
Computergestützte Transkription arabisch-deutscher Gesprächsdaten
Ein methodischer Beitrag zur Untersuchung gedolmetschter Gespräche
Zusammenfassung
Leseprobe
Inhaltsverzeichnis
- Cover
- Titel
- Copyright
- Autorenangaben
- Über das Buch
- Zitierfähigkeit des eBooks
- Inhalt
- 1 Einleitung
- 1.1 Ausgangslage und Erkenntnisinteresse
- 1.2 Aufbau der Arbeit
- 1.3 Forschungsrahmen
- 1.4 Datenerhebung und TeDo-Korpus
- 1.5 Anmerkungen zur Terminologie
- 1.6 Transkriptionszeichen
- 2 Arabische Varietäten in verschrifteter Form: Querschnitt der Transkriptionspraktiken
- 2.1 Verhältnis zwischen Mündlichkeit und Schriftlichkeit im Arabischen: orthografische Möglichkeiten und Grenzen
- 2.2 Existierende Systeme zur Transkription arabischer Daten in Lateinschrift: von den Anfängen bis zur Gegenwart
- 2.2.1 Datentyp Text
- 2.2.2 Datentyp Gespräch
- 2.2.2.1 Computerlinguistische Transkriptionsverfahren
- 2.2.2.2 Soziolinguistische Transkriptionsverfahren
- 2.3 Zusammenfassung
- 3 Grundlegende Aspekte der gesprächsanalytischen Transkription
- 3.1 Von der Gesprochenen-Sprache-Forschung zur Gesprächsforschung: Rückblick auf die Geschichte der gesprächsanalytischen Transkription
- 3.2 Methodologische Grundlagen der gesprächsanalytischen Transkription
- 3.2.1 Annahme (1): Transkription als theorie- und zweckgeleitete Methode
- 3.2.2 Annahme (2): Transkription als situierte Forschungspraxis
- 3.2.3 Annahme (3): Transkription als selektives Vorgehen
- 3.2.4 Annahme (4): Transkription als subjektive Auswahl
- 3.2.5 Annahme (5): Transkription als interpretative und rekonstruktive Technik
- 3.2.6 Annahme (6): Transkription als bearbeitbare Rekonstruktion
- 3.2.7 Annahme (7): Transkription als modellierendes Verfahren
- 3.2.8 Zusammenfassung der Annahmen (1)–(7): Wissenschaftliche Transkription als reflektierte und offen zu reflektierende Praxis
- 3.3 Exkurs: Über konstitutive Gesprächsmerkmale
- 3.3.1 Mündlichkeit und Gesprochensprachlichkeit
- 3.3.2 Zeitlichkeit, Reziprozität, Synchronizität
- 3.3.3 Sequenzialität
- 3.3.4 Zusammenfassung
- 3.4 Fragestellungen zur Gesprächstranskription: ausgewählte Grundprobleme
- 3.4.1 Zeitlichkeit im Transkript
- 3.4.2 Gesprochensprachlichkeit als Verschriftungsproblem
- 3.5 Lösungen für ausgewählte Grundprobleme der Gesprächstranskription
- 3.5.1 Darstellung von Zeitlichkeit
- 3.5.2 Grafische Umsetzung von Gesprochensprachlichkeit
- 3.6 Transkriptionstools und Datenkuration
- 3.6.1 Transkriptionstools
- 3.6.2 Datenkuration
- 3.7 Zusammenfassung
- 4 Mehrsprachigkeit und Mehrschriftigkeit im Transkript: Grundlegende Herausforderungen bei der gesprächsanalytischen Aufbereitung von Dolmetschdaten mit arabischsprachigen Anteilen
- 4.1 Linksläufigkeit arabischer Schrift vs. Rechtsläufigkeit deutscher Schrift: Herausforderungen divergierender Schreibrichtungen für Transkriptionseditoren und Textverarbeitungsprogramme
- 4.1.1 Praktiken bei der Transkription von Dolmetsch-Interaktionen
- 4.1.2 Bidirektionalität in Partiturtranskripten: Fallbeispiel aus eigener Forschungspraxis
- 4.1.3 Unidirektionalität in Partiturtranskripten: Fallbeispiel aus eigener Forschungspraxis
- 4.2 Übersetzung arabischsprachiger Äußerungen im Transkript
- 4.2.1 Problemaufriss
- 4.2.2 Praktiken bei der zweisprachigen Wiedergabe arabischsprachiger Sequenzen aus Dolmetsch-Interaktionen
- 4.2.3 Grundsätzliche Fragen bei der Anfertigung einer gesprächsanalytischen Transkriptübersetzung
- 4.2.4 Übersetzung der arabischen Gesprächsbeiträge im TeDo-Korpus
- 4.3 Zusammenfassung
- 5 Entwurf einer gesprächsanalytisch motivierten Systematik zur computergestützten Transkription arabischsprachiger Gesprächsdaten
- 5.1 Konzept
- 5.2 Maximen
- 5.2.1 Lesbarkeit und Verständlichkeit
- 5.2.2 Einheitlichkeit
- 5.2.3 Authentizität
- 5.3 Phonetisch-orthografisches Transkriptionssystem für gesprochenes Arabisch
- 5.4 Ausgewählte Festlegungen
- 5.4.1 Lexikalisch-morphologische Ebene
- 5.4.1.1 Abweichende Transkriptionen identischer lexikalischer Einheiten
