
Nicknamen international
Zur Namenwahl in sozialen Medien in 14 Sprachen
Summary
Der Band versammelt die Ergebnisse eines internationalen und sprachkontrastierend angelegten Projekts. Dabei analysieren die Beiträger analog aufgebaute Korpora nach gleichen (und auch sprachspezifischen) Parametern. Die Analysen decken die folgenden Sprachen ab: Arabisch (Marokkanisch), Chinesisch, Deutsch, Englisch, Italienisch, Japanisch, Koreanisch, Kroatisch, Luxemburgisch, Niederländisch, Portugiesisch, Russisch, Schwedisch und Spanisch.
Excerpt
Table Of Contents
- Cover
- Titel
- Copyright
- Autoren-/Herausgeberangaben
- Über das Buch
- Zitierfähigkeit des eBooks
- Inhaltsverzeichnis
- Einleitung
- 1 Arabisch (marokkanisches) (Naima Tahiri)
- 2 Chinesisch (Jia Zhu / Yao Zhang)
- 3 Deutsch (Peter Schlobinski / Torsten Siever)
- 4 Englisch (Saskia Kersten / Netaya Lotze)
- 5 Italienisch (Sandro M. Moraldo)
- 6 Japanisch (Michaela Oberwinkler)
- 7 Koreanisch (Hojin Kim)
- 8 Kroatisch (Alexa Mathias / Anita Pavić Pintarić)
- 9 Luxemburgisch (François Conrad)
- 10 Niederländisch (Christina Margrit Siever)
- 11 Portugiesisch (Rute Isabel Fernandes Soares)
- 12 Russisch (Viktoria Kaziaba)
- 13 Schwedisch (Oliver Siebold)
- 14 Spanisch (Mario Franco Barros)
- 15 Tabellarische Zusammenfassung der Ergebnisse (Torsten Siever / Peter Schlobinski)
- Kurzbiografien
- Reihenübersicht
1 Nicknamen als Forschungsgegenstand
Nicknamen (kurz Nicks), auch als Benutzernamen (engl. usernames), Pseudonyme oder als Teilklasse der Pseudonyme behandelt, bezeichnen im Deutschen nicht amtliche Personennamen. Es sind von Personen selbst angegebene und somit auch meist selbst gewählte und nicht von anderen übernommene Namen in der digitalen Netzkommunikation, sei es in Chats, auf Foren, beim Internetgaming, auf Social Media usw. Im Englischen umfasst im Gegensatz zu proper names die Kategorie nicknames auch Spitznamen, also jene Namen, die einer Person von anderen, von außen zugewiesen werden. So ist der Nickname von Peter Schlobinski pschlobi, während sein schulischer Spitzname Schluppi war. Spitznamen können nach Kosenamen (Schatzi) und Spottnamen (Fetti) unterschieden werden. Spitznamen »leisten weit mehr als die bloße Referenz auf eine Person. Sie zeigen die soziale Beziehung und ihre emotionale Bewertung zwischen zwei Personen an.« (Nübling/Fahlbusch/Heuser 2012: 171) Und auch Nicknamen weisen mehr auf als die referentielle Funktion: Mit Rückgriff auf die intentionale Perspektive desjenigen, der einen Nicknamen kreiert, verweisen Nicknamen auf personale und lebensweltliche Aspekte, wie sich im Einzelnen zeigen wird. Wir wollen Nick- und Spitznamen unterscheiden und gehen von folgenden Faktoren/Annahmen aus (Tab. 1): Ein Nickname »ist ein überwiegend informelles Anthroponym in der computervermittelten Kommunikation und wird durch seinen Träger selbst verliehen und zwecks der Selbstidentifizierung und Selbstdarstellung benutzt.« (Kaziaba 2016: 25)
Tab. 1: Nickname vs. Spitzname
| Nickname | Spitzname | |
| nicht amtlich | + | + |
| Namensfestlegung | von Person selbst gewählt | von einer anderen Person einer Person zugewiesen |
| Perspektive | Intentionalität von Ego | Intentionalität von Alter |
| Beziehungsebene | Präsentation des Selbst gegenüber anderen | soziale Beziehung (plus emotionale Bewertung) zwischen zwei oder mehr Personen |
