
Lexicon of Common Figurative Units
Widespread Idioms in Europe and Beyond. Volume II
Summary
Excerpt
Table Of Contents
- Cover
- Title
- Copyright
- About the author(s)/editor(s)
- About the book
- This eBook can be cited
- Contents
- Preface
- 1 Introduction
- 1.1 Objectives and Terminology
- 1.2 Widespread Idioms in Europe and Beyond: The Empirical and Theoretical Approach
- Empirical approach
- Theoretical foundation
- 1.3 The Languages of the Project
- 1.4 The Macrostructure of the “Lexicon of Common Figurative Units”
- 1.5 The Microstructure of the “Lexicon of Common Figurative Units”
- 2 Theater, Music, Sports and Games
- 2.1 Arts and Entertainment as Source Domains: Introduction
- 2.2 Stage Production and Music (G 1 – G 8)
- 2.3 Sports (G 9 – G 15)
- 2.4 Games, Playing and Gambling (G 16 – G 20)
- 2.5 Concluding Remarks on Performing Arts, Sports and Games
- 3 History and War
- 3.1 History and Armed Conflicts as Source Domains:Preliminary Remarks
- 3.2 History of Ancient Times (H 1 – H 7)
- 3.3 History of Medieval and Modern Times (H 8 – H 13)
- 3.4 Fighting and Knighthood in the Middle Ages (H 14 – H 22)
- 3.5 Warfare and Weapons of Modern Times (H 23 – H 31)
- 3.6 History and War: Summary
- 4 Intellectual and Technical Achievements
- 4.1 Intellectual Skills and Technology as Source Domains: Introduction
- 4.2 Writing, Reading, Counting: Basic Cultural Techniques (I 1 – I 7)
- 4.3 Inventions and Technology (I 8 – I 19)
- 4.4 Intellectual and Technical Achievements: Conclusion
- 5 Special Concepts of the World
- 5.1 Beliefs and Religious Ideas; Life and Death: Introductory Remarks
- 5.2 Folk Belief, Superstition, Religion (K 1 – K 16)
- 5.3 Birth and Death (K 17 – K 24)
- 5.4 Summary Remarks on Special Concepts of the World
- 6 Cultural Symbols
- 6.1 Symbols as Source Concepts: Preface
- 6.2 Animal Symbolism (L 1 – L 8)
- 6.3 Color Symbolism (L 9 – L 18)
- 6.4 Concluding Remarks on Cultural Symbols as Source Domains
- 7 Material Culture, Money and Living
- 7.1 Widespread Idioms and Material Culture: Preliminary Remarks
- 7.2 Money, Trade and Commerce (M 1 – M 10)
- 7.3 Food, Clothing and Housing (M 11 – M 23)
- 7.4 Material Culture, Living and Money: Conclusion
- 8 Forces of Nature, Weather, Plants and Animals
- 8.1 Nature as a Source Domain: Introduction
- 8.2 Natural Forces and Weather (N 1 – N 17)
- 8.3 Plants, Animals and Animal Behavior (N 18 – N 26)
- 8.4 Additional Remarks on Natural Forces, Plants and Animals
- 9 Time and Space
- 9.1 The Temporal and Spatial Dimensions as Source Domains: Introduction
- 9.2 Time, Day and Hour (O 1 – O 12)
- 9.3 Spatial Extent, Distance and Resistance (O 13 – O 21)
- 9.4 Time and Space: Conclusions
- 10 Gestures, Postures and Facial Expressions
- 10.1 Nonverbal Communication as Source Domain: Preliminary Remarks
- 10.2 Semiotized Gestures (P 1 – P 10)
- 10.3 Body Postures and Facial Expressions (P 11 – P 17)
- 10.4 Concluding Remarks on Gestures, Postures and Facial Expressions
- 11 Physical Reactions and Sensation
- 11.1 Body-based Feelings and Reactions as Source Domains: Preliminary Remarks
- 11.2 Bodily Reactions (R 1 – R 8)
- 11.3 Pain, Soreness and Relief (R 9 – R 18)
- 11.4 Physical Reactions and Sensations: Conclusion
- 12 The Human Body
- 12.1 Introduction to Somatic Figurative Units
- 12.2 Conceptualization of HEART, HEAD, NERVES and SKIN (S 1 – S 7)
- 12.3 HAND and the FACE with Its Parts (S 8 – S 20)
- 12.4 The Human Body: Concluding Remarks
- 13 Textual Sources from Ancient, Medieval and Modern Times—Supplement to “WI Volume I”
- 13.1 Intertextuality as Source Domain: Introduction
- 13.2 Textual Sources of Ancient Times (T 1 – T 6)
- 13.3 The Bible as Source (T 7 – T 16)
- 13.4 Post-classical Proverbs, Narratives and Literary Works (T 17 – T 25)
- 13.5 Concluding Remarks on Textual Sources
- 14 Quotations, Terms and Views of Recent Modern Times
- 14.1 Quotes and Concepts of Recent Modern Society as Sources:Introduction
- 14.2 From the 19th Century to World War II (U 1 – U 9)
- 14.3 After World War II (U 10 – U 18)
- 14.4 Quotations and Terms of Modern Times: Conclusions
- 15 Conclusions and Main Results
- 15.1 Suggestions for Future Work
- 15.2 Widespread Idioms from an Areal Perspective
- 15.3 Source Domains and Intertextuality
- 15.4 Possible Causes of the Wide Dissemination of Idioms
- 15.5 Outlook
- References
- Abbreviations of the Language Names
- Maps
- Documentation Texts
- Indexes
- List of Maps
- Index of Literary Works, Movies, Pieces of Music and Art
- Alphabetical Listing of the English Widespread Idioms
- Index of Further Figurative Units
- List of Metaphors
- List of Widespread Idiom Candidates
- Subject Index
- Name Index
- List of Participants
- European Languages
- Non-European Languages
- Series index
This book may be seen as a continuation of the volume Widespread Idioms in Europe and Beyond from 20121 although it also clearly differs from it. While working on that book, i.e. on idioms that occur in a large number of languages in almost the same lexico-semantic structure (I call them widespread idioms), it soon turned out that the data I collected would be too extensive to be treated in a reasonable and sound way in a single book. Choices would have to be made. I had to think about how to shorten the data and which of the 300 widespread idioms I had identified by that time might be less interesting, which of them could be disregarded and excluded. Instead, I decided not to cut at any point but to write two books. After this decision was made I intensified my work on those idioms that can be derived from an identifiable text. In the previous volume (2012), a total of 190 widespread idioms were studied which can be traced back to texts from antiquity, from the Bible, from fables, fairy tales, folk narratives, and from popular and world literature.
At the same time, the search for further widespread idioms of European languages continued. My aim was to capture as many widespread idioms as possible and I hoped to achieve certain completeness. In this, however, I did not fully succeed: although I now have an inventory of more than 500 widespread ← 1 | 2 → idioms there will be still a few more of them—to anticipate an important result of my study. In the present book I examine 280 newly determined widespread idioms. For “WI Volume I” I chose the subtitle Toward a Lexicon of Common Figurative Units. In the present book, Lexicon of Common Figurative Units is the main title. This means that both books belong together and a total of 470 widespread idioms is now being made available for further research—presented in the form of a “Lexicon”—a reference work and an inventory of idioms that are spread Europe-wide and beyond.