- 5.4.1.2 Getrennt- und Zusammenschreibung
- Zusammenschreibung mit grafischer Hervorhebung
- Zusammenschreibung ohne grafische Hervorhebung
- Getrenntschreibung
- 5.4.1.3 Groß- und Kleinschreibung
- 5.4.1.4 Hamza
- 5.4.2 Phonetisch-phonologische Ebene
- 5.4.2.1 Assimilationen
- 5.4.2.2 Dehnung
- 5.4.2.3 Emphase und Velarisierung
- 5.4.2.4 Gemination
- 5.4.2.5 Konsonantentrennung
- 5.4.2.6 Kürzung der langen Vokale
- Kennzeichnung von Vokalkürzung
- Nichtkennzeichnung von Vokalkürzung
- 5.4.2.7 Lautwandel der Konsonanten
- 5.4.2.8 Schmelzwörter (Kontraktion) und Tilgungen
- 5.4.2.9 Töne
- 5.4.3 Interaktionale Ebene
- 5.4.3.1 Interjektionen
- 5.4.3.2 Planungsindikatoren
- 5.4.3.3 Reparatur
- 5.4.3.4 Zögerungen
- 5.4.4 Festlegungen zur Interpunktion
- 5.4.5 Festlegungen zu Namen
- 5.5 Nutzungspotenzial des Transkriptionsverfahrens: Exemplarische Analyse eines Fallbeispiels aus dem TeDo-Korpus
- 6 Schlussbetrachtung
- 6.1 Zusammenfassung
- 6.2 Ausblick
- Anhang Ι Arbeitstranskript TeDo3 (Ausschnitt)
- Informationen zu Gespräch und Transkript
- Informationen zu den Sprechern
- Transkriptbeispiel
- Anhang ΙI Arbeitstranskript TeDo6 (Ausschnitt)
- Informationen zu Gespräch und Transkript
- Informationen zu den Sprechern
- Transkriptbeispiel
- Verzeichnis der Abbildungen und Tabellen
- Literaturverzeichnis
- Sachregister
1 Einleitung
1.1 Ausgangslage und Erkenntnisinteresse
Manch einer mag diese Erfahrung kennen: Man nimmt einen Text in die Hand, liest ihn, kann jedoch die offenbar lateinbasierte Schrift zunächst keiner bestimmten Sprache zuordnen. Wer sich mit mehrsprachigen Gesprächstranskripten beschäftigt, findet sich oftmals in einer ähnlichen Situation wieder. Man fragt sich beim Lesen solcher Transkripte bisweilen, wer da eigentlich mit wem und in welcher Sprache spricht. Liegt über das Transkript hinaus noch eine Übersetzung vor, könnte man als Durchschnittsleser1 eventuell über das rätselhafte Transkript hinwegsehen und sich vorerst mit der Übersetzung begnügen, selbst wenn die Frage, in welcher Sprache denn die übersetzten Sequenzen wohl ursprünglich formuliert worden sein mögen, weiterhin offenbleibt. Versucht man hingegen als Analytiker, Näheres zu erfahren, dann würde man sich wohl zunächst, sofern verfügbar, möglichst viele Informationen über die Gesprächssituation und die Gesprächsbeteiligten einholen. Was aber, wenn nun diese Metainformationen mit dem ersten Leseeindruck nicht übereinstimmen? Oder wenn das Transkript, trotz Kenntnis der Metainformationen, mehr Vages erahnen als Konkretes erkennen lässt? Vielleicht setzt man dann als Analytiker schlichtweg erneut mit prüfendem Auge zum Lesen an und konzentriert sich dabei auf die originalsprachigen Gesprächsbeiträge, bis sich Teile des Schriftbilds vielleicht nach mehrmaligem Lesen allmählich erschließen und man sich darüber im Klaren wird, dass die zunächst nicht zuordenbaren Teile offenbar Äußerungen in einer Sprache darstellen sollen, derer man eigentlich mächtig ist, was sich jedoch, wegen der Darstellung dieser Sprache in einer lateinbasierten Umschrift, nicht auf Anhieb feststellen ließ. So erging es jedenfalls der Verfasserin der vorliegenden Arbeit mehrmals, als sie zu gesprächsanalytischen Transkriptausschnitten in lateinschriftiger Fassung griff, die sich erst im Nachhinein, nach mehrmaligem Lesen und/oder nach Einholung von Metainformationen, als arabischsprachig identifizieren ließen. Interessanterweise trat der Verwirrungs- bzw. Verfremdungseffekt jedoch im Laufe der Zeit immer seltener und in stets schwächer werdender Form ein. Der Effekt scheint vor dem inzwischen trainierten Auge der Verfasserin heute überwindbar und die unmittelbaren Auswirkungen (z. B. auf die Verständlichkeit des Transkripts) sind bewältigbar geworden. Seine weitreichenden Auswirkungen (z. B. auf die Analysierbarkeit der Daten) sind allerdings, obwohl gewissermaßen voraussehbar, nach wie vor nicht verhinderbar – es sei denn, durch den Transkribenten selbst.