In der öffentlichen Diskussion und in der psychologischen Forschung (Turkle 1997; Döring 2003; Gatson 2011) stand und steht der Fokus auf der ›Verschleierung‹ ← 9 | 10 → der Identität einerseits, dem Spiel mit Identitäten und den daraus resultierenden Möglichkeiten und Chancen für die Persönlichkeitsentwicklung andererseits. An dieser Stelle wird der Aspekt des Verbergens, der Pseudonymität (gr. pseudein ›täuschen‹) in den Vordergrund gerückt. Pseudonyme sind selbst gewählte Namen; in der Onomastik bezeichnet das Pseudonym »ein neben dem bürgerlichen Namen existierender sekundärer, fakultativer Name, den eine Person aus sozialen, politischen, beruflichen oder privaten Gründen selbst wählt, um die eigene Identität für bestimmte Zeitspannen oder auf Dauer zu verbergen – oder auch, um auf diese Weise höhere Erfolge und stärkere Popularität in ihrer Tätigkeit zu erzielen.« (Gläser 2009: 509) Hierunter fallen Künstlerpseudonyme (Gilbert Bécaud > François Gilbert Silly, -ky > Horst Otto Oskar Bosetzky), Tarnnamen (Kryptonyme) wie Berthold Bürger, Robert Neuner bzw. Melchior Kurz, unter denen der ab 1933 mit Schreibverbot belegte Schriftsteller Erich Kästner publizierte, und Decknamen wie der Stasi-Deckname IM Sekretär für Manfred Stolpe.1 »Die Motive für die Selbstverleihung von Pseudonymen, deren genaue Wahl und der (erhoffte wie erfolgte) Identitätswechsel sind noch wenig erforscht. Dies gilt auch für die sog. nicknames (BenutzerN) in Internetforen, Singlebörsen, Computerspielen etc.« (Nübling/Fahlbusch/Heuser 2012: 180)
In der linguistischen Internetforschung haben Nicknamen bisher eine marginale Rolle gespielt, sodass grundsätzlich dem Statement von Aleksiejuk (2016: 15) zugestimmt werden kann: »Finally, with only a comparatively small amount of Internet data having been researched so far, any conclusions cannot be considered universally applicable. Much more data collection and analysis will have to be completed before Internet anthroponymy can be accurately and comprehensively described«, wenn auch zumindest für das Deutsche die Lage nicht ganz so desolat ist (vgl. Kap. 2). In der Internetlinguistik besteht ein Desiderat im Hinblick auf die Analyse von Nicknamen, während andere sprachliche und textuelle Merkmale gut untersucht sind; ein erster Überblick findet sich in Marx/Weidacher (2014). Aber auch in der Onomastik sind Nicknamen bisher stiefmütterlich behandelt worden, während Spitznamen/Kosenamen und Pseudonyme demgegenüber gut untersucht sind (vgl. Nübling/Fahlbusch/Heuser 2012: 171 ff.; Spillner 2016). In den letzten Jahren hat die Sozioonomastik deutlich an Gewicht gewonnen, und die Analyse von Nicknamen kann als teilparadigmatisch in diesem Kontext gesehen werden. Zusammenfassend kann festgehalten werden, dass sowohl in der ← 10 | 11 → Internetlinguistik als auch in der onomastischen Forschung Nicknamen bisher kein nennenswerter Forschungsschwerpunkt war. Das vorliegende Projekt, in dem ein vereinheitlichtes Nicknamenkorpus von 6 800 Nicknamen analysiert wird, schließt also zumindest ansatzweise eine Forschungslücke.
2 Beteiligte Sprachen, Sprachfamilien und Schriftsysteme
An dem Projekt sind Wissenschaftlerinnen und Wissenschaftler aus 14 Ländern beteiligt. Während in 13 Ländern jeweils ein monolingual strukturiertes Korpus vorliegt, haben wir in Luxemburg eine komplexe Mehrsprachigkeitssituation mit den Sprachen Deutsch, Französisch und Luxemburgisch, was sich im Korpus widerspiegelt, sodass insgesamt 15 Sprachen vertreten sind (vgl. Tab. 2 und Abb. 1).
Tab. 2: Beteiligten Sprachen und Länder (*umstritten)
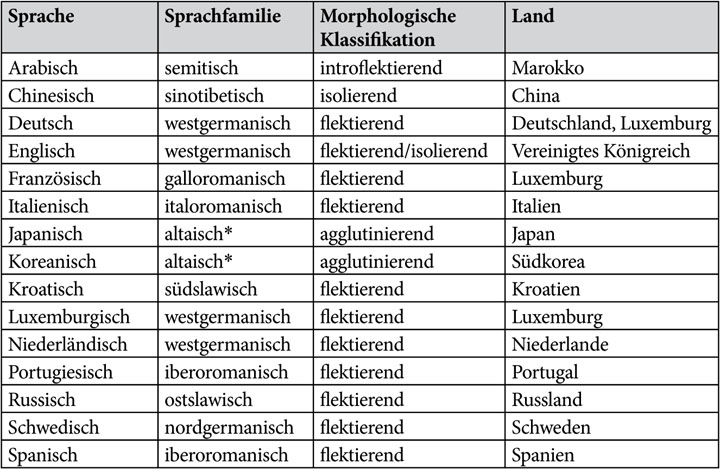
Abb. 1: Karte mit (dunkelgrau) markierten beteiligten Ländern bzw. Sprachen
Sprachtypologisch gesehen ist das Spektrum der vertretenen Sprachen weit gefächert, da es neben flektierenden Sprachen – und hier speziell eine wurzelflektierende Sprache (Arabisch) – eine isolierende und zudem tonale Sprache (Chinesisch) sowie zwei agglutinierende Sprachen (Japanisch, Koreanisch) gibt. Zu den sprachlichen Eigenschaften wird in den Einzelkapiteln Näheres ausgeführt.
