht benötigt. Jedoch gibt es im Italienischen verschiedene Ergebnisse diverser Palatalisationen, darunter
,Pantoffel; Ciabatta-Brot‘), daher wurde 〈ç〉 dafür nicht benötigt. Jedoch gibt es im Italienischen verschiedene Ergebnisse diverser Palatalisationen, darunter 
 und
und  wofür die Buchstaben 〈c〉 und 〈z〉 nicht ausreichten, so dass 〈ç〉 als dritter Buchstabe hinzukam. Laut Kramer (1996: 587) ist 〈ç〉 aber unabhängig von der spanischen Tradition auf ganz ähnliche Weise durch Umdeutung des ins Italienische entlehnten griechischen Zeta
wofür die Buchstaben 〈c〉 und 〈z〉 nicht ausreichten, so dass 〈ç〉 als dritter Buchstabe hinzukam. Laut Kramer (1996: 587) ist 〈ç〉 aber unabhängig von der spanischen Tradition auf ganz ähnliche Weise durch Umdeutung des ins Italienische entlehnten griechischen Zeta  entstanden. Wenn dem so ist, verbergen sich hinter der Cedille also wiederum zwei homonyme Zeichen, diesmal mit zufällig auch recht ähnlichen Funktionen.
entstanden. Wenn dem so ist, verbergen sich hinter der Cedille also wiederum zwei homonyme Zeichen, diesmal mit zufällig auch recht ähnlichen Funktionen.
Die wohl berühmtesten Beispiele für aus Buchstabenteilen entstandene Diakritika sind die griechischen SPIRITUS, die aus dem griechischen Eta (Hēta) 〈Η〉 entstanden sind: Der spiritus asper 〈῾〉 (griech. δασὺ πνεῦμα ,rauer Hauch‘), der einen [h]-Anlaut bezeichnet, wurde aus der linken Hälfte 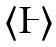 des Eta gebildet und der spiritus lenis 〈᾿〉 (griech. ψιλὸν πνεῦμα ,leichter Hauch‘), der etwas redundant einen vokalischen Anlaut ohne [h] bezeichnet, aus der rechten Hälfte 〈⫞〉. Diese Redundanz ist dadurch entstanden, dass die beiden von Aristophanes von Byzanz um 200 v. Chr. herum eingeführten Spiritus ursprünglich nur zur Desambiguierung eingesetzt werden sollten, z. B. von ὄρος / ˈoros/ ,Berg‘ und ὅρος / ˈhoros/ ,Grenze‘, damals in der Form 〈ΟΡΟΣ〉 vs. 〈ΟΡΟΣ〉 (vgl. Sturtevant 1937: 116).
des Eta gebildet und der spiritus lenis 〈᾿〉 (griech. ψιλὸν πνεῦμα ,leichter Hauch‘), der etwas redundant einen vokalischen Anlaut ohne [h] bezeichnet, aus der rechten Hälfte 〈⫞〉. Diese Redundanz ist dadurch entstanden, dass die beiden von Aristophanes von Byzanz um 200 v. Chr. herum eingeführten Spiritus ursprünglich nur zur Desambiguierung eingesetzt werden sollten, z. B. von ὄρος / ˈoros/ ,Berg‘ und ὅρος / ˈhoros/ ,Grenze‘, damals in der Form 〈ΟΡΟΣ〉 vs. 〈ΟΡΟΣ〉 (vgl. Sturtevant 1937: 116).
Die Entwicklung der ab dem 7. Jahrhundert vorkommenden e caudata 〈ę〉 (,geschwänztes e‘) hat schon Robert (1895: 634) recht zutreffend beschrieben: Dieses Graphem hat seinen Ursprung in der æ-Ligatur, die für klassisch-lateinisches ae geschrieben wurde. Während die in der heutigen Antiqua übliche Form |æ| recht weit von 〈ę〉 entfernt zu sein scheint, wurde die Ligatur im Mittelalter oft mit der ‚offenen‘ Form des 〈a〉 gebildet und sah daher beispielsweise so aus: 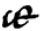 2. Das 〈a〉 ist hier also kaum mehr als eine Schlaufe, die mit der Zeit nach unten wanderte und zu Formen wie
2. Das 〈a〉 ist hier also kaum mehr als eine Schlaufe, die mit der Zeit nach unten wanderte und zu Formen wie 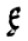 3führte. Zu dieser Verschiebung nach unten könnte beigetragen haben, dass für ae im Mittelalter auch häufig einfach nur 〈e〉 geschrieben und die CAUDA dann oft erst nachträglich, „mitunter wohl erst durch einen Leser“, hinzugefügt wurde (Stotz: 1996: 83, § 67.4) und oft eine sehr dünne Form annahm:
3führte. Zu dieser Verschiebung nach unten könnte beigetragen haben, dass für ae im Mittelalter auch häufig einfach nur 〈e〉 geschrieben und die CAUDA dann oft erst nachträglich, „mitunter wohl erst durch einen Leser“, hinzugefügt wurde (Stotz: 1996: 83, § 67.4) und oft eine sehr dünne Form annahm: 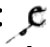 4. Für eine solche nachträgliche Korrektur war natürlich neben dem 〈e〉 kein Platz, so dass die 〈a〉-Schlaufe schon aus rein technischen Gründen unten angefügt werden musste. Danach lässt sich in den Handschriften und später auch Drucken beobachten, wie die Cauda weiter in die Mitte unter den Grundbuchstaben wandert und ihre heutige Form eines nach rechts offenen Bogens annimmt. So wird es möglich, sie am Ende des Grundbuchstabens anzusetzen und zeitsparend direkt in einem Zug mitzuschreiben.