Gegenstand der vorliegenden Arbeit ist die lateinschriftige Transkription des gesprochenen Arabisch. Die langjährige und intensive Beschäftigung mit der Thematik geht auf forschungspraktische Erfordernisse an die gesprächsanalytische Untersuchung von empirisch gewonnenen Gesprächsdolmetschdaten mit arabischsprachigen Anteilen zurück. Die entsprechende Motivation erwuchs zunächst aus eigens ermittelten Grenzen bei der Aufbereitung dieser Daten und wurde dann während der wiederholten Auseinandersetzung mit arabischsprachigen Gesprächstranskripten (nicht nur von dolmetschvermittelten Settings) immer stärker, je öfter es dabei zur Aufdeckung methodischer Unzulänglichkeiten verbreiteter Praktiken kam, angefangen bei der Datenkonstitution, die eine untersuchungsgerechte Datenaufbereitung im konkreten Fall häufig behindert, bis hin zur Datendissemination, die, abgesehen von den untersuchungsspezifischen Anforderungen, mit den disziplinübergreifenden Entwicklungen – Stichwort Internationalisierung, wissenschaftliche Zusammenarbeit, Data Sharing, Open Science etc. – vielfach nicht mithalten kann.
Die Transkription natürlicher gedolmetschter Gesprächsdaten mittels computergestützter Verfahren ist ein integrales methodisches Instrument der linguistischen Gesprächsanalyse2 und seit vielen Jahren auch der interaktionsorientierten Dolmetschforschung (z. B. Amato/Spinolo/Rodríguez 2018; Arumí/Vargas-Urpi 2018; Angermeyer/Meyer/T. Schmidt 2012; Apfelbaum 2004, 2008; Bajrić 2014; Baraldi/Gavioli 2012; Bendazzoli 2017; Bolden 2000; S. Braun 2013, 2017; Davitti/S. Braun 2020; Bührig/Meyer 2014; Martini 2008; Meyer 1998, 2004; Niemants 2012; Pöllabauer 2005; Rivas-Carmona 2018; Salaets/Brône 2020). Angesichts der sprachlich-kulturellen Heterogenität in Europa und weltweit – im Zuge des Braingains, der Wirtschaftsmigration und der anhaltenden Fluchtbewegungen – wächst der Verständigungsbedarf in verschiedenen institutionellen Bereichen trotz bestehender Kommunikationsbarrieren, gleichzeitig wächst aber auch das Interesse an transkriptgeleiteten Analysen verschiedener kommunikativer Praktiken. Die Verfahren zur Erhebung und Konstitution der Daten (Elizitations-, Transkriptions- und gegebenenfalls Transkriptübersetzungsverfahren) werden jedoch nicht hinlänglich methodisch-methodologisch reflektiert und offengelegt. Dies betrifft auch mehrsprachige Transkripte, die unterschiedliche Schriftsysteme zusammenführen. Bei der kritischen Betrachtung verschiedener Transkriptbeispiele, mitunter in dolmetschwissenschaftlichen Beiträgen, wurde deutlich, dass mangelnde Reflexion und Transparentmachung der jeweiligen Vorgehensweise, speziell bei der Aufbereitung arabischsprachiger Sequenzen, nicht nur die Rezipierbarkeit der Transkripte und die Nachvollziehbarkeit der referierten Analyseergebnisse erschweren, sondern auch die Validität formulierter Schlussfolgerungen, ja sogar die Glaubwürdigkeit der gesamten Untersuchung gefährden, vor allem wenn arabischkundige Leser unkommentierte Widersprüche zwischen (teilweise) verständlichen Transkriptteilen und ihren Übersetzungen bemerken oder anderweitige Abweichungen von den Lesererwartungen unerklärt bleiben. Das Problem wird fatalerweise oft erst dann offenkundig, wenn der Verdacht aufkommt, dass Untersuchungen auf unsicherer Grundlage durchgeführt wurden, sprich wenn die Analyse nicht oder nicht ausschließlich auf Grundlage der originalsprachigen Sequenzen, sondern auf Grundlage ihrer (optimierten) Übersetzungen durchgeführt wird (s. Kap. 4). Sind wesentliche distinktive Prinzipien, wie methodische Diszipliniertheit, Explikation, Systematisierung, Eindeutigkeit, Einheitlichkeit, Präzision etc. (vgl. z. B. Deppermann 2007: 2), nicht stets erkennbar, lässt sich fragen, worin der analytische Mehrwert der Transkription eigentlich noch besteht. Denn Datentranskription dient zuvorderst der materiellen Fundierung interpretativer Forschung durch die intensive Auseinandersetzung mit Sprachdaten und nicht bloß der rekonstruktiven Fixierung flüchtiger akustischer Handlungen in einem grafischen Medium, der Beschreibung visueller Phänomene oder der Visualisierung interaktiver Prozesse, die allesamt ohnehin vielschichtigen Entscheidungen unterliegen.