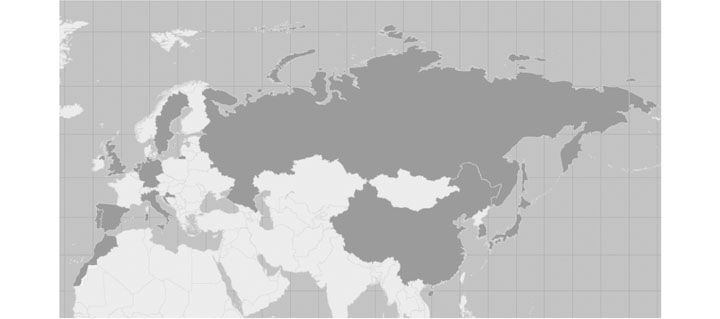
Im Hinblick auf die in den Sprachen vorkommenden Schriftsysteme sind alle grundlegenden Schriftsysteme natürlicher Sprachen vertreten (vgl. Abb. 2 u. Tab. 3)
Abb. 2: Typologie der Schriftsysteme natürlicher Sprachen
Tab. 3: Sprachen nach Schriftsystemen (*bezogen auf Hiragana/Katakana)

Schriftsysteme europäischer Sprachen weisen eine Konsonant-Vokalschreibung auf. Während im Deutschen die Laut-Buchstaben-Zuordnung relativ eindeutig ist, sind im Englischen einzelne Zuordnungsmengen von Graph zu Laut größer: z. B. [əʊ̯] orthografisch ausgedrückt durch <o, ow, ew, oh, owe, ough, oe, eau, oa, ou> wie in so, sow, sew, oh, owe, dough, doe, beau, soak, soul. Die arabische Schrift ist eine linksläufige Konsonantenschrift, in der nur die drei Langkonsonanten [aː] mit < ا >, [iː] mit < ي > und [uː] mit < و > geschrieben werden. Zudem aber gibt es optional Vokalzeichen, wenn z. B. ein Vokal kurz gesprochen werden soll.
In den ostasiatischen Sprachen gibt es unterschiedliche Schriftzeichensysteme (s. Tab. 3). Historisch gesehen war China die Geberkultur, sodass in Japan und Korea die Schriftsysteme zunächst übernommen und dann modifiziert bzw. ein eigenes, an die jeweilige Sprache besser angepasstes System geschaffen wurde. Relikte dieses Prozesses sind chinesische Lehnzeichen im japanischen Schriftsystem. Die chinesische ist eine morphosyllabische Schrift, d. h., dass ein Schriftzeichen eine Silbe und ein Morphem repräsentiert. Neben einfachen Zeichen wie 日 ›Sonne‹ und 山 ›Berg‹, in denen der piktorale Ursprung erkennbar ist, bestehen die Zeichen in der Regel aus zwei Teilen wie 妈 (fam. ›Mama‹, vgl. auch Tab. 4). Der links stehende Teil ist in unserem Beispiel ein Signifikum, 女 ›weiblich‹ gibt einen semantischen Hinweis, und der rechte Teil 马 fam. ›Mama‹, [ma35] ist ein phonetischer Indikator
Tab. 4: Schriftform von [ma]/[ma55] im Chinesischen, Japanischen (Hiragana/Katakana) und Koreanischen

Das Japanische ist ein hybrides Schriftsystem, das zwei Silbenschriftsysteme2 (Hiragana/Katakana) sowie ein chinesisches Lehnzeichensystem (Kanji) mit lautlich zwei Lesarten, einer sinojapanischen und rein japanischen (On- und Kun-Lesart) aufweist; zudem können lateinische Buchstaben (Romaji) verwendet werden. In ← 13 | 14 → der Silbenschrift kann die Silbe [ma] prinzipiell durch das Hiragana-Zeichen ま oder dem entsprechen Katakana-Zeichen マ kodiert werden, der Gebrauch des jeweiligen Silbensystems ist funktional differenziert. Ein Wort wie z. B. mada (dt. ›noch‹) besteht aus den beiden Hiragana-Zeichen まだ, das Lehnwort chessu (dt. ›Schach‹) aus den drei Katakana-Zeichenチェス.
Das koreanische Schriftsystem Hangul ist ein Alphabetsystem, in dem die die Konsonanten bzw. Vokale repräsentierenden Zeichen zu Silbeneinheiten gruppiert sind. Das dreisilbige Verb 마시다 masida ›trinken‹ besteht aus drei Silbenzeichen <마>, <시>, <다>. Jedes Silbenzeichen ist kompositional in quadratischen Silbenblöcken aufgebaut; so besteht das Zeichen <마> aus <ㅁ> für [m] und <ㅏ> für [a]. Spezifizierungen zu den einzelnen Schriftsystemen finden sich in den jeweiligen Sprachen-Kapiteln.
