
Noun Phrases in Czech
Their Structure and Agreements
Summary
Excerpt
Table Of Contents
- Cover
- Title
- Copyright
- About the author
- About the book
- This eBook can be cited
- Table of Contents
- Abbreviations
- 1. Introduction to the topic and the approach
- 1.1 The architecture of morphosyntax
- 1.2 Levels of insertion: (Radically) Distributed Morphology
- 1.3 Categories and labels
- 1.4 Morphosyntactic lexicalization and locality
- 2. A structural overview of Czech nominal phrases
- 2.1 Pre-modification of nominals
- 2.1.1 Determination and quantification
- 2.1.2 (Pre-) Modification by adjectives
- 2.1.3 Agreement inside the nominal complex
- 2.1.4 The Surface Recursion Restriction on complements
- 2.2 Post-modification
- 2.2.1 Postnominal Adjectives
- 2.2.2 Postnominal Genitives in Czech
- 2.2.3 Genitive pronouns in postnominal position
- 2.2.4 The general structure of the postnominal field
- 3. The DP hypothesis for Czech
- 3.1 The historical layout
- 3.1.1 Jackendoff (1977) and multi-layered NPs
- 3.1.2 Abney (1987) and the general DP hypothesis
- 3.1.3 Cinque (1994) and the cartographic approach
- 3.1.4 Veselovská (1994) and the Slavic window onto UG
- 3.1.5 A universal or parametrised DP projection?
- 3.2 Semantic features of the Determiner
- 3.3 Constituents in the functional domain of N
- 3.3.1 Functional vs. lexical morphology
- 3.3.2 Quantifiers as heads of a QP
- 3.3.3 N-to-D movement (head-to-head movement)
- 3.4 A note about NP island violations
- 3.4.1 The left branch condition and the lack of articles
- 3.4.2 Veselovská (1994): remnant movement
- 3.5 The DP hypothesis revisited
- 4. The hierarchy in the prenominal field
- 4.1 Traditional descriptions of the prenominal field in English
- 4.1.1 Present-day grammar manuals for English
- 4.1.2 Comparison with adjectival ordering in the Czech tradition
- 4.2 Universal constraints on left to right ordering of Adjectives
- 4.3 The order of Noun modifiers in Czech
- 4.3.1 Proposals of Czech linguistics
- 4.3.2 Examining the order in Czech using corpora study
- 4.3.3 A pilot study: prenominal or postnominal?
- 4.3.4 Corpus based study of lexical vs. functional domains: Syn2010
- 4.4 Distribution of entries within the functional domain
- 4.4.1 Multiple entries in the Czech D field
- 4.4.1.1 Multiple Quantifiers and demonstratives
- 4.4.1.2 Partitive versus non-partitive readings
- 4.4.2 The repertory of D modifiers in Czech
- 4.5 Distribution of items in the lexical domain: Adjective pre-modifiers
- 4.5.1 Comparing English and Russian: Scott (2002) and Pereltsvaig (2007)
- 4.5.2 Comparing Czech pre-modifiers with Russian and English
- 4.5.2.1 Data and their analyses
- 4.5.3 Drawing conclusions from the statistics
- 4.5.3.1 Distance Criterion
- 4.5.3.2 A Frequency Criterion
- 4.5.4 Interpreting the Czech and English data for the lexical domain of Nouns
- 5. A universal structure
- 5.1 Three theoretical approaches to adjectival modification of Nouns
- 5.2 Diagnostic characteristics of the prenominal domain
- 5.2.1 Distinct types of constraints in the D- and N-fields
- 5.2.2 Recursive stacking in the N-field
- 5.2.3 Subcategorization: insensitivity to the N-field
- 5.2.4 N(P) pro-forms in the D-field
- 5.2.4.1 The English substitute one
- 5.2.4.2 N(P) pro-forms in Czech
- 5.2.5 A Left Branch Recursion Restriction on complementation
- 5.2.6 Comparing the three analyses of prenominal Adjectives
- 5.3 The Derived Nominal Analysis (DNA) of adjectival agreement
- 5.3.1 Adjectival agreement: the Gender infix [N έ]
- 5.3.2 Generalizations based on soft adjectival agreement
- 5.3.3 The (pro)nominal nature of adjectival agreement
- 5.3.4 The DNA hypothesis and the structure of the nominal complex
- 6. Czech Possessive structures
- 6.1 Morphology of the Czech Possessive
- 6.1.1 Introducing the Possessive morphemes
- 6.1.2 Agreement endings on the Possessive
- 6.2 The feature content and structure of Czech Possessives
- 6.2.1 The combinatorial potential of the Possessive suffix
- 6.2.2 The constituent type of the Czech Possessive
- 6.3 Semantics of Possessives
- 6.3.1 Possessive as an A(rgument)-position
- 6.3.2 The argument hierarchy in a Czech DP
- 6.4 Derivation of the Possessive: a movement analysis