Die vorliegende Arbeit stellt deshalb den Versuch dar, die Notwendigkeit eines reflektierten computergestützten Transkriptionsverfahrens aufzuzeigen. Hierzu werden wesentliche methodische Herausforderungen der Gesprächstranskription angesprochen. Die Zielsetzung basiert auf der These, dass die Verwendung der arabischen Schrift in einem mehrsprachigen, bidirektionalen Transkript bislang keine präzise Rekonstruktion (multimodaler) interaktiver Prozesse und zugrunde liegender zeitlicher Dimensionen (Reziprozität, Sequenzialität und Simultaneität sprachlichen Handelns) ermöglicht, deren Berücksichtigung bei interaktionsbezogenen Untersuchungen unentbehrlich ist. Eine adäquate Darstellung von Gesprächsdynamiken erfordert deswegen die Verwendung eines romanisierten, rechtsläufigen Schrifttyps zur Verschriftung arabischsprachiger Anteile im mehrsprachigen Transkript. Nun stellt sich zwangsläufig die Frage nach der Wahl eines geeigneten Umschriftsystems. Die Verschriftung des gesprochenen Arabisch ist aufgrund der kaum konventionalisierten Schreibung standardferner Varietäten und der unzureichenden Beschäftigung mit sprechsprachlichen Phänomenen (z. B. Diskursmarker, Interjektionen, Verzögerungslaute etc.) schwierig. Die im deutsch- und englischsprachigen Raum bewährten Umschriftsysteme orientieren sich primär an der Standardlautung und -schreibung und sind somit auf die Wiedergabe der Geschriebensprachlichkeit zugeschnitten. Gesprochensprachlichkeit ist hingegen vorwiegend Gegenstand phonologischer Umschriftsysteme, die in erster Linie jedoch phonetisch motivierten (z. B. dialektologischen, varietätenlinguistischen) Fragestellungen gerecht werden. Insofern ist die Entwicklung einer lateinschriftigen Systematik zur stärker orthografischen Transkription arabisch-deutscher Gespräche weiterhin ein Desiderat der gesprächsanalytischen Forschung und der Aufbau eines arabisch-deutschen Gesprächsdolmetschkorpus ein Desiderat der interaktionsorientierten Dolmetschforschung. Diese Arbeit setzt sich somit zum Ziel, an die bewährten arabistischen Umschriftsysteme anzuknüpfen, zugleich aber gesprächsanalytisch motivierte Akzente zu setzen, um eine sogenannte literarische Umschrift des gesprochenen Arabisch zu entwerfen. Sie baut auf Farag (2019a, b; 2021) und Farag/Meyer (2022) auf.
Ein besonderes Ziel der computergestützten Transkription ist darüber hinaus, die nachhaltige Zugänglichkeit, Vorhaltung und Nachnutzung der digital gespeicherten und aufbereiteten Gesprächsdaten für anderweitige Lehr- und Forschungszwecke zu ermöglichen und ihre Eingliederung als multimediale Sprachressource in eine digitale Forschungsinfrastruktur zu erleichtern. Durch die Entwicklung einer Systematik zur romanisierten Schreibung und zur Übersetzung der Gesprächsdaten wird ihre Opazität für Leser ohne Arabischkenntnisse reduziert und ansatzweise eine Lesbarkeit auch für Arabischunkundige geschaffen. Die Transparentmachung dieser Systematik ist für die Datenkuratierung und etwaige Nachnutzungen von besonderer Bedeutung. Mit Blick auf die sich wandelnden Arbeitsumgebungen sowie den fulminanten Aufstieg virtueller und hybrider Verständigungsmedien und die damit einhergehenden Änderungen in den Kommunikationsformen, wie im Fall des Ferndolmetschens, ist mit einem steigenden Bedarf an wissenschaftlicher Zusammenarbeit sowie an längerfristig und länderübergreifend zugänglichen und interdisziplinär nachnutzbaren Sprachkorpora zu rechnen, nicht zuletzt infolge der Anfang 2020 ausgebrochenen Covid-19-Pandemie, der damit verbundenen Reisebeschränkungen und der zusätzlich erschwerten Bedingungen zur Erhebung authentischen Datenmaterials.
Die empirische Grundlage der Arbeit bilden zwar dolmetschgestützte Beratungsgespräche per Telefon (Kap. 1.4), die entwickelte Systematik zur Transkription und auch zur Übersetzung richtet sich aber allgemein an wissenschaftliche Transkribenten, die mehrsprachige Interaktionsprozesse in ein schriftbasiertes Medium (ohne Einbußen bei der Kennzeichnung zeitlicher Bezüge) überführen möchten und sich vor die Aufgabe gestellt sehen, gesprochenes Arabisch-in-Interaktion, so gebührend und authentisch wie analytisch erforderlich, in ein mehrsprachiges Format zu integrieren und es dabei arabischunkundigen sowie varietätenunkundigen Lesern durch eine Übersetzung verständlich zu machen, deren Zustandekommen sich anhand des jeweils in Lateinschrift dargestellten ausgangssprachigen Beitrags jederzeit nachvollziehen ließe.