3 Globaler Forschungsüberblick
Wie bereits in Abschnitt 1 angesprochen wurde, ist im Bereich der Onomastik der Forschungsstand im Hinblick auf Nicknamen (bis auf Langendonck 2007: 300–306; vgl. auch Abb. 3) defizitär, in internetlinguistischer Perspektive gibt es eine Reihe von, wenn auch insgesamt und vergleichsweise wenige Untersuchungen, während andere Phänomene wie Smileys, Abkürzungen oder Inflektive in unterschiedlichsten Kommunikationsformen umfassend untersucht wurden (vgl. Marx/Weidacher 2014; Crystal 2011 sowie die Arbeiten unter <www.mediensprache.net>). Eine systematische Analyse von Nicknamen unter formal-linguistischen und inhaltlichen (semantischen) Gesichtspunkten oder eine gar sprachvergleichende Studie stehen aus.
Abb. 3: Beweggründe für die Nicknamensklassifikation nach Langendonck (2007: 300–306)
Die bekannteste und immer wieder zitierte Studie ist die Untersuchung von Haya Bechar-Israeli aus dem Jahr 1995, die als eine der wenigen Untersuchungen quantitativ angelegt ist und die auch ein Ausgangspunkt unserer Untersuchung im Hinblick auf insbesondere semantische Kategorien war. Das Korpus besteht aus 260 (Nick-)Namen aus dem Internet Relay Chat (IRC), die vornehmlich aus den USA, Europa und Israel stammen, aber nicht weiter spezifiziert werden. Eine formal linguistische und hierin genaue Analyse wird nicht vorgenommen, aber Bechar-Israeli ermittelt 14 Kategorien, nach denen Nicknamen klassifiziert werden können: 1. ›Nicks related to literature, fairy tales, characters from films, plays, and television‹ (Hagolem, Godot), 2. ›Nicks related to flora and fauna – people choose names of animals, trees, flowers, fruits and vegetables‹ (froggy, tulip), 3. ›Nicknames named after famous people‹ (Elvis, Yosi), 4. ›Nicknames related to inanimate objects of different kinds, be it weapons, cars or different types of food (BMW, Mig)‹, 5. ›Nicknames pertaining to a person’s ,self‘‹ (shydude, stoned, pilot), 6. ›Nicknames indicating affiliation with a certain place‹ (Dutchguy, ElIngles), 7. ›Nicknames associating the person with a certain age group‹ (cloudkid), 8. ›Nicknames referring to a relationship with other persons‹ (bfiancee), 9. ›Nicknames related to the medium, technology, computer names, software and IRC commands‹ (irc, kickme), 10. ›Nicknames which make a meta-comment on the anonymity of the medium‹ (unknown, justI), 11. ›Nicknames containing play with language and typography‹ (gorf > frog), 12. ›Nicknames using onomatopoeia, or imitation of sounds‹ (tamtam, tototoo), 13. ›Sex-related nicknames‹ (sexygirl, bigtoy) und 14. ›Provocative nicknames‹ (fuckjesus). Die Kategorien umfassen unterschiedliche linguistische und nicht-linguistische Dimensionen: Lautebene, Graphie, Semantik, fachsprachliche, pragmatische (14) und soziale (13) Aspekte.
Bechar-Israeli fokussiert ihre Untersuchung auf die funktionale Seite und zeigt, dass Nicknamen unterschiedliche Funktionen haben: »They are, first of all, a means to announce one’s willingness to play. They are a kind of mini-ritual in which, each time participants log on, they declare their entrance into the state of play on IRC. Nicks become part of our personality and reputation in the computer community. […] There is considerable variation in the types of nicknames that people choose. Nicknames are an initial, and usually the only marker of people’s self, or the self they are taking on. Rarely did IRCers in this study use their real name. […] the largest category of nicknames, consisting of almost half of the total, was that of nicks related to the self in some way.« (Bechar-Israeli 1995: 28) ← 15 | 16 →
Eine zweite frühe, kleine Analyse findet sich in Runkehl/Schlobinski/Siever (1998: 85 ff.), der eine Basis von 700 Nicknamen aus unterschiedlichen Chats zugrunde liegt – die Liste der Nicknamen findet sich in Schlobinski (1998) –, allerdings werden die Nicknamen nicht systematisch und quantitativ untersucht. Zentrale semantische Felder, die ermittelt worden sind 1. Klarnamen(anteile) anne oder Imke Teeny, 2. Film (Sculli 7777, Hand_Solo), 3. Musik (De Onkelz), 4. Comic (catwoman8, BAMBI), 5. Produkte (BigMacBS, Altbier), 6. Computer (cyber, EvILViRuSx), 7. Sagen/Mythen (Nefratis, hades2) und 8. Tiere (Isegrimm, der Fisch).