- 6.5 Possessive morphology: the Case stacking analysis
- 6.5.1 Morphology of the Possessive: a new perspective on Case theory
- 6.5.2 The GEN nature of the Possessive morpheme
- 6.5.3 Possessive suffixes are allomorphs of the phrasal-level N-Case
- 6.5.4 Confirming non-canonical variations among Possessives
- 6.6 Theoretical implications of Czech Possessives
- 7. Quantified nominals in Czech
- 7.1 Czech variety of quantified phrases
- 7.1.1 The principal Czech patterns
- 7.1.2 Lexical vs. functional Qs: double DP vs. a single QP
- 7.1.2.1 Semantics and morphosyntax of the double DP
- 7.2 Referential index of the D projection
- 7.2.1 Relativisation
- 7.2.2 AP postmodification and secondary predicates
- 7.2.3 Pragmatic antecedent of a pronoun
- 7.2.4 Categorial distinctions among the Quantifiers
- 7.3 Premodification of a double DP versus a single DP
- 7.4 The nominal feature set and morphology
- 7.4.1 Morphology (feature content) of container and group Nouns
- 7.4.2 Morphology of Q[±] Quantifiers (including 5&up cardinals)
- 7.4.3 Morphology of agreeing Q[φ] Quantifiers (including low cardinals)
- 7.4.4 Ellipsis of quantified Nouns
- 7.4.5 Interim summary
- 7.5 Case and agreement patterns
- 7.5.1 Theoretical basis for formulating agreement
- 7.5.2 Case features and Case stacking
- 7.6 The variety of agreements patterns with Czech Quantifiers
- 7.6.1 Homogenous double agreement pattern: adnominal Genitive
- 7.6.2 The specificity of Czech group Nouns: QN
- 7.6.3 Heterogeneous split agreement pattern for Q[±]
- 7.6.3.1 The agreement patterns of the Czech Partitive Q[±]
- 7.6.3.2 Two sources of GEN
- 7.6.3.3 An analysis of the Czech Q[±]
- 7.6.3.4 The frozen paradigm of the Czech Q[±]
- 7.6.4 Homogeneous single agreement pattern of the Q[φ]
- 7.6.5 Right vs. left adjunction
- 7.6.6 A note about the morphosyntactic terminology for Czech Quantifiers
- 8. Nominal features outside DP: (Dis)agreements
- 8.1 A theory of (morphological) agreement
- 8.1.1 Agreement hierarchies
- 8.1.2 The many faces of agreement (in Serbo-Croatian)
- 8.1.3 Minimalist unification of agreement types
- 8.2 Explicit agreements in Czech: introduction
- 8.2.1 Synthetic and analytic subject-predicate agreements
- 8.2.2 Two kinds of subject-predicate agreement
- 8.3 Subject-predicate disagreements in Czech
- 8.3.1 Three disagreements of personal pronouns
- 8.3.2 Agreement with Quantifiers and Numerals
- 8.3.3 Postverbal coordinate structures
- 8.3.4 Special lexical items (děvče ‘das Mädchen’)
- 8.4 The building blocks of analytic agreement
- 8.5 Decomposing the Czech predicate
- 8.5.1 Positions of Czech synthetic Verb forms
- 8.5.2 Analytic verbal forms in Czech
- 8.5.3 Distinctions between the functional and lexical domains
- 8.5.3.1 Possibility of Tense and Aspect
- 8.5.3.2 Word orders of small v and I
- 8.5.3.3 The position of clausal Negation
- 8.5.3.4 VP ellipsis and short answers: I is not enough
- 8.5.3.5 Dialectal variation in morphology
- 8.5.3.6 Phonetic reduction in I, not V
- 8.5.3.7 Reduction to bound morphemes
- 8.5.4 Structural representation of lexical and functional domains
- 8.6 Summary of extended nominal projections in Czech
- 9. The phi features of predicate agreement
- 9.1 The position of Czech pronouns
- 9.1.1 The Gender feature of pronouns
- 9.1.2 Gender impoverishment with pronouns
- 9.2 Analytic subject-predicate agreement
- 9.2.1 Features of the N(P) domain
- 9.2.2 Features of the D(P) domain
- 9.2.3 Pronominal (dis)agreement patterns
- 9.2.4 The VP internal subject hypothesis
- 9.3 Agreement with imperative Verbs
- 9.4 Coordinate structure agreement
- 9.4.1 Symmetry and asymmetry of Czech coordinations
- 9.4.2 Coordinate structure projection and the variety of Czech coordinators
- 9.4.3 Predicative vs. argumental coordinations
- 9.4.4 Partial (first conjunct) agreement with post-verbal subjects
- 9.5 A note about combining analyses
- 9.6 Summary of subject-predicate agreement analyses
- 10. Appendix: a case study of Czech Quantifiers
- 10.1 A group Noun spoust(a) ‘plenty’
- 10.1.1 Verbal agreement with spousta ‘plenty + NGEN’
- 10.1.2 Premodification of the group Noun spousta
- 10.1.3 Relativization of the quantifying element spousta