Darüber hinaus dürften die analysierten Beispiele die Aufmerksamkeit von dolmetschwissenschaftlich interessierten Linguisten bzw. gesprächslinguistisch interessierten Dolmetschwissenschaftlern wecken, die sich einen Einblick in sprachlich-kommunikative Besonderheiten des Telefondolmetschens verschaffen möchten.
Des Weiteren könnte diese Arbeit für Studierende nützlich sein, die mehr über die Eigenheiten der Verschriftung des Arabischen in einer lateinbasierten Umschrift und über etablierte Transkriptionspraktiken in verschiedenen Disziplinen (Computerlinguistik, Soziolinguistik) erfahren oder sprachübergreifend in die Grundlagen der computergestützten gesprächsanalytischen Transkription eingeführt werden möchten.
1.2 Aufbau der Arbeit
Die Arbeit ist in sechs Kapitel gegliedert. Kapitel 2 gibt einen Überblick über eine Reihe von etablierten Praktiken bei der lateinschriftigen Wiedergabe arabischer Daten, um das unbedingte Bedürfnis nach einem gesprächsanalytischen Transkriptionssystem für gesprochenes Arabisch und allgemein nach einer regelbasierten romanisierten Schreibung bei mehrsprachigen Verfahren abzuleiten. Zur Präzision handlungsleitender Anforderungen widmet sich Kapitel 3 ausgewählten Grundproblemen der computergestützten linguistischen Gesprächstranskription sowie sprachübergreifenden Lösungswegen und weist abschließend auf aktuelle Ansprüche an die Qualitätssicherung von Transkriptionsprozessen zur Erhöhung ihres Nachnutzungswerts und bei anderweitigem Forschungsdatenmanagement hin. Die in Kapitel 3 behandelten Aspekte sollen also die Komplexität der Fragestellung verdeutlichen, damit der methodologisch-methodische Rahmen für die Entwicklung einer Umschrift geschaffen werden kann. Kapitel 4 lenkt das Augenmerk zurück auf die Transkription arabischsprachiger Daten und schildert wesentliche Herausforderungen bei der Bewältigung von Mehrsprachigkeit und Mehrschriftigkeit im Transkript. Dabei werden Forschungspraktiken bei der Aufbereitung arabischsprachiger Dolmetschdaten auf ihre Eignung hin diskutiert und in verschiedener Hinsicht allgemein problematisiert. Daran anschließend wird eine zu gesprächsanalytischen Zwecken dokumentierte Systematik einer lateinschriftigen Transkription vorgestellt, deren Nutzen und Grenzen dann an entsprechend transkribierten Daten aus dem Telefondolmetschkorpus erörtert werden. Die Arbeit schließt mit Kapitel 6, in dem der eingeschlagene Weg zur Entwicklung der Umschrift zusammenfassend dargelegt wird, ehe abschließend ein Ausblick auf weiterführende Fragestellungen sowie auf forschungspraktische Empfehlungen erfolgt.
Zunächst soll jedoch der Forschungsrahmen und die Datenerhebung skizziert werden, um die Anforderungen an deren Erschließung zu verdeutlichen und anschließend den Hintergrund der Ausarbeitung der Umschrift zu erhellen.
1.3 Forschungsrahmen
Die in dieser Arbeit aufbereiteten Daten stammen aus dem im Aufbau befindlichen Korpus des DFG-Projekts „Turn-Taking und Verständnissicherung beim Telefondolmetschen Arabisch-Deutsch“ (TeDo), das seit 2019 am Fachbereich Translations-, Sprach- und Kulturwissenschaft (Arbeitsbereich Interkulturelle Kommunikation) der Johannes Gutenberg-Universität Mainz unter der Leitung von Univ.-Prof. Dr. Bernd Meyer durchgeführt wird. Im Rahmen des Forschungsprojekts wird der Frage nachgegangen, welche sprachlich-kommunikativen Verfahren die dolmetschenden Personen in telefonisch hergestellten Dolmetsch-Interaktionen nutzen, um die mangelnde Kopräsenz des Telefondolmetschers mit den primären Gesprächsbeteiligten zu kompensieren. Der Einsatz von Informations- und Kommunikationstechnologien, wie dem Telefon, ermöglicht nämlich ortsunabhängige Dolmetschleistungen. Gerade in der Kommunikation mit Geflüchteten ist das Telefondolmetschen, aufgrund mangelnder Alternativen, eine verbreitete Praxis in Unterkünften und Betreuungs- sowie Beratungskontexten (vgl. z. B. Cnyrim 2017, 2020). In dolmetschgestützten Gesprächen geht die Präsenz einer dritten Partei, der dolmetschenden Person, grundsätzlich mit zusätzlichen kommunikativen Herausforderungen einher. Der Umgang mit Sprachbarrieren und Wissensdivergenzen erfordert zusätzliche koordinierende Handlungen, die über die herkömmlichen Verfahren der Gesprächsorganisation hinausgehen (vgl. z. B. Baraldi/Gavioli 2012). Erwähnt seien beispielsweise inhaltsbezogene Redezüge, wie etwa Reformulierungen und Nachfragen bei Verstehensproblemen3, sowie Handlungen, die einen geordneten Verlauf des Gesprächs ermöglichen sollen, wie etwa die explizite oder implizite Turnzuweisung.