Die wohl quantitativ umfangsreichste Untersuchung zu Nicknamen überhaupt stammt von Kaziaba (2013, 2016). Der ersten Untersuchung liegt ein deutsches ICQ-Korpus von 2 500 Nicknamen mit Metadaten sowie eine Umfrage zugrunde, in der zweiten Untersuchung die Daten aus 2013 sowie Daten von Facebook, Twitter, World of Warcraft, World of Tanks sowie 200 Online-Umfragen (N = 4 000). Die Arbeiten sind sehr aufschlussreich, aber eine genaue quantitative Analyse hinsichtlich unterschiedlicher Faktoren wird nicht vorgenommen.
Einen kurzen Überblick über den englischsprachigen Forschungsstand gibt Aleksiejuk (2016), weitere Überblicksartikel sind uns nicht bekannt. In jedem Sprachen-Kapitel wird kurz der jeweils sprachspezifische Forschungsstand wiedergegeben. Die Ergebnisse aus der Sekundärliteratur (sofern vorhanden) werden mit den Analyseergebnissen abgeglichen.
4 Forschungsdesign
Grundprinzip des Projekts ist neben der Untersuchung der Nicknamenwahl in unterschiedlichen Sprachen die möglichst umfassende Vergleichbarkeit der Ergebnisse, wenngleich die beschriebenen sprachtypologischen Unterschiede mitunter keinen Vergleich zulassen. Im Folgenden werden Organisation, interne Kommunikation, Datenerhebung, -bereitstellung und -auswertung sowie die Analyseparameter beschrieben. Eine optionale Fragebogenerhebung wird ebenfalls erläutert.
4.1 Arbeitsorganisation
Als Kooperationsbasis diente eine speziell programmierte Onlineplattform sowie ein Forum für eine ökonomische interne Kommunikation, etwa zur Klärung von Fragen, für Absprachen hinsichtlich der Kategorisierung (Tagging), Diskussion der Analyseparameter etc. Die Plattform stellte das Korpus zur Verfügung, das über eine Vorlagendatei in einer Datenbank bereitgestellt worden ist und mittels ← 16 | 17 → Eingabemaske, d. h. komfortabler Zuweisung von Eigenschaften, bearbeitet werden konnte (s. Abb. 4 und Abb. 6). Darüber hinaus wurde über das Webformular sichergestellt, dass die Auswertung – wo möglich – tatsächlich einheitlich erfolgte (zur Kategorienerweiterung s. 4.3). Die Plattform enthielt ferner grundlegende Tools zur Auswertung: Neben Ergebnislisten, die den Kategorien zugewiesene, bearbeitbare Nicknamen filterte, wurden entscheidende quantitative Auswertungen tabellarisch präsentiert (s. Abb. 5). Schließlich bot die Plattform auch die Funktion, Inkonsistenzen aufzuspüren, indem auf zwei sich üblicherweise widersprechende Zuweisungen von Kategorien hingewiesen werden konnte (etwa bei »Pseudonym, nicht analysierbar«).
4.2 Zusammenstellung des Korpus
Den Autorinnen und Autoren ist bewusst, dass der Ausdruck Korpus den heutigen empirischen Ansprüchen nicht genügt. Mit 6 800 Nicknamen liegt der Gesamtumfang unter einer korpuslinguistischen Definitionsdimension. Dennoch – und da die Daten aufwendig per Hand analysiert werden mussten bzw. worden sind – sind Aussagen zu den Namen möglich. Schon nach der Hälfte der Auswertungen zeichneten sich Trends ab, die sich nicht mehr nennenswert änderten. Dennoch muss hier einschränkend gesagt werden, dass Repräsentativität nicht gegeben ist und sämtliche Aussagen nur Trends auch dann darstellen, wenn ein Nachkommawert angegeben ist. ← 17 | 18 →
Abb. 4: Kategorienzuweisung

Abb. 5: Exemplarische Sicht einer systemgenerierten Auswertung