- 10.1.4 Case of the complement of the QN
- 10.2 Elements with dual lexical specifications
- 10.2.1 The Noun and Quantifier pár ‘a/the couple’
- 10.2.1.1 A note about Czech diminutives
- 10.2.2 The semi-Numerals sto ‘hundred’, tisíc ‘thousand’, milión ‘million’
- 10.3 Pronominal Quantifiers
- 10.3.1 Animate compound pronouns [+WH, +HUMAN]
- 10.3.2 Inanimate compound pronouns [+WH, -HUMAN]
- 11. Summary of this work
- 12. Bibliography
- Corpora (and other data sources)
- Literature
- 13. Thematic Index
- Series index
Subscripts (Glosses)
Ordering of a cluster of Phi features in glosses: subscript Person ± Gender ± Number.Case.
For space reasons, only discussion-relevant features are provided.
1. Introduction to the topic and the approach
This monograph describes the properties of nominal phrases in Czech, analysing the language specific data within a theoretical framework of generative grammar. It specifies an overall and relatively complete characterization of the Czech nominal domain, as well as provides detailed case studies that argue in favour of concrete, quite specific hypotheses. In doing so, it exposes the reader not only to the author’s analysis, but also to a substantial amount of Czech data and paradigms (including some statistics supplied by corpora searches), which can be used in further research.
The majority of shared theoretical assumptions in the generative framework have been demonstrated using English data. This study therefore in many cases illustrates the topics discussed both in English and Czech, in order to point out contrasts. Data from other, mostly Slavic languages are used too, as far as it seems to be useful. In no case, however, does this study claim to provide any generalised or complete description of the variety of constructions among Slavic languages.
As for the more general theoretical issues, this study addresses them to the extent they are relevant. Dealing with data in Czech, i.e., a highly inflected language with a relatively relaxed word order, the author’s position concerning the relation between morphological and syntactic levels must be clear and explicit, and it is precisely because of the typology of the Czech language that this study assumes the unified and integrated character of two traditionally separated levels of linguistics, i.e., of syntax and morphology.
In the text of this monograph I have cited a number of studies by other authors who analyse similar data, usually in a compatible framework. Sometimes I briefly summarise an alternative analysis, but these sections are far from exhaustive expositions of the cited works, which indeed deserve more attention. Moreover, although I tried to make them representative, the choice of the cited works does not constitute a complete collection of the literature dealing with the topic, and the reader may find several authors who have not been cited here at all. This happened partially due to the lack of space and time, partially also to my ignorance of some of the sources.
On the other hand, the structure of the Czech NP has always been a topic which I have thought about, and in the past I wrote several studies dealing with some specific parts or aspects of these nominal projections. Some chapters of the following monograph use the paradigms and partial analyses that I have been presenting since Veselovská (1994), which contained several chapters ← 15 | 16 → dealing with NP/DP. However, although the Czech data remain much the same, the framework has undergone a substantial development and my view of the structure has changed, too. Thanks to more researchers dealing with Czech in the present day generative framework (most of which are cited in the following chapters), I can work now with a larger amount of interesting data and paradigms, and I can consider several alternative analyses. In this monograph therefore many analyses have changed when compared with my previous works. Also, while my preceding works dealt with some partial aspect of the NP structure in isolation, I have here attempted to present a complete view in a compatible and internally consistent framework. I thus believe that the following study represents a substantial step forward in the study of the Czech NP.