Most of the newly identified widespread idioms cannot be attributed to a particular textual source. I had to choose a different principle of arrangement for these idioms. They are grouped primarily according to the source concepts from which they originate. In various cases, it was not enough to start from the image that is currently evoked by the literal reading of an idiom, but I had to clarify its origin in a broader cultural and historical context. This resulted in other problems and questions. For this reason alone, the present book differs significantly from its predecessor. Again, most results came as a real surprise.
In order to group the idioms according to their origin or source domains and underlying images I let myself be guided by the collected widespread idioms alone, not by a scheme which comes from the outside. The first Chapter, the “Introduction,” is followed by a thirteen-chapter documentation of the idioms. The first part, chapters 2–7, directly adjoin “WI Volume I”—not because the idioms originate in certain text passages (which may be well-known through cultural contexts) but because the idioms have their origin in other aspects of human culture. The idioms of chapters 8–12 come from domains that do not primarily belong to “culture” though all of them are culturally determined as well. Chapters 13 and 14, again, adjoin “WI Volume I” since most of the idioms are rooted in intertextuality.
Chapter 2 begins with idioms that can be traced back to artistic genres such as theater, performing arts, and music to which I added the frames sports and games due to the common factor entertainment. Chapter 3 shows that history, historical events and the actions of historical persons from antiquity through the Middle Ages to modern times are an outstanding source domain of widespread idioms; it is linked to the domains of power and armed conflicts. Chapter 4 is divided into sections on culture techniques (the skills of writing, reading and arithmetic) and technical achievements and inventions as source domains of widespread idioms.
Early pre-scientific conceptions of the world which were popular in ancient times but have been rejected in the course of history left clear traces in the Lexicon of Common Figurative Units. Chapter 5 deals with them in two sections ← 2 | 3 → which seem to be heterogeneous, but only at first glance: idioms reflecting folk models of supernatural powers and popular belief, especially the devil, and idioms which go back to images of birth and death. Chapter 6 is devoted to cultural symbols in widespread idioms; they can be found in the areas of animal and color symbolism. In the chapters mentioned so far, aspects of social and mental culture are in the fore. They are followed by a chapter on aspects of material culture: the source domains of the idioms to be discussed in Chapter 7 are money, finance and trade, on the one hand, and everyday material culture as it manifests itself in the basic human needs food, clothing and housing, on the other.
NATURE in a broad sense is richly represented in the Lexicon of Common Figurative Units. The idioms of Chapter 8 reflect people’s experience with FORCES OF NATURE and WEATHER PHENOMENA as well as PLANTS and ANIMAL BEHAVIOR. The subject of Chapter 9 is TIME and SPACE as source concepts of widespread idioms. A large group of widespread idioms come from the source domain THE HUMAN BODY; I discuss them in three chapters: Chapter 10 covers idioms whose underlying imagery is based on GESTURES, FACIAL EXPRESSIONS and POSTURE, Chapter 11 deals with idioms from the images of PHYSICAL REACTIONS and SENSATIONS, while specific body part constituents are the topic of Chapter 12.
Chapter 13 is an exception. It is designed to complement the previous book “WI Volume I” since 25 of the newly identified widespread idioms primarily go back to well-known text sources (ancient and biblical texts, folk narratives, post-classical literature). Here, I follow the arrangement principle of “WI Volume I”. Chapter 14, the last chapter of the documentation, belongs to a more modern layer. It also deals with intertextuality (quotations from prominent people which turned into idioms in a number of languages) and with figurative units of a terminological character which refer to states of affairs of the recent present, partly under the influence of English. A summary of my results and an attempt to find out the reasons why it is precisely these idioms that constitute a Lexicon of Common Figurative Units can be found in Chapter 15.
Many people have contributed greatly to the development of this book, and I would like to express my heartfelt thanks to all of them. First and foremost, a most sincere note of gratitude should be given to my magnificent and reliable respondents. All of them were kind enough to work on a voluntary basis. They are mentioned by name with great thanks at the end of the book. It is only due to their native speaker idiom competence and their conscientious and careful work that this second Volume of the Lexicon of Common Figurative Units can be published in the present form. ← 3 | 4 →
My participants were involved in the work on the “Lexicon” in different ways. At the initial stage it was about filling in numerous pre-test questionnaires until gradually it became clear which idioms could be widespread and should be evaluated by means of additional surveys. For most of the major standard languages quite a number of experts offered their participation, filled in a seemingly endless amount of questionnaires and compared their results with each other. For some languages, however, only two persons or even one person alone did almost all the work and answered many questions over the years (as can be seen in the list of names at the end of the book). Finally, several participants took the trouble to once again examine the final texts in view of the idioms of their native languages.2 All of them deserve my sincere thanks.
My warm thanks also go to Wolfgang Mieder, who included the book in the “International Folkloristics” Series. I am especially grateful to Ian Mackenzie for his invaluable cooperation. Although he occasionally pays lip service to “English as a lingua franca,” he took the trouble to correct and revise stylistically the English language of the entire book.
On the title page of the book there is still another name: there it says “In cooperation with József Attila Balázsi”. This is actually an understatement. It is almost impossible to summarize in a few words of thanks his wonderful contribution to this book. József Attila Balázsi evaluated the entire manuscript and enriched it with his insightful remarks; he checked all the empirical data, the literal translations of the idioms and much more. With his knowledge of a large number of languages he helped greatly to avoid numerous mistakes. My heartfelt thanks go to him for this commitment of long duration. The responsibility for all remaining errors, however, is entirely mine.
This book together with its predecessor should be seen as a first step toward an even more extensive study of figurative units common to many European languages and beyond.
Elisabeth Piirainen
Steinfurt, Germany
January 2016
1. Cf. Piirainen (2012a). Below I refer to this book by the abbreviation “WI Volume I”.
2. The languages are Albanian, Armenian, Belorussian, Bulgarian, Finnish, French, Greek, Hungarian, Irish, Latvian, Maltese, Polish, Russian, Slovene, Spanish, Swedish, Tatar and Ukrainian. The names of the respondents are placed at the end of the List of Participants of the languages in question.
1.1 Objectives and Terminology
Similarities among a variety of European languages—even geographically and culturally distant languages—have been well-known for a long time. They have been studied in the framework of renowned large-scale multilingual European research projects at different linguistic levels, be it phonetics/ phonology, morphology, syntax or lexis. The level of the figurative lexicon, however, has almost entirely been excluded from Europe-wide linguistic studies for a long time. Phraseology research produced comprehensive work on cross-linguistic comparisons of figurative units but opened to a Europe-wide approach only recently. The book “Widespread Idioms in Europe and Beyond: Toward a Lexicon of Common Figurative Units”1 (2012) may be considered a first attempt to look at conventional figurative units in terms of the linguistic situation of Europe as a whole. It has been shown that the similarities in the realm of a figurative lexicon of European languages are much greater than previously thought. That book may be seen as a predecessor of the present study. ← 5 | 6 →
This book presents multilingual research on conventional figurative units which are spread across a large number of European languages in a similar lexical structure and figurative core meaning. I coined the term widespread idioms (abbreviated WIs) for these particular figurative units. The results presented in this book go back to the large-scale project “Widespread Idioms in Europe and Beyond”. In Section 1.2, I briefly outline this project and its theoretical foundation and look at the definition of the term widespread idiom.