Bei telefonisch erbrachten Verdolmetschungen stellt sich die Frage, wie die Beteiligten den Sprecherwechsel und die Bearbeitung von Kommunikations- bzw. Verständigungsbrüchen bewältigen. Während die Beteiligten in Face-to-Face-Interaktionen für die Gesprächskoordination meist verschiedene Ausdrucksmodalitäten nutzen, die aufgrund der räumlichen und visuellen Kopräsenz verfügbar sind, wie etwa Interjektionen und Rückmeldungen (back-channels) und/oder mimische und gestische Ressourcen (cues), stehen diese Ressourcen in telefonisch gedolmetschten Gesprächen nicht im gleichen Maße zur Verfügung. Ungeklärt ist bisher, wie koordinierende Handlungen beim Telefondolmetschen von den Beteiligten gemeinsam gestaltet werden, wenn visuelle und akustische Wahrnehmungsmöglichkeiten nicht oder nur begrenzt bestehen. Zu den koordinierenden Handlungen zählt beispielsweise die fortlaufende Aushandlung von Sprecher- und Hörerrollen (Turn-Taking) und die Bewältigung von gesprächsorganisatorischen Problemen wie simultanem Sprechen (Überlappung) und gegenseitigen Unterbrechungen. Neben den formalen, gesprächsaufrechterhaltenden Aspekten richtet sich das Augenmerk der Untersuchung auch auf koordinierende Handlungen inhaltlicher Natur, die der Telefondolmetscher zur vorbeugenden oder reparierenden Bearbeitung von potenziellen und manifesten Verständigungsschwierigkeiten unternimmt, zum Beispiel durch Wiederholungen und Erläuterungen (Birkner/Ehmer 2013) oder Reformulierungen (Bührig 1996) und weitere adressatenorientierte, dem Kommunikationszweck adäquat dienende Verfahren. Diese Aufgaben erwachsen dem Telefondolmetscher aus dem besonderen Teilnehmerstatus als involved actor (Wadensjö 1992) bzw. full-scale participant (Roy 2000) – trotz des eingeschränkten Zugangs zum Geschehen am anderen Ende der Leitung. Verstehen wird in diesem Zusammenhang nicht als psychisch-kognitiver Prozess, sondern als interaktionaler Vorgang analysiert, der von den Beteiligten gestaltet wird. In diesem Sinne wird Verständigung als Aushandlungsprozess begriffen, in dem Sprecher und Hörer sich wechselseitig sinnvolles Handeln unterstellen und nur in bestimmten Fällen mentale Verarbeitungsprozesse und -probleme explizit versprachlichen und thematisieren (z. B. Deppermann 2010, 2013a; Deppermann/R. Schmitt 2008; Kameyama 2004; Mondada 2011).
Im Gegensatz zum herkömmlichen Gesprächsdolmetschen von Angesicht zu Angesicht wohnen diesen besonderen Umständen, abgesehen von den räumlichen Verhältnissen, latente Quellen zur Entstehung und/oder Verstärkung von Verständnisproblemen inne. Hierzu zählen unter anderem (1) jegliche Störungen im Telefonnetz und (2) weitere technisch und situativ nicht antizipierbare oder schwer behebbare Beeinträchtigungen (z. B. Übertönungen, Hintergrundgeräusche und Lautstärkeschwankungen) sowie (3) die (fast immer) unterschiedlichen regionalen Varietäten bei Klient und Dolmetscher, deren Auswirkungen auf die Verständigung offenbar am Telefon, vor allem bei mangelnder kommunikativer Reichweite der sprachlichen Äußerungen (s. Kap. 2.1), ohne unterstützende visuelle Eindrücke, beispielsweise in Form von Lippenbewegungen, verstärkt werden können, weshalb sie in den Transkripten entsprechend erkennbar sein müssen. Die Aufbereitung der Daten in Form von Transkripten ermöglicht eine genauere qualitative, interpretativ-rekonstruktive Analyse der multimodalen Verfahren4, mit deren Hilfe diese potenziellen Störquellen von den Interaktanten jeweils bearbeitet wurden, zugleich aber auch eine Lokalisierung und Quantifizierung verschiedener Phänomene durch korpusgestützte Auswertung. Zur Erfüllung der formulierten Untersuchungsziele mussten – vor dem Hintergrund der Pluriglossie bzw. der Varietätenvielfalt im Arabischen sowie des Phänomenreichtums im mündlichen Sprachgebrauch und der Probleme der mehrschriftigen Transkription des Arabischen – stringente, gesprächsanalytisch fundierte Transkriptionskonventionen für gesprochenes Arabisch in seinen im Korpus auftretenden Regionalvarietäten (Ägyptisch, Jemenitisch, Libysch, Marokkanisch und Syrisch) ausgearbeitet und erprobt werden.