In the following sections I will briefly introduce the theoretical framework I use.
1.1 The architecture of morphosyntax
In this study, I will assume a broadly Minimalist framework as in, e.g., Adger (2003). More detailed analyses of specific phenomena related to the nominal complex in Czech also refer to numerous studies cited in the various chapters, some of which hopefully represent significant contributions to the generative framework. The overall theory remains always strictly derivational, assuming semantic and phonetic interfaces and phasal derivations motivated by a (perhaps not yet sufficiently developed) feature system. A schematic picture of the morphosyntactic process deriving a language structure is given in (1.4).
The status of morphology in the architecture of grammar is still a topic of discussion in standard generative frameworks, and several parallel research programmes are pursued at the same time, producing interesting data and hypotheses concerning the taxonomy of morphemes and the relation between grammatical and lexical morphemes.
One branch of research consists of representatives of some kind of lexicalist approach, e.g., Word Syntax (see Di Sciullo and Williams 1987; Scalise 1984; Lieber 1992), the advocates of which assume that affixes are fully or partially specified lexical items differing to no significant degree from stems of the category Noun, Verb or Adjective/Adverb. On the other hand, the proponents of a non-lexicalist approach, e.g., Lexeme-Morpheme Based Morphology (see Beard 1995a) assume that the only level where the sign (meaningful unit) can be expressed is the lexeme (word) level, and that bound grammatical morphemes are purely phonological modifications of lexemes conditioned by morphological categories but not lexically tied to them. In these separatist theories, the grammatical ← 16 | 17 → morphemes are inserted into the structure after movement rules but before post-cyclic phonological operations. Moreover, the pre-phonological rules are applied in an autonomous morphological spelling component. Beard’s Lexeme-Morpheme Based Morphology thus assumes an autonomous level of morphology, which operates under specific rules: both inflectional and derivational types are phonologically realised by an autonomous morphological spelling component, which is applied after all syntactic rules but before any phonological rules.1
The currently more standard Distributed Morphology (DM) framework accepts the taxonomy of morphemes and Beard’s Separation Hypothesis (see, e.g., Embick and Noyer 2007), but its adherents explicitly propose an architecture of grammar in which a single generative system is responsible both for word structure and phrase structure:
(1.1) “[…] the ‘word’ is not a privileged derivational object as far as the architecture of the grammar is concerned, since all complex objects, whether words and phrases, are treated as the output of the same generative system (the syntax) […] since the only mode of combination in the grammar is syntactic, it follows that in the default case, morphological structure simply is syntactic structure.” (Embick and Noyer 2007 p. 2)
This claim is intended to be in concord with the Inclusiveness Condition (cf. Chomsky 1995a; 2000), a principle intended to prevent the introduction of novel material in the course of a derivation.2
(1.2) The Inclusiveness Condition: No new features are introduced by derivation.
Overall, this study accepts the hypothesis assuming only one generative mechanism for derivation and no autonomous morphology module, as argued for in Emonds (2000, chs. 3 and 4). A detailed outline of such a theory, which I here call Radically Distributed Morphology, follows. ← 17 | 18 →
1.2 Levels of insertion: (Radically) Distributed Morphology
Standard present-day DM rejects the Lexicalist Hypothesis in favour of the claim that syntactic categories are purely abstract, having no phonological content.3 The Late Insertion Hypothesis of DM claims that the phonological expression of syntactic terminals is in all cases provided in the mapping of the Phonological Form (PF), i.e., that only after syntax are phonological expressions (Vocabulary Items) inserted into the structure by means of a process called Spell Out.4 A Vocabulary Item (“VI”) is the term used for the relation between a sound (phonological string or ‘piece’) and a lexically specified context (information about where that piece may be inserted). Vocabulary items thus provide the set of phonological signals available in a language for the expression of abstract morphemes. The set of all language-specific VI is called the Vocabulary.
However, the atoms of morphosyntactic representation are not VI but morphemes. The term morpheme refers in DM to a syntactic (or morphological) terminal node and its grammatical content, not to the phonological expression of that terminal, which is provided as part of a VI. The content of a morpheme active in syntax consists of syntactic-semantic features drawn plausibly from a parametrised set made available by Universal Grammar.