But first I must explain why I prefer the term figurative lexical unit to phraseme or phraseologism for the object-language units discussed in this book. Firstly, the definition of the latter terms requires the criterion of polylexicality. Phrasemes must consist of more than one word. This term is unsuitable for a multilingual approach, as a figurative multiword unit of one language may well correspond to a figurative one-word unit, e.g. a compound of another language. Secondly, the terms phraseme or phraseologism are too broad: they also comprise non-figurative multiword units (e.g. light verb constructions) which do not belong to the subject of this book.
The definition figurative lexical unit involves the following criteria: Firstly, figurative lexical units are conventionalized. They are elements of the mental lexicon. Their form and meanings are fixed (within a certain standard variability), that is, they are lexicalized—in contrast to freely created figurative expressions, e.g. poetic or ad hoc metaphors which are not retrievable from the lexicon.
Secondly, there is the feature of imagery or figurativity. Figurative lexical units consist of two conceptual levels: they can be interpreted at the level of their literal reading and the level of their figurative meaning—which both can be activated simultaneously. In most cases, the primary reading (source concept) is connected with fragments of world knowledge and evokes a mental image that may influence the idiom’s figurative meaning (target concept).2
Idioms are the prototypical units of the group of figurative lexical units. For the sake of simplicity I will use the term idiom instead of the laborious figurative lexical unit (or conventional figurative unit) in most cases—except where the figurative unit of a given language is just not an idiom but, for example, a compound. Figurative lexical units like idioms and figurative compounds differ ← 6 | 7 → from non-figurative units (i.e. from all other linguistic units) by their semantic ambiguity (their two conceptual levels). I will return to these specifics of figurative units when it comes to uncovering the causes of their wide dissemination (see Section 15.3 below).
Starting from the English versions, all of the 280 widespread figurative lexical units I analyze in this book can be subsumed under the term idiom in a broad sense. These units belong to several subgroups of idioms, which will be briefly outlined here. We have to distinguish between idioms functioning as a part of a sentence (so-called word idioms) and idioms with a sentence structure (sentence idioms). The subdivision of the former group follows the grammatical categories or syntactic functions of these “word equivalents” (i.e. verb idioms, noun idioms, adverbial idioms, and adjective idioms). Let me illustrate the subcategories by some examples.
Verb idioms with about 180 units are the largest group; examples are:
(G 17) to have an ace up one’s sleeve, (H 28) to be sitting on a powder keg, (I 16) to give sb. the green light, (K 11) to draw the short straw, (M 13) to put all one’s eggs into one basket, (N 18) to shoot up like mushrooms, (O 1) to kill time, (P 1) to take off one’s hat to sb., (R 1) to tighten one’s belt, (S 4) to lose one’s head, (T 3) to be frightened of one’s own shadow, (U 16) to vote with one’s feet.
Some of them are predicative verb idioms which cannot be quoted in the infinitive form, such as (K 23) sb. would turn in his/her grave, (N 21a) sb.’s mouth waters or (O 12) sb.’s last hour has come.
Noun idioms with about 45 WIs are the second largest group, for example:
(G 14) a race against the clock, (H 13) Potemkin villages, (I 7) the squaring of the circle, (K 10) the irony of fate, (K 13) a black day, (L 11) a dark chapter, (M 14) a hard nut to crack, (N 4) a drop in the ocean, (N 5) the last drop that makes the cup run over, (U 1) the opium of the masses.
Here, some comments are required. Firstly, most of the noun idioms can turn into verb idioms when a non-obligatory verb, mainly to be is added: (L 8) (to be) a busy bee, (T 7) (to be) a fig leaf for sth., etc. Secondly, as mentioned above, equivalents of an English noun idiom can be one-word compounds in the more synthetic languages, for example (H 25) cannon fodder vs. German Kanonenfutter, (K 8) old wive’s tale vs. German Altweibergeschichten, (L 7) at a snail’s pace vs. Finnish etananvauhdilla or (U 5) flea market vs. German Flohmarkt. ← 7 | 8 →
Thirdly, among this group we encounter several two-component nominal units of a terminological character which came into being in US English shortly after World War II.3 Their special features are that only one of the two elements is used in a figurative sense and that they—like a term—denote a particular matter of modern political and economic life and do not show far-reaching metaphorical extensions (like many other idioms do), for example: (L 14) black market, (L 16) gray area, (U 3) Banana Republic or (U 7) soap opera. These two-component units penetrated other languages as Anglicisms. This category does not exist among the idioms of the previous “WI Volume I”.
Adverb idioms are represented with about 20 WIs, most of which are used in the function of a temporal or local adverb, more rarely in modal function, for example:
(O 3) from time to time, (O 4) now or never, (O 7) one fine day – (N 25) from a bird’s-eye view, (O 15) at the end of the world, (P 13) behind sb.’s back – (I 1) in black and white, (N 8) like a bolt from the blue, (S 1) from the bottom of one’s heart.
Again, this assignment can be changed by adding a verb: (P 12) (to walk) with one’s nose in the air, (S 9) (to have sth.) at first hand, (S 14) *(to talk to sb.) between four eyes.4
Adjective idioms are generally very rare. They are mostly used in predicative position together with the verb to be and thus cannot be distinguished from verb idioms. However, among the WIs there are various similes, i.e. adjective idioms with the specific structure of comparisons; for example:
(K 22) as silent as the grave, (L 4) as proud as a peacock, (L 8) as busy as a bee, (L 17) as white as snow, (N 2) as different as fire and water, (N 9) as quick as a flash.
Sentence idioms. My data include 24 widespread sentence idioms; here are some examples:
(G 20) the game is up/over, (H 29) the alarm bells are ringing, (K 9) if looks/eyes could kill, (K 14) that’s written in the stars, (N 7a) a lot of water will have flowed under the bridge, (N 12) the wind has changed, (O 18) all doors are open to sb. / every ← 8 | 9 → door is open to sb., (O 16) it’s a small world / the world is small, (P 15) something is written on sb.’s forehead, (R 13) the ground becomes too hot under sb.’s feet, (S 19) have you swallowed your tongue?, (T 13) the measure is full, (T 22) your wish is my command, (T 23) the tail is wagging the dog.
The main communicative function of sentence idoms is commenting on a particular situation. Because of this feature, they differ from proverbs which also have sentence structure, but do not comment on a specific situation. Proverbs are general statements that are believed to express a universal truth. Proverbs are not considered in this book. But there are some borderline cases, such as the figurative unit (K 4) the devil is/lies in the detail, which could also be regarded as a proverb.
1.2 Widespread Idioms in Europe and Beyond: The Empirical and Theoretical Approach
In view of the interlingual similarities and differences of idioms, two opposing overgeneralizations can be found. In certain research traditions, idioms were considered to be a highly distinctive—if not the innermost—part of a language, which led to the idea that idioms were unique to a particular language, had no parallels among the idioms of other languages, and even provided the basis for an “idiosyncratic worldview”, like a mirror of national culture or mentality (cf. works of Russian linguo-cultural research, e.g. Teliya et al. 1998). This overlooked the fact that no language community—in any region at any time—can be equated with a people, a nation or a cultural community. Such an idea is based on the biased assumption that linguistic and cultural features develop in parallel ways. However, the emergence of idioms in a given language and the development of a mentality do not represent parallel processes.