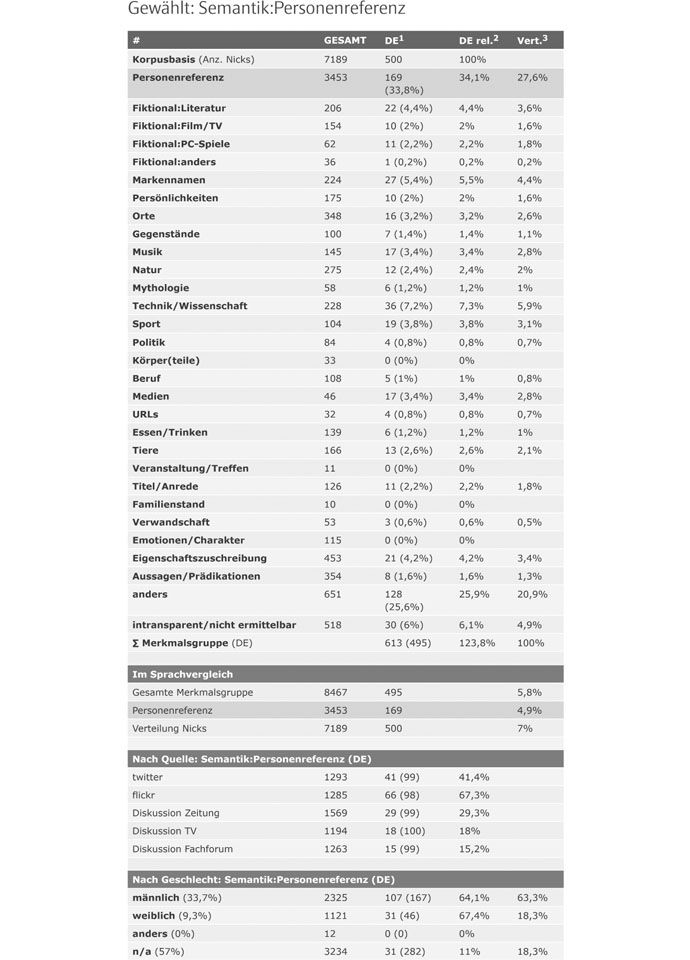
Um eine möglichst vergleichbare Basis zu erhalten, sollten sie »identisch«, also analog gemäß Tab. 5 zusammengesetzt sein. Allerdings stellte sich hierbei heraus, dass eine gemeinsame Basis kaum möglich ist. Dies lag etwa daran, dass TV-Foren in einigen Sprachen/Kulturen unüblich sind (im arabischen staatlichen Fernsehen etwa gab es keine Kommentarfunktion) oder der Twitter-Zugang in einem Lang blockiert worden ist. Bei »kleineren« Sprachen ergab sich mitunter zudem das Problem, dass Plattformen zwar verfügbar waren, doch nicht das notwendige Minimum an Postings enthielt, das gesetzt worden ist, um von einer Eben nicht etwa eine »Vollerhebung« bemühen zu müssen. Und eine weitere Problematik ist nicht erwartet worden: Viele Foren, etwa die TV- und Zeitungsforen erlauben nicht mehr nur die Wahl eines Nicknamens, sondern setzen bei der Registrierung die Vergabe von Vor- und Zuname voraus. Dies müsste bei automatisch erhobenen (gecrawlten) »Nicknamen« berücksichtigt werden, da in den Foren nicht erkennbar ist, ob es sich um zwei Felder oder eines handelt; so finden sich etwa bei BILD.de interessante Nicknamen wie sprach los oder Inder Tat, doch leider hat der Nutzer hier nicht die Wortbildung aufgebrochen oder eine PP teilweise zusammengefasst, um die Struktur Vorname Nachname zu imitieren oder Assoziationen hervorzurufen, sondern seinen Nicknamen schlicht auf zwei Formularfelder aufteilen müssen. Zuletzt sei noch darauf hingewiesen, dass eine Kategorie »IT-Forum« zu weiträumig ist, da sich herausgestellt hat, dass in Abhängigkeit der Professionalität und Intention von Plattform und Programmierern (und solchen, die es eben nicht sind) frappierende Unterschiede auch bei der Namenwahl bestehen.
Tab. 5: Zusammensetzung der Subkorpora
| Plattformkategorie | N | Profildaten |
| Flickr | 100 | ja |
| 100 | ja | |
| TV-Forum | 100 | nein |
| Zeitungsforum | 100 | nein |
| IT-Forum | 100 | nein |
Dennoch konnten alle Teilnehmerinnen und Teilnehmer die vorgesehene Basis erheben und 500 Nicknamen analysieren (zur Abweichung beim Japanischen s. dort). Der freigegebene Teil des Korpus ist unter <https://corpora.mediensprache.net/de/corpora/> für Forschende zugänglich. ← 19 | 20 →
4.3 Analyseraster/Untersuchungskategorien
Wie bereits beschrieben, griffen alle Kolleginnen und Kollegen auf ein einheitliches Analyseraster zurück. Neben grundsätzlichen demografischen Daten, die bei der Korpuserstellung erfasst, aber auch später ergänzt werden konnten, wurde eine Namensklassifikation durchgeführt (Realname, Pseudonym), eine morphologische und syntaktische Analyse vorgenommen (Wortart, Wortbildung etc.), »phonische« Besonderheiten ermittelt (Homophonie, Alliteration etc.), es wurden die Nicknamen hinsichtlich der Schreibung und graphostilistischer Merkmale bestimmt (von der Norm abweichende Groß-, Klein-, Getrennt- oder Zusammenschreibung, Bildzeichen, Leetspeak etc.) und sowohl lexikalisch (fachsprachlich, vulgär etc.) als auch semantisch klassifiziert (Fiktionalität, Personenreferenz, Ortsangaben etc.). Eine vollständige Darstellung der gemeinsamen Kategorien, hinsichtlich derer die Nicknamen analysiert worden sind, findet sich in Tab. 6.