In the DM framework, the morphemes are divided into two basic kinds: F-morphemes and L-morphemes. This division is introduced in Harley and Noyer (1998), and it roughly corresponds to the conventional division between functional and lexical categories.5 The L-morphemes are defined as morphemes, the content of which suffices to determine a unique phonological expression. The Spell Out of an L-morpheme is said to be deterministic, because there is no choice as to Vocabulary insertion. The F-morphemes are defined as those for which there is a choice in Spell Out. Some that do not play a role in syntax proper (such as passive or Case, see Marantz (1991)) can be inserted after syntax but before the PF Spell Out. These morphemes, which only indirectly reflect syntactic structures, are called Dissociated Morphemes (Embick 1997, 2007). ← 18 | 19 →
To conclude, DM claims that elements within syntax and within morphology are both understood as discrete (instead of as results of morpho-phonological processes), and they enter into the same types of constituent structures – e.g., binary branching trees. The DM framework distinguishes two kinds of morphemes (lexical L and functional F) and relates their distinction to the levels of their insertion into the structure. Both these two levels of insertion are made distinct from VI insertion, which takes place in a derivation after Spell Out.
In the following paragraphs, I am going to briefly describe a conceptually similar variety of DM, which uses a tri-level insertion of morphemes as developed in Emonds (1991; 2000), which are the studies I am going to use for terminology and further references.6 As in standard DM, Emonds’s framework assumes that the properties of the two main sub-types of traditional morphology, inflection and derivation, are both better explained in terms of a lexical theory justified by syntax than in any framework that treats morphology separately; for a comparison, see Veselovská and Emonds (2015). Emonds’s derivational approach allows at least indirect reference both to phases and distinct levels, and uses a clear cut distinction between three levels of insertion of morphemes.
The conditions on lexical insertion based on Emonds (2000) are as follows:
(1.3) Three levels of morpheme insertion/lexicalization (Veselovská and Emonds 2015)
a. Phase-initial insertion (Deep lexicalization): Lexical heads (lexical morphemes) associated with purely semantic features [ƒ] satisfy lexical insertion conditions before transformations apply in a phrasal domain containing them.7
b. Phase-final insertion (Syntactic lexicalization): Items with interpreted syntactic features [F] (but no purely semantic features [ƒ]) satisfy insertion conditions as part of transformations applying in a phasal domain containing them.8 ← 19 | 20 →