Later, lexico-semantic similarities of idioms of different languages were occasionally observed and an opposite overgeneralization can be found in works that are quick to label idioms found to be parallel in a mere three or four languages as Europeanisms or even universals. In phraseology research, the term internationalism is well-known. It is often used for idioms which have their origin in the Bible or antiquity, for example, in Greek mythology, but the same term is also explicitly explained as the occurrence of an idiom in three or four languages (representative of a number of studies is Mokienko 1998, among others). What both kinds of overgeneralization have in common is a narrow data base (the small number of languages analyzed) and a lack of ← 9 | 10 → a theoretical foundation and definitions. It is unacceptable to speak of idiosyncratic idioms or international idioms without a systematic empirical data collection from a large number of languages.
The starting point of this book and its predecessor “WI Volume I” is the long-term project “Widespread Idioms in Europe and Beyond” whose beginnings date back to the year of 2005. The first aim was to develop an empirical basis to be able to answer questions regarding the commonalities of idioms across a variety of languages based on reliable data, collected as completely as possible. Extensive empirical groundwork has been done, relying on the assistance of native speakers of many languages. The main objective was then to identify as many widespread idioms as possible by means of systematic investigation—with the goal to create a “Lexicon of Common Figurative Units”. Let us have a brief look at the main steps of collecting the linguistic data and the theoretical foundation of this “Lexicon”.
Empirical approach
To collect the data I chose the correspondent principle, that is, a survey using questionnaires. I built up a network of competent respondents who filled in a large number of questionnaires for idioms of their native languages; see the list of participants at the end of the book. At the initial stage they evaluated a wealth of preliminary tests until, little by little, it became clear which idioms could be widespread and should be explored more extensively. The collected idioms were constantly checked for accuracy with the help of other native speakers.
However, one problem was that the information given by the respondents could be contradictory: an idiom considered by one speaker as part of their own language may be rejected as a “literal” or loan translation by another. This dilemma can be encountered wherever a language is in close contact with another one or with several languages.5 It has been reported for Irish and Maltese, among other languages, whose speakers often cannot decide whether a given idiom should be seen as a calque or loan translation from English. In ← 10 | 11 → many cases this problem has been solved by text corpus analyses and investigations on the Internet.
It is a well-known fact that an idiom that is well known to one speaker may be unknown to another. The scope of each speaker’s idiom lexicon varies over time: certain idioms are learned, others are forgotten. Among the WIs, there are idioms which are less familiar, even dated or obsolete in some languages, though they are not completely unknown. This does not affect the status of being widespread.
I decided to include all European languages which were accessible to my research. This resulted in 78 European languages which are now included in the project (see Section 1.3 for details).
Theoretical foundation
In “WI Volume I”, pp. 59–72, I expounded the theoretical foundation of the “Lexicon of Common Figurative Units”. Because the term widespread idiom is being newly introduced to linguistics, I had to create a working definition first. This definition must be based on criteria by which actual widespread idioms in Europe and beyond can be distinguished from other figurative units that exist in some four, five or more languages. The definition is the following:
Widespread idioms (WIs) are idioms that—when their origins and particular cultural and historical development is taken into account—have the same or a similar lexical structure and the same figurative core meaning in various different languages, including geographically distant and genetically unrelated ones.
The definition includes the following six criteria:
(i) Idiom equivalents must exist in geographically distant languages (not only in languages of a restricted area where languages are in close contact with each other).
(ii) Idiom equivalents must exist in genetically unrelated languages (not only in languages of a few closely related language families).
(iii) Idiom equivalents must show the same or a similar lexical structure (which evokes the same or a similar image). Cases are included where differences of the lexical structure are due to the individual development of an idiom of a given language. ← 11 | 12 →
(iv) Idiom equivalents must share the same figurative core meaning. Cases are included where differences of the figurative meaning are due to an individual development of an idiom of a given language.
(v) An idiom of a given language may have changed its lexical structure in the course of history so that criterion (iii) does not apply: this individual development needs to be considered and criterion (iii) can be modified accordingly.
(vi) An idiom of a given language may have changed its figurative meaning so that criterion (iv) does not apply: historic-cultural development needs to be considered and criterion (iv) can be modified if necessary.
Criteria (i) and (ii) are not based on linguistic features but on factors concerning the linguistic situation of Europe, with its genetically diverse languages between the Atlantic and the Ural Mountain Range (cf. Section 1.3 for details). Criteria (iii) and (iv), however, result from the characteristics of the semantics of idioms. As outlined above (1.1), idioms differ from non-figurative units with respect to their semantic ambiguity: they belong to the two conceptual levels of their literal meaning, fixed in the lexical structure, cf. (iii), and their figurative meaning, cf. (iv). These last two criteria may be restricted and modified by criteria (v) and (vi) which are related to historical and cultural factors.
Each idiom has its own history and may have undergone individual changes in wording and meaning. The definition criteria take into consideration the fact that idioms are linguistic signs that are handed down historically and coined culturally. The broad concepts of “similarity” both at the level of literal meanings and at the level of figurative meanings leave room for an interpretation of each individual case within its historic-cultural development. In the course of history, both the literal and the figurative meaning of idioms of the same origin can be affected by changes that are unique to one individual language. Elements of the source concept are subject to modification; they may be adapted, for example, to environmental or more modern conditions. In the same way, the target concept of an idiom of an individual language may undergo changes when, for example, certain relevant features are highlighted and others are suppressed. Such cross-linguistic lexical-semantic differences do not affect the WI status as a whole.
I use these six criteria, which in part qualify each other, for the identification of widespread idioms. They enable me to distinguish those idioms that are actually widespread from phenomena that merely look similar. Geographical and cultural-historical factors as well as the semantic specifics of idioms all play an equally important part in the definition of widespread idioms. ← 12 | 13 →
1.3 The Languages of the Project
As the subtitle of the book, “Widespread Idioms in Europe and Beyond” suggests, the focus is primarily on idioms of European languages—and in addition also on a few languages “beyond Europe”. I had to limit myself to a subset of languages, and the languages of Europe, more precisely those that are accessible for idiom research offered a manageable group for this.6 Europe has no clear boundaries, neither geographically nor culturally. There are various definitions of Europe: depending on the objectives and contexts in which they are used, they accentuate geographical, historical, political, or cultural aspects. For my study, the geographical definition of Europe proves to be practical, thus following the custom of most Europe-wide linguistic studies. According to this definition, Europe extends eastwards as far as the Ural Mountain Range and includes the Caucasus region.
Some of the languages I analyzed belong to both the European and the Asian continent (e.g. Turkish) or cannot be clearly assigned to one of them (e.g. Armenian), while other languages have more speakers beyond the boundary (e.g. Kazakh). All this is no reason to exclude these languages from my study. There can be continua of widespread idioms, from Europe to the Arabic dialects of Northern Africa and from Europe to the languages spoken in the Eurasian border area. Therefore, the focus of the “Lexicon of Common Figurative Units” is not only on Europe, and the addition and Beyond is an important component of the title of this book.