4. Für eine solche nachträgliche Korrektur war natürlich neben dem 〈e〉 kein Platz, so dass die 〈a〉-Schlaufe schon aus rein technischen Gründen unten angefügt werden musste. Danach lässt sich in den Handschriften und später auch Drucken beobachten, wie die Cauda weiter in die Mitte unter den Grundbuchstaben wandert und ihre heutige Form eines nach rechts offenen Bogens annimmt. So wird es möglich, sie am Ende des Grundbuchstabens anzusetzen und zeitsparend direkt in einem Zug mitzuschreiben.
Aufgrund graphischer Ähnlichkeit wurde die Cauda bei der Einführung des Antiquadrucks in polnischer Sprache mit dem unter 3.2 erwähnten Strich für die Nasalvokale 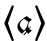 und
und 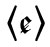 assoziiert (vgl. Bunčić 2012: 235 f.), so dass 〈ą〉 und 〈ę〉 dort seitdem (und z. B. auch im Litauischen) für Nasalvokale stehen und die Cauda in dieser neuen Funktion den polnischen Namen OGONEK (ebenfalls ,Schwänzchen‘) erhalten hat.
assoziiert (vgl. Bunčić 2012: 235 f.), so dass 〈ą〉 und 〈ę〉 dort seitdem (und z. B. auch im Litauischen) für Nasalvokale stehen und die Cauda in dieser neuen Funktion den polnischen Namen OGONEK (ebenfalls ,Schwänzchen‘) erhalten hat.
3.4 Diakritika aus Unterscheidungszeichen
Unterscheidungszeichen wurden bereits in Kapitel 2 angesprochen. Nötig werden sie u. a. durch Kursivierung und den zeitweiligen Vorrang ästhetischer Gesichtspunkte, die die Gleichförmigkeit einer Schrift und damit die Ähnlichkeit der einzelnen Grapheme als kalligraphisches Ideal fördern können, vor der Deutlichkeit der Schrift. So haben diverse mittelalterliche Buchschriften die senkrechten Schäfte betont, vor allem aber gotische Schriften ←21 | 22→wie die Textura (〈minimum〉 →  vgl. Abbildung 1). Das führte dazu, dass ein Unterscheidungszeichen auf dem 〈i〉 benutzt wurde, um den Text trotz der gotischen Ästhetik wieder lesbarer zu machen.5 Dieses Unterscheidungszeichen war zunächst häufig ein Strich (z. B.
vgl. Abbildung 1). Das führte dazu, dass ein Unterscheidungszeichen auf dem 〈i〉 benutzt wurde, um den Text trotz der gotischen Ästhetik wieder lesbarer zu machen.5 Dieses Unterscheidungszeichen war zunächst häufig ein Strich (z. B.  der als Nachahmung der Grundform des 〈i〉 erklärt werden kann, der dann aber auch zu einem Punkt vereinfacht werden konnte
der als Nachahmung der Grundform des 〈i〉 erklärt werden kann, der dann aber auch zu einem Punkt vereinfacht werden konnte  Die deutsche Kurrentschrift wäre ohne die Unterscheidungszeichen auf 〈i〉 und 〈u〉 gar nicht denkbar: vgl.
Die deutsche Kurrentschrift wäre ohne die Unterscheidungszeichen auf 〈i〉 und 〈u〉 gar nicht denkbar: vgl.  mit *|
mit *|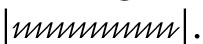
Details
- Seiten
- 260
- Erscheinungsjahr
- 2020
- ISBN (Paperback)
- 9783631819173
- ISBN (PDF)
- 9783631819944
- ISBN (ePUB)
- 9783631819951
- ISBN (MOBI)
- 9783631819968
- DOI
- 10.3726/b16862
- Sprache
- Deutsch
- Erscheinungsdatum
- 2020 (März)
- Schlagworte
- JungslavistInnen-Treffen Linguistik slavistische Linguistik slavische Philologie
- Erschienen
- Berlin, Bern, Bruxelles, New York, Oxford, Warszawa, Wien, 2020. 260 S., 31 s/w Abb., 12 Tab.
- Produktsicherheit
- Peter Lang Group AG
Biographische Angaben
Ivana Lederer (Band-Herausgeber:in)
Anna-Maria Meyer (Band-Herausgeber:in)
Katrin Schlund (Band-Herausgeber:in) ![]()
Ivana Lederer ist Lektorin für Bosnisch, Kroatisch und Serbisch an der Otto-Friedrich-Universität Bamberg. Sie promoviert an der Justus-Liebig-Universität Gießen. Ihre Forschungsschwerpunkte sind Varietätenlinguistik und Fremdsprachendidaktik. Anna-Maria Meyer promovierte in Bamberg zu slavischen Plansprachen und habilitiert sich in Köln zum Sprachkontakt Slavisch-Romani. Ein weiterer Forschungsschwerpunkt liegt in der Schriftlinguistik. Katrin Schlund habilitierte sich in Heidelberg mit einer Arbeit über unpersönliche Konstruktionen im Russischen. Weitere Schwerpunkte ihrer Forschung liegen im Bereich der interkulturellen Pragmatik und der kognitiven Grammatik.