Tab. 6: Analysekategorien (Basiskategorien)
| Basisdaten | |
| Nickname | |
| Realname | |
| Sexus | |
| Alter | |
| Namensklassifikation | |
| Realname | Rufname(n), hier jeweils
- Vollform (Katarina) - Kurzwort (Kata) - Initiale/Abkürzung (K., Ktr) |
| Familienname(n)
- mit Präfix (von der, van den, de) und jeweils - Vollform - Kurzwort - Initiale/Abkürzung |
|
| Pseudonym | analysierbar |
| nicht analysierbar | |
| Morphologische Klassifikation | |
| Wortart (bei Komplexen der Kopf) | Substantiv (inkl. Eigennamen) |
| Adjektiv (auch Partizip) | |
| Adverb | |
| Verb(form) (inkl. Infinitiv, Imperativ etc.) | |
| andere ← 20 | 21 → | |
| Morphologische Klassifikation | |
| Wortbildung | einmorphemig:
- Simplex (tovarus) |
| mehrmorphemig:
- Derivation Diminutiv (Berlinchen) ▪ Negation (unschön) ▪ andere (gepixelt) - Komposition (sternenstaub, Angela Merkel) - Reduplikation (schlauschlau) - Wortkreuzung (Blukkoli) |
|
| weiteres:
- Kurzwort (außer Realnamen, wortfähig wie Studi) - Abkürzung (außer Realn., nicht wortfähig wie z.Zt., asap) - Reanalyse (Ham+burger) - Anderes |
|
| Syntaktische Klassifikation | |
| syntaktisch | Phrase
- Apposition/Aufzählung (Dirk65, Fotostudio Meier) - Anderes (ausdemhäuschen) Satz (I´mBack; inkl. Ellipse) Anderes |
| Orthografie/Graphostilistik | |
| Schreibung (abweichend v. Std.) | Kleinschreibung:
- vollständig (sternenstaub) - partiell (stern+Staub) Großschreibung: - vollständig (STERNSTAUB) - partiell (sternSTAUB) - an Anfängen (ZuZug, YouAndMe) - an Enden (ZuzuG) Zusammenschreibung: - vollständig (derklugefritz) - partiell (der klugefritz) |
| Trennzeichen | Trennzeichen (uwe.meier) |
| Zahlen | Alter (uwe23)
Geburtsjahr (uwe1994) Homophonie (just4fun) Anderes (uwe2) ← 21 | 22 → |
| Orthografie/Graphostilistik | |
| Bildzeichen | Smiley (kompositionell) wie uwe:-)
- Emoji ▪ Gesichtszeichen (uwe ▪ andere (♥uwe♥) |
| Iteration | Iteration (uwe♥♥♥, uuuwe, uwe!!!) |
| Weiteres | Leetspeak (H()T), al3x!s
Schriftsystemwechsel (glücklicher Обезьяна) Andere (MiZi @ SC) |
| Weitere Kategorien | |
| phonisch | Slang (flickr, Jachtin; lex. siehe dort)
Homophonie (Rumpelstielz) Alliteration (ChrisCross) Anderes (Onomatopoetika unter Lexik) |
| Lexikalische Klassifikation | |
| Lexik | fremdsprachlich:
- englisch (angel) - andere Sprache (grazie, god dag) Neuschöpfung (Tombografie) fachsprachlich (gepixelt) vulgär (Sexual-/Fäkalwortschatz, scheißwolf) dialektal (moinmoin) sprachspielerisch/ironisch (marcarioni) phraseologisch (aufDemHolzweg) onomatopoetisch (wauwau) Sexus-bezogen: - explizite Sexusmarkierung (MünchnerIn) Weiteres: - Sonstiges ← 22 | 23 → |
| Semantische Klassifikation | |
| Felder | Fiktionalität (auch Namen):
- Literatur inkl. Comics, Mythen (Tonio Kröger) - Film/TV (ill padrino) - PC-Spiele (WOW23) - andere Marken- und Firmennamen (Foto Haas, Camp David) Persönlichkeiten (nicht-fiktional wie Roger Federer) Orte (Hannover, Münchner) Gegenstände (Messer, Stuhl) Musik (metulsky) Technik/Wissenschaft (gepixelt, sternenstaub) Natur (maerzbecher-D zu Fuß) Mythologie/Theologie (Zeus_Olymp) Sport (Podolski, Wandern) Politik (Merkel, Mutti) Körper(teile) (Nase) Beruf (Zahnarzt) Medien (ARD) URLs (<www.xyz.de>) Essen/Trinken (PizzaBoy) Tiere (Eichhorn) Veranstaltung/Zusammentreffen (cebit-toni) Titel/Anrede (FrauHübsch) Familienstand (LedigerUwe) Verwandtschaftsrelation (TochterVonPepe) Emotionen/Charaktereigenschaften (zornigerPeer) Zuschreibungen/Charaktereigenschaften (supercoolEr) Aussagen (Prädikationen wie IchBinStefan) Personenreferenz (Kai) Sonstiges (semantisch bestimmbar, aber Kategorie fehlt) Bedeutung nicht ermittelbar (fiw2d) |
Sprachtypologisch konnten einige Analysen nicht oder nur vom Standardraster abweichend durchgeführt werden (z. B. beim Chinesischen oder Arabischen), und auch kulturspezifisch finden sich einige Unterschiede hinsichtlich der Kategorien (etwa semantisch in Form eines Sich-Vorstellens beim Portugiesischen).