Seventy-eight languages or linguistic varieties spoken in Europe are represented in the project, including about 40 well-established standard European languages and about 32 smaller languages which can be roughly subsumed under the socio-linguistic term lesser-used language; in addition, there are a few languages which cannot be clearly assigned to one of those two groups. I also included Esperanto in the project and—to varying degrees—16 languages spoken outside of Europe.
All six European language families and Basque are represented in the project. Indo-European with 58 languages is the biggest group, followed by eleven Finno-Ugric and six Turkic languages. In addition, one Caucasian and one Semitic language are included in the project. Here follows an overview of ← 13 | 14 → these languages—in the same sequence as the documentation of the idioms in Chapters 2–14 below.
Indo-European Languages in Europe (58)
Germanic (15): Icelandic, Faroese, Norwegian,7 Swedish, Danish, English, Scots, North Frisian,8 West Frisian, Dutch,9 German, Luxembourgish, Yiddish, Low German10 and Swiss German.
Celtic (5): Irish, Gaelic, Welsh, Cornish and Breton.
Romance (17): French, Romansh, Francoprovençal, Ladin, Provençal, Occitan, Friulian, Venetian, Italian, Sardinian, Spanish, Catalan, Galician, Mirandese, Portuguese, Romanian and Aromanian.11
Baltic (2): Latvian and Lithuanian.
Slavonic (16): Russian, Belorussian, Ukrainian, Polish, Kashubian, Upper Sorbian, Lower Sorbian, Czech, Slovak, Slovene, Croatian, Bosnian, Montenegrin, Serbian, Macedonian and Bulgarian.
Albanian,12 Greek and Armenian13 (isolated Indo-European languages).
Finno-Ugric Languages in Europe (11)
Ugric: Hungarian.
North-Finnic: Finnish, Estonian, Karelian and Veps.
Permic: Udmurt and Komi-Zyrian.
Volgaic: Mari, Moksha Mordvin and Erzya Mordvin.
Saamic: Inari Saami.
Turkic Languages in Europe (6)
Northwestern Common Turkic languages: Karaim, Tatar, Bashkir and Kazakh.
Southern Common Turkic languages: Turkish and Azerbaijani.
Caucasian Language
Georgian (belonging to the South Caucasian or Kartvelian languages) ← 14 | 15 →
Semitic Language
Maltese (belonging to the Semitic subgroup of the Afro-Asiatic languages).
Basque (an isolated language).
Map 1 shows 76 of the 78 European languages that are included in the project. The abbreviation Sor in the eastern part of Germany stands for two languages: Upper Sorbian and Lower Sorbian. Yiddish cannot be depicted on the map due to its ubiquity across various regions. The map is schematic: it does not show the distribution of languages as such but their occurrence. The smaller or lesser-used languages are depicted by a smaller rectangle than the major languages.
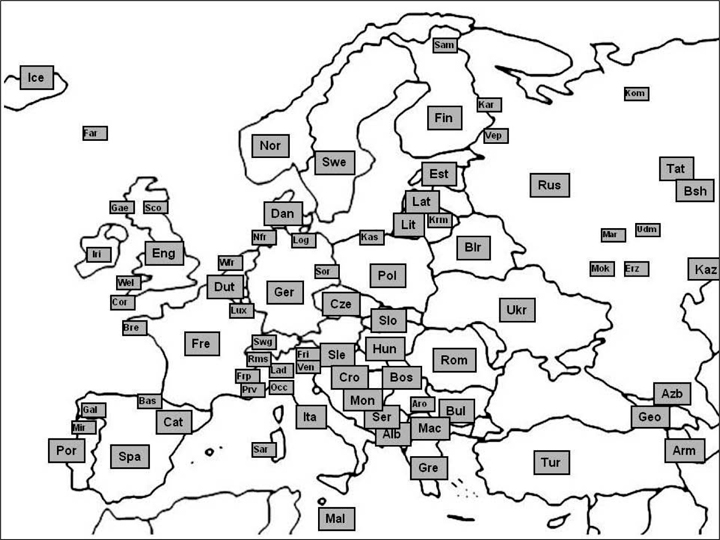
Map 1: Languages of the project “Widespread idioms in Europe and beyond.”14
I tried to collect complete data for the standard European languages wherever possible. For a number of the smaller languages, however, this was not within my capabilities, for several reasons. In general, it was difficult to find competent participants for the endangered and declining languages and motivate ← 15 | 16 → them to contribute to the project with their knowledge of idioms. In particular, these speakers often were not sure whether they might have used a loan translation of an idiom from the roofing major language or whether the idiom in question really existed as a conventionalized figurative unit of their own native linguistic variety. This dilemma is not limited to the lesser-used languages. However, it was especially encountered for Irish and other Celtic languages, for Galician, Maltese, Basque, and most of the Finno-Ugric and Turkic languages spoken in Russia.
Here follows an overview of the lesser-used languages which are included in the project—in the same sequence as the language families mentioned above. The question of whether these varieties are defined as dialects or small regional languages on their own can be disregarded here.
I start with the Indo-European subfamilies: Lesser-used Germanic languages are: Scots, North Frisian, West Frisian, Low German and Swiss German. For Luxembourgish and Yiddish see below.
All five Celtic varieties, Irish, Scottish Gaelic, Cornish, Welsh and Breton must be classified as endangered minority languages—despite partly successful revitalization efforts.
Among the Romance languages, Romansh, Francoprovençal, Ladin, Provençal, Occitan, Friulian, Venetian, Sardinian, Mirandese and Aromanian are lesser-used, partly declining varieties. For Catalan and Galician see below.
Three endangered Slavonic varieties are part of the project: Kashubian, Upper Sorbian and Lower Sorbian.
Only three of the Finno-Ugric languages that I analyzed are standard languages (Hungarian, Finnish and Estonian). All other varieties can be counted among the endangered languages of oppressed minorities: Karelian and Veps (North-Finnic), Udmurt and Komi-Zyrian (Permic), Mari, Moksha Mordvin and Erzya Mordvin (Volgaic) and the Saamic variety Inari Saami.
Of the Turkic languages in Europe, only Karaim is highly endangered or nearly extinct. For the status of Tatar and Bashkir see below.
While Georgian and Maltese are standard languages, the isolated Basque is a lesser-used and partly endangered language.
Despite the difficulties I mentioned above, several lesser-used languages are particularly well documented in my project. This is mainly due to individual ← 16 | 17 → researchers who filled in a large number of questionnaires, partly with support of Institutions of Regional Studies.15 These languages are: North Frisian, West Frisian, Swiss German, Irish, Breton, Romansh, Mirandese, Aromanian, Kashubian, Upper Sorbian, Lower Sorbian and Basque. The data of the other lesser-used minor and minority languages—among them several Romance and especially the Finno-Ugric languages—could not be collected as comprehensively.
