
Language, Corpora and Cognition
Summary
Excerpt
Table Of Contents
- Cover
- Title
- Copyright
- About the author
- About the book
- This eBook can be cited
- Table of Contents
- Introduction (Piotr Pęzik and Jacek Waliński)
- Gradience in cognitive scanning: participle modifiers in Polish and English (Barbara Lewandowska-Tomaszczyk)
- Experimental applications of dependency-based phraseology extraction (Piotr Pęzik)
- Computational distributional semantics and free associations: a comparison of two word-similarity models in a study of synonyms and lexical variants (Marcin Tatjewski, Mirosław Bańko, Adrianna Kucińska and Joanna Rączaszek-Leonardi)
- Grammars or corpora? Who should we trust? Empirical analysis of morphological doubletism in Croatian (Dario Lečić)
- Figurative dimensions of health:a corpus-illustrated study (Adamina Korwin-Szymanowska and Jacek Tadeusz Waliński)
- “Justice with an attitude?” – towards a corpus-based description of evaluative phraseology in judicial discourse (Stanisław Goźdź-Roszkowski)
- Using time to express remoteness in space: A corpus-based study of distance representations for motion medium in the National Corpus of Polish (Jacek Tadeusz Waliński)
- Avenues for Research on Informal Spoken Czech Based on Available Corpora (Petra Klimešová, Zuzana Komrsková, Marie Kopřivová and David Lukeš)
- Introducing a corpus of non-native Czech with automatic annotation (Alexandr Rosen)
- Corpus-based Analysis of Czech Units Expressing Mental States and Their Polish Equivalents Identification of Meaning and Establishing Polish Equivalents Referring to Different Theories (Elżbieta Kaczmarska)
- Problem solving in English and Polish: A cognitive corpus-based study of selected metaphorical conceptualizations (Marcin Trojszczak)
- Corpus Linguistics for Critical Discourse Analysis. What can we do better? (Victoria Kamasa)
- Towards quantitative and qualitative characterisation of various types of dialogue: interviews vs. Panel Discussions (Dorota Pierścińska)
- Standardisation in safety data sheets? A corpus-assisted study into the problems of translating safety documents (Aleksandra Beata Makowska)
- Lexical bundles in English medical texts (Monika Betyna)
Piotr Pęzik and Jacek Waliński
The idea of this volume was conceived during the 9th international conference on Practical Applications of Language Corpora (PALC 2014), held at the University of Łódź, Łódź, Poland, 20–22 November 2014, which was accompanied by a special workshop devoted to Uncovering Time in Language. This is where most of papers originate from, although some contributions in the volume, most notably three final papers from young researchers, were invited at a later stage. At present, linguists support different assumptions about the faculty of language, and they adopt a broad spectrum of methodologies for research on linguistic phenomena. This volume presents a selection of studies that reflect a growing interest in matching theoretical predictions about language and cognition against empirical language data with the use of corpus linguistics methodology.
Throughout the editing process we have incurred a number of debts that we wish to acknowledge. First of all we appreciate the invaluable assistance from Barbara Lewandowska-Tomaszczyk, the founding mother of PALC conferences and, more recently, the principal investigator of the project on Perception of Time as a Linguistic Category, which provided financial support for the publication of this book. Hereby we acknowledge that this publication was carried out and supported with the Polish National Science Centre (Narodowe Centrum Nauki) project Perception of Time as a Linguistic Category, No. 2011/01/M/HS2/03042.
We gratefully acknowledge the assistance of Anna Bączkowska from the Kazimierz Wielki University in Bydgoszcz, who reviewed the papers submitted for publication. Her critical insights and helpful comments greatly improved the value of the volume as a whole. Our sincere thanks also go to all individual contributing authors, who responded with utmost professionalism to all requests that were made of them, and patiently waited for the publishing process to finalize.
The present volume contains 15 papers. In the opening chapter, Barbara Lewandowska-Tomaszczyk seeks an explanation for the regular patterns of pre- and post-modifying participial constructions in Polish and English. The differences observed in the reference corpora are linked to the aspectual systems of the two languages, and more specifically, to the partially gradient nature of the cognitive scanning processes in Polish, which is not attested in the English data.