1.4 Datenerhebung und TeDo-Korpus
Die Untersuchung wird anhand von dolmetschgestützten Beratungsgesprächen5 zu asylbezogenen Themen im Sprachenpaar Arabisch-Deutsch durchgeführt. Die Dolmetscher wurden telefonisch zugeschaltet und konnten nur auditiv mit den Klienten und Beratern interagieren, die sich wiederum, sozusagen „physisch kopräsent“, jeweils in einem Zimmer befanden (telephone-based interpreting). Die Verfasserin entwickelte ein geeignetes Erhebungssetting und stellte den Feldzugang inklusive der Anwerbung von Studienteilnehmern (Berater, Dolmetscher, Klienten) her.
Erhoben wurden zwölf Gespräche zwischen Arabisch sprechenden Klienten ohne bzw. mit geringen Deutschkenntnissen und Deutsch sprechenden Sozial- bzw. Jugendmigrationsberatern (kommunale Verweisberatung), zu denen ein Dolmetscher per Telefon herangezogen wurde. Klienten und Berater nahmen die Verdolmetschung über einen Lautsprecher akustisch wahr (s. Abb. 1). Die Klienten waren Geflüchtete (überwiegend aus Syrien) mit authentischen Beratungsanliegen zu allgemeinen asylbezogenen Themen wie Familiennachzug, Arbeitssuche und Spracherwerb. Das Datenmaterial kann als quasi-authentisch bezeichnet werden, da seitens der Verfasserin (in ihrer Funktion als Erheberin der Daten) lediglich das Zustandekommen der Gespräche bewirkt wurde (Terminkoordination, Zusammenführung geeigneter Probanden, Bereitstellung der Dolmetscher). Die beteiligten Dolmetscher, überwiegend beeidigt, verfügten über einen einschlägigen Hochschulabschluss und eine mehrjährige Berufserfahrung, jedoch nicht oder nur geringfügig in Remote-Situationen. Um über die sozialen Umstände der Flucht, die betroffenen Rechtsgebiete und Zuständigkeitsbereiche sowie die erwünschten Integrationsmaßnahmen (Beschäftigung, Sprachförderung, Schulbesuch) sprechen zu können, wurde in den meisten Gesprächen eine durchgehende Verdolmetschung benötigt. Die Gespräche wurden mit einem digitalen Aufzeichnungsgerät (TASCAM DR-05) aufgezeichnet, Berater und Klienten mit einer Videokamera (Sony CX405 Handycam) aus der Halbnahen aufgenommen, der Dolmetscher mit zwei Videokameras aus der Halbtotalen und der Nahen (s. Abb. 1).
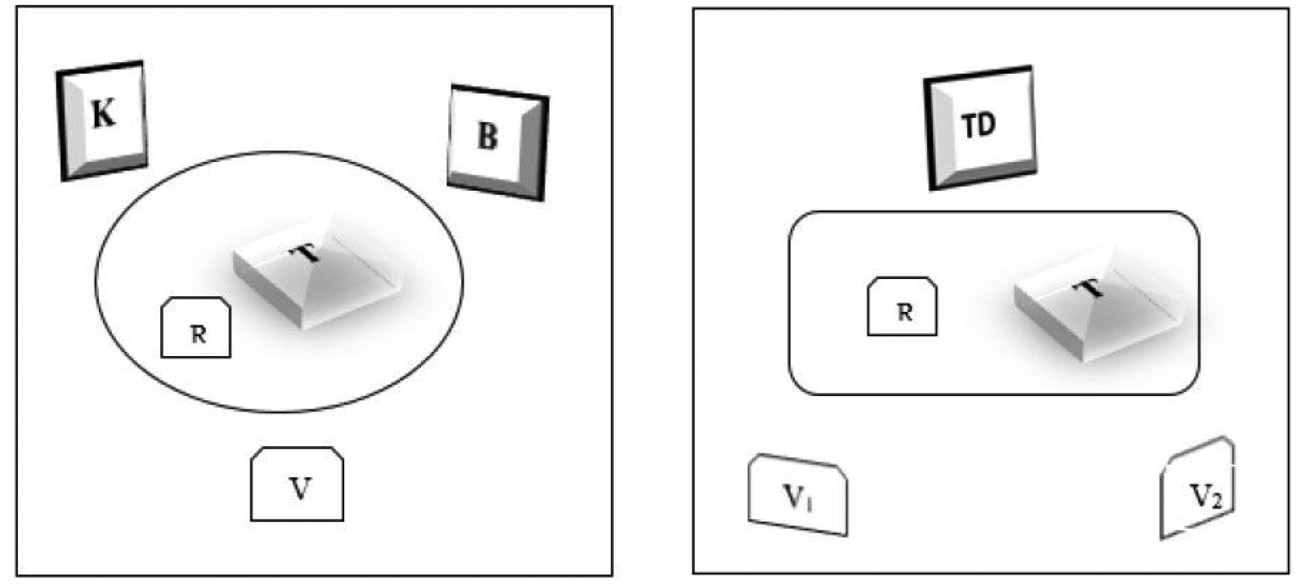
Abb. 1:Aufzeichnungssetting in Split-Screen-Ansicht, räumliche Anordnung des Beratungs- (links) und des Dolmetscherzimmers (rechts)6
Der in dieser Situation als Datenerheberin fungierenden Verfasserin war be-wusst, dass ihre Präsenz im Beratungszimmer oder die Gegenwart der Kameras, selbst ohne die Präsenz einer aufzeichnenden Person im Dolmetscherzimmer, die Interaktion mehr oder weniger stark beeinflusst haben. Roy (2000: 48) räumt diesbezüglich allerdings ein, dass die Interaktion in der Regel die Aufmerksamkeit der Beteiligten dermaßen stark beansprucht, dass sie nach einiger Zeit den Beobachter im Raum nicht mehr wahrnehmen.7 Bei der erhobenen Situation gab ihnen allerdings der Konsekutivmodus immer wieder Anlass, sich an die Präsenz der Aufzeichnungsgeräte und der Datenerheberin