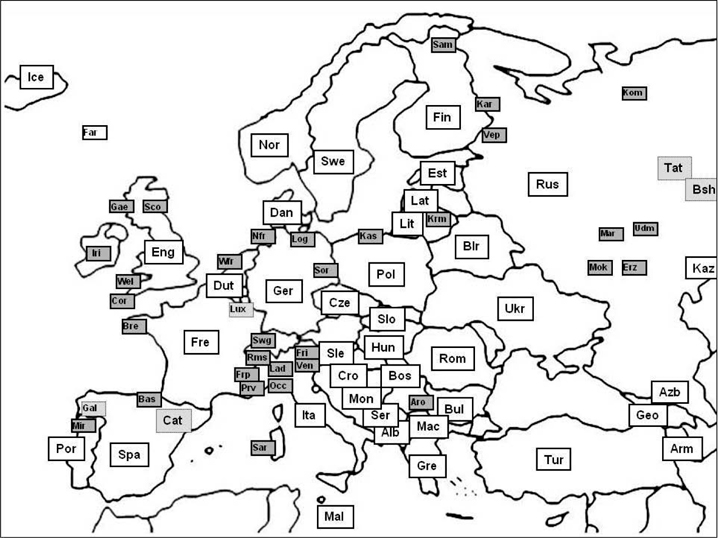
Map 2: Lesser-used languages of the project “Widespread idioms in Europe and beyond.” ← 17 | 18 →
Map 2 shows 40 white rectangles which stand for the major languages. The 31 dark gray rectangles mark the lesser-used varieties.16 Five more languages are depicted on light gray rectangles. These cannot be clearly assigned to either the standard languages or the lesser used varieties. The status of Luxembourgish cannot be clearly evaluated. It is no minority language but still lesser-used—being a national but not an official language. The status of Catalan (a co-official language in Catalonia) and Galician (co-official in Galicia) is not clear either; currently, they are developing languages.
The situation with Tatar and Bashkir is different. Despite a large number of speakers, these languages are strongly under pressure from Russian (cf. Gizatova 2015), as is the case with the declining Finno-Ugric languages mentioned above, where intergenerational transmission is not guaranteed. This manifests itself most clearly in the realm of figurative units: “They start to vanish at the very beginning of a language becoming endangered” (Idström/Piirainen 2012a: 18).
The data of the European languages are complemented by Esperanto, a constructed auxiliary language spoken in Europe and world-wide, and 16 non-European languages. The Arabic dialects (Algerian Arabic, Tunisian Arabic, and Egyptian Arabic) are represented differently in my data, Tunisian being the most common. Six Asian languages, Hindi, Mongolian, Chinese, Vietnamese, Korean and Japanese contributed quite a number of idioms to my collection of widespread idioms while seven further languages are represented only by a few idioms: Farsi (Persia), Bété (Ivory Coast), Mansi and Khanty (Siberia), Thai (Thailand), Aklanon (Philippines) and Māori (New Zealand).
For more details about the languages which are represented in the project and about the linguistic situation in Europe reference should be made to Sections 4.2 and 4.3 of “WI Volume I”, pp. 76–89. Since the publication of that book seven languages have been added to the project. There are two new Romance varieties: Friulian, a minority language spoken in the Friuli-Venezia Giulia region of Northeast Italy, closely related to Ladin, and Mirandese, a small variety spoken in North Portugal. Also two Slavonic languages joined the project: the highly endangered West Slavonic variety Lower Sorbian and the South Slavonic language Montenegrin which is closely related to Croatian, Bosnian and Serbian. Another Turkic language is now represented in ← 18 | 19 → the project: Bashkir, belonging to the southern branch of the Common Turkic languages.
In addition, two non-European languages found their way into the project: Hindi, an Indo-European language spoken in India proved to possess quite a number of equivalents of the European widespread idioms,17 while Māori (an Eastern Polynesian language spoken by the indigenous people of New Zealand) contributed only one single parallel idiom to the data of the present book (cf. WI (O 15) below).
1.4 The Macrostructure of the “Lexicon of Common Figurative Units”
The arrangement principles of widespread idioms of “WI Volume I” were defined by the underlying texts which also allowed a chronological order: starting with Greek and Roman works of literature and the Bible I continued with post-classical, medieval and more recent popular writings—without separating idioms that belong together. Such structuring is not possible for the idioms of this book and I had to look for another way to present them coherently in the form of a “Lexicon”. The obvious thing to do would be to start from the main idiom constituents (usually the first nominal constituent) and either list the idioms alphabetically or group them into “thematic groups”, according to the domains to which the constituents outside of idioms belong.
Both approaches, however, would result in separating idioms which belong together and bringing together items that have nothing to do with each other, as some examples may show. Among my data there are two widespread idioms with the constituent navel. Outside of idioms, this is a term for a body part but neither of the idioms can be termed somatism (“body part idiom”). The first WI is (H 1) *the navel of the world (German der Nabel der Welt) where Greek mythology and history come together: navel alludes to the omphalos-stone, a cult object in the Temple of Apollo at Delphi, which was considered the geographical center of the earth. The idiom will be discussed together with other WIs originating from history of ancient times (to rest on one’s laurels, the eighth wonder of the world) and not together with “body part idioms”. The ← 19 | 20 → second idiom, (K 15) to gaze at one’s navel / to contemplate one’s own navel alludes to mystic practices as they are known from particular Buddhist sects of Central Asia in which the navel is venerated as the center of life and source of energy. This idiom has its place in the section about folk belief, superstition and religion, between WIs like that’s written in the stars and the/a sacred cow.
The figurative meaning of a widespread idiom must be included for the most part, when it comes to associating the idiom with a source domain. Let us look at two widespread idioms with the constituent belt which should not be subsumed under “garment idioms”. The first idiom clearly goes back to the domain of SPORTS: (G 9) a blow below the belt. As the figurative meaning ‘a mean or unfair attack; an ill-mannered, hurtful activity or remark’ reveals, it alludes to the rules of professional boxing, which were established in England in the 1870s (belt as waist belt of the athlete’s clothing). Idiom (R 1) to tighten one’s belt comes from a completely different image field. According to its figurative meaning ‘to make economies, live frugally and use fewer resources when food or money is scarce’, it is based on the bodily experience that there is a relation between living frugally and thinness (the belt which holds the pants when the body becomes thinner). I will discuss the idiom in a section along with other idioms of the source domain PHYSICAL REACTIONS.
As the examples show, I found another solution for a reasonably coherent arrangement of the data in the “Lexicon of Common Figurative Units”. I group the widespread idioms according to their “origins”. This is, in most cases, the source domain or imagery which can be derived from the idioms’ overall lexical structure and often retrospectively—in connection with their figurative meanings.
For most widespread idioms this way of arrangement proved to be without problems: most of them are motivated. This means that most speakers of the various languages of the project can activate certain knowledge structures to make sense of the use of a given idiom in the meaning conventionally ascribed to it.18 For example, idiom (N 11) the calm before the storm can be assigned to the source concept WEATHER PHENOMENA (exact observation of a particular atmosphere before the outbreak of a thunderstorm) and (N 22) to lick one’s wounds to ANIMAL BEHAVIOR (image of a dog or a cat licking an injured part of its body). ← 20 | 21 →
However, there are a few cases which need further explanation. It should be stressed that the “motivation” and “etymology” of idioms must not be equated.19 The starting point of my arrangement is “etymology” in the sense of the real cultural-historical origin—if there is a discrepancy between the synchronically evoked image (the mental representation) and the actual origin of an idiom. It was an important step of my study to determine the “true” etymology of individual idioms—as far as this was possible in accordance with the current state of research. In addition, the relationship with a certain text had to be taken into account in several cases. Let me illustrate some problem cases by means of examples.