Piotr Pęzik proposes a dependency-based method of extracting phraseological units from corpus search results. The approach makes use of automatic dependency ← 7 | 8 → annotations. Its potential novelty lies in the improved ability to identify “collocational catenae”, which are recurrent dependency subtrees composed of more than two lexical items which seem to have acquired some phraseological status. The results of automatic phraseology extraction are claimed to have theoretical implications, as they bring insights into the interplay of compositionality and prefabrication in language production and reception.
In the third chapter of the volume, Marcin Tatjewski, Mirosław Bańko, Adriana Kucińska and Joanna Rączaszek Leonardi combine two different methodologies of measuring word similarity. A corpus-based, distributional model is compared with the results of a survey in which informants provide free associations of selected words. The correlation observed between the results obtained with these two methods gives some weight to the assumption that corpus and experimental data can be exploited in tandem to explore the cognitive aspects of language use.
Dario Lečić uses a similar combination of corpus- and survey-based data to explore the phenomenon of morphological doubletism in Croatian. The specific question addressed in his chapter is whether corpora provide a more accurate description of native speakers’ morphological preferences than formal grammars of Croatian. He finds that although the relative proportions in the frequencies of the doubled forms are generally reflected in the survey, phonologically similar forms are much less consistent with their corpus distributions.
Taking into account data found in the British National Corpus and the Corpus of Contemporary American English, Adamina Korwin-Szymanowska and Jacek Waliński discuss a conceptual mapping of health as the general condition of human functioning onto two basic dimensions of embodied experience involving UP–DOWN and STRONG–WEAK scales. From this perspective the concept of health forms an array of primary conceptual metaphors arising from the cognitive embodiment.
Stanisław Goźdź-Roszkowski’s paper investigates the role of selected grammatical patterns in expressions of evaluative meanings found in a corpus of US Supreme Court opinions. Using the concept of Local Grammar and evidence from this corpus, the author identifies and systematizes the conventional ways in which the judges signal their attitudes and how they relate them to those of relevant interactants in their written opinions. The patterns selected for the analysis turn out to serve their prototypical evaluative functions.
In the subsequent chapter, Jacek Waliński demonstrates a proportion between spatial and temporal expressions of distance for the semantic attribute of motion medium based on objectively verifiable frequencies of language patterns found in the National Corpus of Polish. His research shows that in this particular semantic context Polish speakers tend to express distance both in spatial and temporal terms, with spatial representations being used more frequently, but not by a large margin. ← 8 | 9 →
Petra Klimešová, Zuzana Komrsková, Marie Kopřivová and David Lukeš describe a number of distinctive features of casual spoken discourse which set it apart from written and formal spoken language. Corpora of informal conversational discourse are presented as an invaluable source of data without which it would be impossible to systematically study discursive, phonetic and grammatical phenomena in spoken language.
In the next chapter in this volume, Alexandr Rosen introduces a corpus of essays composed by non-native Czech authors. The specific challenge addressed in this paper concerns the automatic annotation of non-native language data. The author shows that part-of-speech taggers and lemmatizers originally developed for native Czech can be adopted to generate useful linguistic annotations of the corpus of non-native writing.
Elżbieta Kaczmarska’s paper focuses on a selection of polysemous mental state verbs in Czech. Using a parallel corpus, she extracts clusters of their Polish equivalents and investigates the extent to which they can be predicted by different linguistic frameworks.
Marcin Trojszczak presents selected aspects of metaphorical conceptualization of problem solving that are shared between English and Polish on the basis of linguistic data from the British National Corpus and the National Corpus of Polish. He approaches metaphorical conceptualizations of problem solving from the perspective of cognitive corpus-based linguistics.
Victoria Kamasa critically reviews a number of papers whose authors use Corpus Linguistics techniques in Critical Discourse Analysis and identifies some the most vulnerable points of the current research practice. She also suggests improvements for corpus-supported discourse analysis which can help researchers avoid many methodological pitfalls.