Die Kategorien wurden nach einer ersten Analyse von (je Sprache) 100 Nicknamen aus allen Bereichen im Rahmen einer Präsenzsitzung sowie Diskussionen im Forum um notwendige Kategorien resp. vorhandene verändert/präzisiert; so wurden etwa die Zuweisung mehrerer Vornamen ermöglicht sowie die Kategorien ← 23 | 24 → um das Tag »Nachname mit Präfix« (von der, van den, de) erweitert, die im Luxemburgischen oder Niederländischen weitaus häufiger, also relevant(er) sind als im Deutschen oder Englischen. Vor allem die semantischen Kategorien wiesen große Lücken auf, die durch die ersten Analysen geschlossen werden konnte. Generell stellte die (inhaltsanalytisch orientierte) Ermittlung und Zuweisung der semantischen Kategorien das Team vor größere Probleme (s. hierzu etwa Abschnitt 3.4.7).
Abb. 6: Ausschnitt aus der Nicknamebearbeitung

4.4 Option Fragebogenerhebung
Freigestellt wurde eine Fragebogenerhebung, die dazu dienen sollte, die Motive bei der Nicknamenwahl zu erfassen. Die Idee zu einer Fragebogenerhebung ergab sich inmitten der Projektphase während eines Seminars von Schlobinski und der Diskussion mit Studierenden zur Wahl ihres Nicknamens. Mittels der Fragebogenauswertung fokussieren wir insbesondere auf Aspekte, die durch die Korpusanalyse nur schwer oder gar nicht erfasst werden können und deshalb von besonderem Interesse sind. ← 24 | 25 →
Die Fragebogenerhebung hat einen reinen Pilotcharakter, Vorgabe war es, 100 Nicknamen zu erhalten, die dann hinsichtlich der Wahlmotive ausgewertet werden sollten. Wie dem Fragebogen zu entnehmen ist (vgl. <www.mediensprache.net/997>), geht es um die Erläuterungen und die damit verbundenen inhaltlichen Aspekte. Eine Analyse nach dem angelegten Analyseraster war nicht vorgegeben, in jedem Falle sollten die Analysen nicht in die Korpusanalysen einbezogen werden, um nicht die Stichprobe zu verzerren.
Im Nachhinein erscheint es uns interessant, eine systematische Fragebogenerhebung hinsichtlich der Motivlagen von Usern durchzuführen.
5 Buchaufbau: Sprachen/Wissenschaftler, Aufbau der Beiträge
Insgesamt 18 Forscherinnen und Forscher haben Nicknamen in 14 Sprachen untersucht. Beteiligt waren im Einzelnen:
1. Naima Tahiri (Marokkanisches Arabisch)
2. Jia Zhu & Yao Zhang (Chinesisch)
3. Peter Schlobinski & Torsten Siever (Deutsch)
4. Saskia Kersten & Netaya Lotze (Englisch)
5. Sandro Moraldo (Italienisch)
6. Michaela Oberwinkler (Japanisch)
7. Hojin Kim (Koreanisch)
8. Alexa Mathias & Anita Pintaric (Kroatisch)
9. François Conrad (Luxemburgisch)
Details
- Pages
- 400
- Publication Year
- 2018
- ISBN (Hardcover)
- 9783631748091
- ISBN (PDF)
- 9783631749043
- ISBN (ePUB)
- 9783631749050
- ISBN (MOBI)
- 9783631749067
- DOI
- 10.3726/b13496
- Language
- German
- Publication date
- 2018 (August)
- Keywords
- Nickname Onomastik/Namenforschung Sprachkontrast Internetlinguistik Social Media/Soziale Medien Semantik/Morphologie
- Published
- Berlin, Bern, Bruxelles, New York, Oxford, Warszawa, Wien, 2018. 400 S., 12 s/w Abb., 143 s/w Tab.
- Product Safety
- Peter Lang Group AG