zu erinnern. Da die zu erforschenden Phänomenbereiche, trotz kalkulierten Handelns, nicht übermäßig stark kontrolliert werden können, wird bei der Analyse die durch das Setting (Präsenz von Datenerheberin und Aufzeichnungsgeräten) motivierte Inszenierung(squalität) der Handlungen prinzipiell außer Acht gelassen und nur im Einzelfall berücksichtigt. Die Beteiligten wurden zwei Mal mündlich über den Forschungszusammenhang der Aufzeichnungen grob unterrichtet, und zwar bei der Vorbereitung des Termins und direkt vor Beginn des Gesprächs. Dabei wurde nur allgemein von der Erforschung der Besonderheiten des Telefondolmetschens gesprochen. Die zu besprechenden Themen wurden nicht vorab abgesprochen. Alle Gesprächsteilnehmer haben schriftlich in die Verwendung der Aufzeichnungen zu wissenschaftlichen Zwecken eingewilligt.
Alle Audioaufzeichnungen (sowohl vom Beratungs- als auch vom Dolmetscherzimmer) wurden transkribiert. Arabischsprachige Sequenzen wurden ins Deutsche und auszugsweise zu Präsentationszwecken auch ins Englische übersetzt. Eine Auswahl exemplarischer Arbeitstranskripte befindet sich im Anhang. Die Videoaufzeichnungen werden unterstützend zur Transkription hinzugezogen, denn sie machen es möglich, Handlungen der Beteiligten zu erschließen, die in den Audioaufzeichnungen nicht eindeutig zuordenbar sind, sowie weitere nicht akustisch wahrnehmbare Handlungen zu ermitteln, die für den/die anderen Gesprächsteilnehmer im jeweils anderen Zimmer nicht sichtbar sind (s. Kap. 4.1.3 und 5.5). Beschreibungen nonverbaler Handlungen werden aus pragmatischen Gründen bei der Analyse auszugsweise an untersuchungsrelevanten Stellen ergänzt.
Details
- Seiten
- 406
- Erscheinungsjahr
- 2023
- ISBN (PDF)
- 9783631883198
- ISBN (ePUB)
- 9783631883204
- ISBN (Hardcover)
- 9783631883181
- DOI
- 10.3726/b20257
- Open Access
- CC-BY
- Sprache
- Deutsch
- Erscheinungsdatum
- 2024 (Februar)
- Schlagworte
- Mehrsprachige Daten Mehrschriftigkeit Gesprochenes Arabisch Varietätenvielfalt Literarische Umschrift Zeitlichkeit Transkriptübersetzung Telefondolmetschen Datenkuration Bidirektionalität DMG-Umschrift
- Erschienen
- Berlin, Bruxelles, Chennai, Lausanne, New York, Oxford, 2023. 406 S., 47 farb. Abb., 33 s/w Abb., 5 Tab.
- Produktsicherheit
- Peter Lang Group AG
Biographische Angaben
Rahaf Farag (Autor:in) ![]()
Rahaf Farag ist wissenschaftliche Mitarbeiterin im Projekt Spracherhebung und -dokumentation der Abteilung Zentrale Forschung am Leibniz-Institut für Deutsche Sprache in Mannheim. Zuvor forschte und lehrte sie am Arbeitsbereich Interkulturelle Kommunikation des Fachbereichs Translations-, Sprach- und Kulturwissenschaft (FTSK) der Johannes Gutenberg-Universität Mainz in Germersheim, wo sie auch promoviert wurde. Ihre Forschungsinteressen umfassen Mehrsprachigkeit, interkulturelle Öffnung und Kommunikation in Institutionen, Dolmetschen und Übersetzen in Theorie und Praxis sowie methodische Fragen der Angewandten Linguistik und Gesprächsanalyse.