The last three papers in the volume are corpus-based studies contributed by young researchers working on their doctoral dissertations. Dorota Pierścińska discusses quantitative parameters of dialogue in interviews and panel discussions and relates these two genres to the qualitative features in order to develop and propose their general characterisation. Aleksandra Makowska looks at a corpus of industrial safety sheets and points out possible improvements in their translation and terminological standardisation. Monika Betyna investigates the functions of lexical bundles in a topic-oriented corpus of medical texts. ← 9 | 10 →
Barbara Lewandowska-Tomaszczyk
State University of Social Sciences in Konin
Gradience in cognitive scanning: participle modifiers in Polish and English
Abstract: The main issue to be discussed in the present paper is gradience in the cognitive scanning processes of events described in terms of de-verbalized categories in Polish and English, used in sentences as weakly-grounded or non-grounded forms with decreasing assertive force. In such constructions the event represented by the modifier is either more fully attributivized and used pre-nominally or left in its more verbal shape, frequently following the relevant nominal. The profiles involve a number of relevant parameters and the position of the modifier with respect to the modified noun and the presence of the complementary sentence elements are also demonstrated to be relevant indicators of the particular construal parameters. The language data are drawn from the British National Corpus and the National Corpus of Polish. Distinct language profiles in this respect are demonstrated to pertain first of all to different aspectual systems in the two languages and embrace in particular pre-/post-modification behaviour of the relevant constructions, which are argued to be rooted in the partial gradience nature of the scanning processes in Polish, as compared to English.
Keywords: aspect, attribute, British National Corpus, construal, (co-)temporality, distribution, event, frequency, gerund, gradience, modification, National Corpus of Polish, participle, scanning, sentence position, tense, verb
Background assumptions1
The basic assumption of Cognitive Linguistics is that the subject of the analysis is a relationship between objects and events not as they are in the real world but rather the conceptualization of the relationships between objects, events and their participants. Furthermore, language specific syntactic structures function as vehicles which convey the speaker’s conceptualization of an outside scene or event.
The main focus of the present paper is the phenomenon of graded cognitive scanning in the conceptualization of events described in terms of de-verbalized categories in Polish and English, used in sentences as weakly-grounded or non-grounded forms with decreasing assertive force. Their distinct language profiles in ← 11 | 12 → this respect are demonstrated to pertain first of all to the distinct aspectual systems in the two languages and embrace in particular pre-/post-modification behaviour of the relevant constructions, which are argued to be rooted in the gradience of the scanning processes in Polish, as compared to English.
In such constructions an event represented by the modifier is either more fully attributivized and used pre-nominally or left in its more verbal shape, frequently following the relevant nominal. The profiles involve a number of parameters, and the position of the modifier with respect to the modified noun and the presence of the complementary sentence elements are demonstrated to be relevant indicators of the particular construal parameters.
The concept of cross-language equivalence adopted here is discussed in terms of an overall framework embracing an Event structure as well as reference grammatical categories such as primarily Tense and Aspect interpreted in the form of basic image-schemata and their extensions as well as the construal relations distinct in Polish and English. Time, underlying Tense and Aspect on the other hand, in its ‘real’ sense, as argued in Lewandowska-Tomaszczyk (2016: xix) is probably a subjective experience type, as called by Grady (1997), possibly modality-based, more individual than space, and is considered to be, as shown in Edelman et al.(2012), Evans (2013) and other researchers, phenomenologically real, although its conceptualizations may differ across cultures and individuals.
1. Materials
The language materials used in the study are drawn from the British National Corpus and the National Corpus of Polish and both quantitative data (frequencies) for particular forms and their distribution as well as their qualitative properties, referring to language-specific rules of event type and event phase expression, are considered.
2. Cognitive Linguistic concepts relevant to the analysis
2.1 Construal
A typical event scene is built around participants and relations holding among them, all being situated in a spatial and temporal framework. Construal signifies the way a scene and events are portrayed and structured (Langacker 1987, 1991). Langacker demonstrates the dynamicity of construal types (b-e) on the basis of schema variants represented in Fig. (1). The sentences in (1.) below exemplify these constructions with the basic force-dynamic schema represented in (a): ← 12 | 13 →
Figure 1. Construal types (after Lagacker 1987, 1991).