(i) Folk etymology. The literal reading of an idiom has been reinterpreted in the course of history; cf. (H 16) to hit the nail on the head. The idiom seems to be motivated by the image of a hammer blow on the head of a nail. According to historical evidence, however, it originates from medieval archery, where the bowmen had to hit the nail of a target which was fixed in its center. Therefore, the idiom is classified in the area of MEDIEVAL FIGHTING and KNIGHTHOOD.
For a number of WIs I was able to rely on relevant reference books with regard to the idioms’ etymology. For some idioms, however, hardly any secondary literature was available (as for (T 18) I would not wish that on my worst enemy whose origin remains unclear). In other cases, there is an extensive literature. The origin of the WI (K 7) to give sb. (the husband) horns / to plant horns on sb., for example, can be clarified only in a broad cultural and historical context. Numerous studies have dealt with it, resulting in different hypotheses. In recent research, however, a consensus about its origin is becoming apparent.
(ii) Blending of source concepts. Similar to folk etymology, an underlying image can be interpreted in different ways, as is claimed for equivalents of (N 1) to be caught between two fires. For speakers of some languages the idiom is located in the area of WARFARE and FIREARMS because FIRE in the military sense cannot be disambiguated from ‘real fire’, but historical evidence is not as clear. I subsume the idiom under NATURAL FORCES (conflagrations coming from two sides) as is suggested by the relevant reference books. ← 21 | 22 →
(iii) Intertextuality.20 There are quite a lot of cases where I cannot decide whether an idiom should be grouped according to the source domain (the mental image) or rather a text it originates from. For example, the WI (T 14) to pull out the evil at the root is so obviously derived from the Bible that I refrain from classifying it on the base of its image (e.g. as a PLANT metaphor because of root). The same holds for (T 25) the little gray cells which proved to be a neologism by Agatha Christie, but also for (T 2) to stir up a hornet’s nest. The deep roots of the idiom in the literature of antiquity and the Middle Ages dominate the origin from ANIMAL BEHAVIOR as the underlying image would suggest. For such cases, I created Chapter 13 which should be seen as a supplement to “WI Volume I”.
Some WIs of Chapter 14, which deals with a more recent layer of widespread idioms, are also based on intertextuality: several idioms gained currency thanks to certain personalities (politicians and other public figures) who in their writings and speeches either used an idiom which was already in currency or coined these expressions themselves. Their statements may have contributed significantly to the dissemination of an idiom and also penetrated the figurative lexicon of various other languages, for example (U 16) the silent majority. However, a clear distinction is not always possible; an idiom which is considered as a quotation of recent times may in fact be much older. So it seems reasonable to treat the idiom (I 10) to roll back the wheel of history under TECHNICAL INVENTION along with other idioms from this area ((I 9) to reinvent the wheel, (I 11) to go/run like clockwork) although it owes its spread to a prominent quote.
The arrangement principles are an attempt not to separate widespread idioms that belong together. Various indexes at the end of the book provide searchability. The arrangement resulted in 13 documentation chapters in which most of the 280 newly identified WIs are grouped together under special source domains:
• THEATER, MUSIC, SPORTS and GAMES with subdomains such as stage production and performing arts, sports, playing and gambling (20 WIs; Chapter 2)
• HISTORY and WAR, including the subdomains: history of ancient times, history of medieval and modern times, fighting and knighthood in the Middle Ages, warfare and weapons of modern times (31 WIs; Chapter 3) ← 22 | 23 →
• INTELLECTUAL AND TECHNICAL ACHIEVEMENTS with the subdomains: basic cultural techniques (writing, reading, counting), inventions and technology (19 WIs; Chapter 4)
• SPECIAL CONCEPTS OF THE WORLD; subdomains are: folk belief, superstition, religion as well as birth and death (24 WIs; Chapter 5)
• Cultural symbols, including animal symbolism and color symbolism (18 WIs; Chapter 6)
• MATERIAL CULTURE, MONEY and LIVING; subdomains are money, trade and commerce as well as food, clothing and housing (23 WIs; Chapter 7)
• FORCES OF NATURE, PLANTS and ANIMALS with the subdomains natural forces and weather as well as plants, animals and animal behavior (26 WIs; Chapter 8)
• TIME and SPACE with subdomains such as day and hour, spatial extent, distance and resistance (21 WIs; Chapter 9)
• GESTURES, POSTURES and FACIAL EXPRESSIONS; subdomains are: semiotized gestures as well as body postures and mimics (17 WIs; Chapter 10)
• PHYSICAL REACTIONS AND SENSATION, including the subdomains bodily reactions and pain, soreness and relief (18 WIs; Chapter 11)
• THE HUMAN BODY; subdomains are: conceptualization of HEART, HEAD, NERVES and SKIN and HAND and the FACE with its parts (20 WIs; Chapter 12)
• Textual sources from ancient, medieval and early modern times—Supplement to “WI Volume I”: subchapters are: textual sources from ancient times, the Bible as source and proverbs, narratives and literary works (25 WIs; Chapter 13)
• Quotations, terms and views of recent modern times. Subchapters are: From the 19th century to World War II and After World War II (19 WIs; Chapter 14).
1.5 The Microstructure of the “Lexicon of Common Figurative Units”
In this volume, I use the same microstructure of the individual entries of the “Lexicon of Common Figurative Units” (Chapters 2–14) as in “WI Volume I”. Some widespread idioms will be presented in full length, in a “detailed version”. The data of most idioms, however, will be given in a shorter, space-saving way. Both types of entries consist of the following elements: ← 23 | 24 →
• Code number. This includes a capital letter and the continuous number. In “WI Volume I”, I used the letters A–F. The present volume is a continuation, so it begins with the letter G in Chapter 2 and continues up to the letter U in Chapter 14. The unity of the two volumes will be achieved in this way.
• Heading (in bold small capitals). This consists of the English idiom, or the most represented version if there are variants. If the idiom does not exist in English, a word-for-word translation of the German equivalent is used as a headline, marked with an asterisk and followed by the German equivalent and on occasion by an English near-equivalent. Sometimes two headings are required; see below for more details.
• Explication of the figurative meanings (in simple quotation marks). In this area, I summarize the core meaning of the idiom and—as far as possible—the most important semantic aspects of the idiom equivalents of individual languages. In rare cases, two meaning explications are given.
• Cultural foundation. Here, the source domain (the imagery) and the target domain (the figurative meaning) are put in relation to each other. Often an appropriate basis for comparison can be recognized. In addition, this part summarizes the current state of knowledge about the origins of the idiom, its connection with texts (its origin in an identifiable text or its use by prominent persons), i.e. its etymology to the extent possible and the probable causes for its wide distribution (see my remarks on “(iii) Intertextuality” in Section 1.4.
• References. All the works I used for the “Cultural foundation” are cited here in chronological order.