c. PF (Late) Insertion (Phonological lexicalization): Vocabulary Items specified solely in terms of contextual and other uninterpretable features are inserted subsequent to any operation contributing to Logical Form (LF).9
(1.4) Lexicon related to the T-Model of derivation
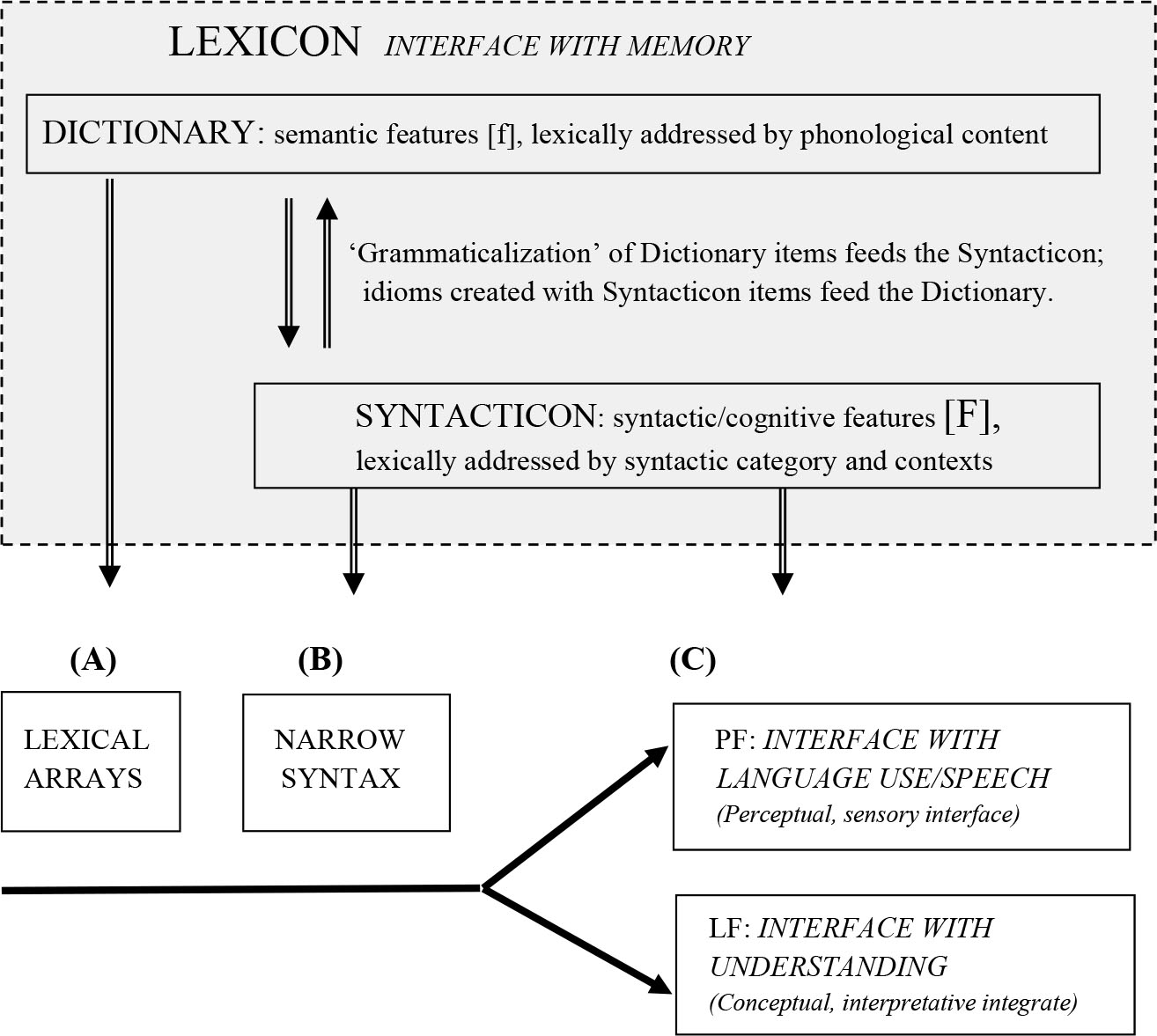
In this framework, the level of insertion of an individual morpheme is not arbitrary: it crucially depends on the feature content of a given morpheme, and it assumes principles of economy that prefer later insertion over an earlier one: a morpheme is not inserted before PF unless it is required for interpretation in LF. ← 20 | 21 →
The three-level insertion model as in (1.3) does not violate even the strong version of the Inclusiveness Condition in (1.2) because all the inserted elements are morphemes stored in the Lexicon and are a part of the numeration. According to their feature characteristics, the morphemes are stored in one of the two parts of the Lexicon: the open class lexical entries in the Dictionary (see also the Encyclopaedia in Marantz (1997)) and the grammatical entries in the Syntacticon, a term for the repository (list) of grammatical morphemes that allow the more economical non-phase-initial levels of insertion (see also the Grammatical Lexicon of Ouhalla (1991)).
It will be useful to keep in mind how in this model the various types of lexical storage and insertion are related to the architecture of a syntactic derivation that follows the T-model of Chomsky and Lasnik (1977). The scheme in (1.4) is adopted from Emonds (2000, p. 437).
Veselovská and Emonds (2015) argue that the insertion levels in fact precisely predict the traditional taxonomy of morphosyntactic characteristics that distinguishes (A) lexical morphemes (Roots √), (B) derivational affixes (including category-determining heads), and (C) inflections (including some cross-categorial morphology).
Details
- Pages
- 386
- Publication Year
- 2018
- ISBN (Hardcover)
- 9783631757413
- ISBN (PDF)
- 9783631759523
- ISBN (ePUB)
- 9783631759530
- ISBN (MOBI)
- 9783631759547
- DOI
- 10.3726/b14278
- Language
- English
- Publication date
- 2018 (October)
- Keywords
- Czech syntax Possessives Quantifiers DP Hypothesis Morpho-syntactic interface
- Published
- Berlin, Bern, Bruxelles, New York, Oxford, Warszawa, Wien. 2018. 386 p. 37 b/w ill., 58 b/w tab
- Product Safety
- Peter Lang Group AG
Biographical notes
Ludmila Veselovská (Author) ![]()
Ludmila Veselovská works at the Faculty of Arts, Palacky University in Olomouc, Czech Republic. Her research focuses on the morpho-syntax of English and Czech. She was the founding organizer of the EGG summer schools in 1994-7 and of the Olinco colloquia in 2013-2018, which helped to establish generative frameworks in the traditionally rich Czech linguistic space.