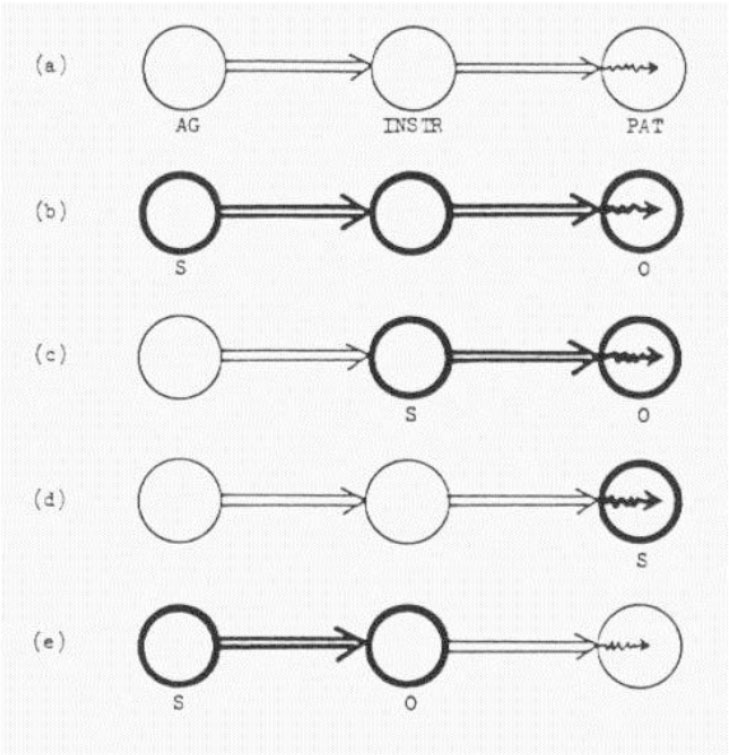
Each of the sentences in (1) presents a different foregrounding/background structure with consecutive participants made salient and represented by a distinct syntactic structure of (1).
(1)
(i) Participants, Relations & Force-dynamic Schema:
Mark (Agent) exerts force > (with) van (Instrument)> (onto) toy (Patient),
(ii) Mark crashed the toy with his van.
(iii) The van crashed the toy.
(iv) The toy easily crashed.
(v) Mark crashed the toy (under his van).
2.2 Grounding
Details
- Pages
- 296
- Publication Year
- 2017
- ISBN (Hardcover)
- 9783631663363
- ISBN (ePUB)
- 9783631707098
- ISBN (MOBI)
- 9783631707104
- ISBN (PDF)
- 9783653056488
- DOI
- 10.3726/b10717
- Language
- English
- Publication date
- 2016 (December)
- Keywords
- Corpus linguistics Cognitive linguistics Language processing Linguistic corpora Terminology Discourse
- Published
- Frankfurt am Main, Bern, Bruxelles, New York, Oxford, Warszawa, Wien, 2017. 296 pp., 25 b/w ill., 50 b/w tables
- Product Safety
- Peter Lang Group AG
Biographical notes
Piotr Pęzik (Volume editor) ![]() Jacek Tadeusz Waliński (Volume editor)
Jacek Tadeusz Waliński (Volume editor)
Piotr Pęzik is an Assistant Professor of Linguistics at the Institute of English Studies, University of Łódź. He has authored publications in the areas of corpus and computational linguistics, information extraction and information retrieval. His areas of interest also include corpus-based phraseology and the wider perspective of prefabrication and compositionality in language. Jacek Tadeusz Waliński is an Assistant Professor of Linguistics at the Institute of English Studies, University of Łódź. His research concentrates on interactions between language and cognition in the mental processing of the socio-cultural reality. His research interests also include applications of cognitive corpus linguistics for foreign language teaching and translation.