• Comment. This section summarizes the most important information retrieved from the data: on the distribution of idiom equivalents across the languages, lexical and morpho-syntactic variants, language-specific developments of the figurative meaning or pragmatic specifics in individual languages. Often, an idiom must be distinguished from near-equivalents which have to be excluded. The “detailed version” of the entry places the comment after the data.
• The data. The “detailed version” of the data presentation provides each idiom with its own line and a full literal translation (a word-for-word translation in double quotation marks): the aim is to make the far-reaching commonalities visible. Lexical differences—deviations from the majority of idioms—are highlighted in bold type in the literal translation. The long entry version also provides space for non-European equivalents and ← 24 | 25 → information on the lack of idiom equivalents in certain European languages, either summarized for an entire language family or listing them at the end of the documentation for a language family. This means that no equivalents were known to the respondents and that there are most probably no equivalents since the experts have usually carried out thorough research. Yet it cannot be fully excluded that an individual speaker would know an equivalent idiom if I asked a larger number of speakers.
The short version presents the data in a space-saving way: literal translations are not necessary in every case. I add translations to each idiom only if they cannot be summarized. I often use a description such as “The idioms translate literally as […] unless noted differently”, or I join two or more idioms which follow one another, if they have the same literal meaning. Some problems of the literal translations of the idioms have emerged. They can be based on dissimilar morpho-syntactic structures or lexical discrepancies between the languages, etc. I tried to solve such problems pragmatically: the result should be a correct and understandable English text.21
• The maps. The presentation of 32 widespread idioms (mostly of the “detailed versions”) is provided by cartographic representations. The idiom equivalents have been plotted onto the map of Europe so that areal and socio-linguistic aspects become visible: that is to say the distribution of equivalents across European languages, on the one hand, and the involvement of standard languages and lesser-used languages in constituting the widespread idiom in question, on the other.
Further details of the microstructure of the “Lexicon” were described in “WI Volume I” in detail, including issues of how to present idiom variants as they were given by the respondents (pp. 96–98), problems of the literal translations of the idioms (pp. 98f., see also footnote 21 below) and remarks on the writing systems I used, particularly for the non-European languages (pp. 99f). Some further problems which I touched on there only marginally will be discussed ← 25 | 26 → again briefly here: they all are related to the fact that I have to set up two headlines for the lexicon entries of several widespread idioms.
Firstly, there is the so-called systematic variation which manifests itself at the level of syntactic transformations.22 The problem was that the respondents did not consider these differences and sometimes reported both versions side by side, or just one version. Therefore, I had to choose two headings, for example: (R 2a) (not) to get gray hair from sth. and (R 2b) to make sb. get gray hair. Verbs like to get and to give tend to lead to the formation of such converse pairs of idioms which follows regular principles. Often, one of the two versions is so dominant across the languages that I can neglect the less common ones (e.g. (I 16) to give sb. the green light is more common than to get the green light).
Secondly, there are lexical “antonyms” both variants of which are equally widespread. In these cases I provide two headings even if I discuss only one version in detail. Examples are (G 6a) to play the first fiddle vs. (G 6b) to play the second fiddle, (H 14a) to throw down the gauntlet vs. (H 14b) to pick up the gauntlet or (P 16a) or to lose (one’s) face vs. (P 16b) to save (one’s) face. Finally, idioms with a negation led to two versions, e.g. (G 2a) to play a role / (G 2b) to play no role. The idiom (N 7a) a lot of water will have flowed under the bridge vs. (N 7b) *a lot of water has flowed under the bridge is a special case since the two idiom versions given in the headline give rise to two different temporal aspects at the level of the figurative meaning, and some languages have only one of the two variants.
What all these examples have in common is the fact that the two versions undoubtedly constitute one common widespread idiom. However, there are some borderline cases which cannot be clearly identified as belonging to one WI. This is actually a gradual phenomenon, ranging from widespread idioms maintaining a very consistent morpho-syntactic and lexical structure across a large variety of languages to those which are barely connected by correspondences at the abstract conceptual level. Let us look at an extreme case, the idioms (H 23a) to hold/put a gun/pistol to sb.’s head and (H 23b) to hold a knife to sb.’s throat. These are only two versions out of a larger variety, showing blends such as “to put a pistol to sb.’s throat”, “to put a knife to sb.’s breast”, and the like. The many versions can be subsumed under one widespread idiom ← 26 | 27 → only under the condition that they are indistinguishably joined together. What unites them is both a structural model [to put a gun to a vital organ] and their common figurative meaning ‘to exert great pressure on someone, to ultimately force them by using threats to act or to make a decision’.
The next step on the scale of common features would be idioms that can be joined together only because of a similar figurative meaning. This is a well-known approach in paremiology where the “proverb idea” is the overarching principle. For example, the proverbs No rose without a thorn, No land without stones and No meat without bones, on the one hand, and Dutch Wie de vis heft, moet ook de graat hebben “He who has the fish must also have the bone”, on the other can be put together in one dictionary entry (Cox 1988: Nr. 657) because they share the figurative meaning ‘there is nothing pleasant, positive, that does not include disadvantages or negative aspects’.
In my widespread idiom data, I encounter this phenomenon as well. My respondents liked to report equivalents that are lexically different from the basic version but show a similar structure and convey a very similar idea. For example, they noted lexically different idioms for the WI (I 8) *not to have invented the gunpowder ‘not to be very intelligent, to be rather silly, simple-minded’, such as Dutch het zwarte garen niet uitgevonden hebben “not to have invented the black thread”, French n’avoir pas inventé le fil à couper le beurre “not to have invented the wire to cut the butter”, Italian non avere trovato la carta da navigare “not to have discovered the nautical chart” or Basque kea asmatu ez “not to have invented smoke”. Although all idioms follow the same pattern [not—to have invented/discovered—X] I had to exclude them from the documentation of the data, but I list them in the footnotes for the most part. I will return to this phenomenon in Section 15.1 from the viewepoint of “suggestions for future work” and in Section 15.2. from an areal linguistic perspective.
In the documentation chapters 2 to 14 the collected idiom equivalents of many languages are presented in full length. Although this takes a lot of space, especially if the literal translations cannot be summarized, the data are not shortened. Only the presentation of the entire material reveals the extent of the wide dissemination and the commonalities of the idioms across the languages and allows an intense scholarly investigation to possibly draw conclusions.
1. Cf. Piirainen (2012a).
2. Compare the principles of the “Conventional Figurative Language Theory” developed by Dobrovol’skij and Piirainen 2005. See also “WI Volume I” pp. 31–34 for more details.
3. Compare Martí Solano (2013) among other things.
4. In this book, an asterisk preceding an idiom means that, despite being widespread across Continental European languages, it is not used in English; see 1.5 below.
Details
- Pages
- X, 778
- Publication Year
- 2016
- ISBN (Hardcover)
- 9781433129698
- ISBN (ePUB)
- 9781433139314
- ISBN (MOBI)
- 9781433139321
- ISBN (PDF)
- 9781453915288
- DOI
- 10.3726/b10457
- Language
- English
- Publication date
- 2016 (September)
- Published
- New York, Bern, Berlin, Bruxelles, Frankfurt am Main, Oxford, Wien, 2016. X, 776 pp.
- Product Safety
- Peter Lang Group AG
