
«Quo vadis, Kommunikation?» Kommunikation – Sprache – Medien / «Quo vadis, Communication?» Communication – Language – Media
Akten des 46. Linguistischen Kolloquiums in Sibiu 2011 / Proceedings of the 46th Linguistics Colloquium, Sibiu 2011
Summary
Quo vadis, Communication? Communication – Language – Media presents contributions of the 46th Linguistics Colloquium at the University of Sibiu, Romania. The essays offer a critical review of the influence of modern media on communication and how media have become the subject of research in different linguistic fields. The volume comprises papers in German, English and French from 30 different universities.
Excerpt
Table Of Contents
- Cover
- Titel
- Copyright
- Autorenangaben
- Über das Buch
- Zitierfähigkeit des eBooks
- Inhaltsverzeichnis
- Vorwort
- Plenarbeiträge/Invited Papers
- Ist das Deutsche demokratischer geworden? Von der Hochsprache zur Standardsprache
- Öffentlichkeit im digitalen Zeitalter: Umbruch oder Abbruch der gesellschaftlichen Kommunikation?
- Kontinuität im Wandel?
- Sur la situation de la langue dans la littérature contemporaine
- Referenten-Beiträge/Contributed Papers Medienlinguistik/Media Linguistics
- Lexikalische Subjektivität in der deutschen Presse am Beispiel von grinsen und lachen
- Textuelle Funktionen rekontextualisierter Werbeslogans
- Zur Thema-Rhema-Gliederung durch die Besetzung des Nachfeldes in deutschen journalistischen Texten
- Texte ohne Worte. Non-verbale Elemente in Pressetexten
- Mediale Metaphern aus der Sicht der Linguistik
- Wechselwirkung der Sprache und des Geschlechts in politischen Reden und Zeitungsinterviews
- Quo vadis Kommunikation? Die Medienlandschaft in Rumänien
- Stratégies discursives dans le billet d’humeur (Regard sur la presse française et roumaine)
- Les innovations lexicales basées sur les termes utilisés sur l’Internet
- The Contribution of 19th Century Transylvanian Press to the Development of Romanian Literary Language
- Das Wortbildungsparadigma „Wortbildungsnest“, dessen Nestglieder und Entfaltung zum ‚Nest-Netz‘ im journalistischen Text
- Pragmatik und Diskursanalyse Pragmatics and Discours Analysis
- Lexische Paradigmen und Textkonstitution
- Pragmatics and Gender-Related Metaphors Case Studies in an Online Corpus of Spoken Slovenian
- Herta Müllers Rhetorik der (Selbst-)Demütigung
- Europäische Identitäten in autobiographischen Erzählungen. Eine Betrachtung narrativer Codasequenzen mit europäischen Bezügen
- Diskurs und Wirklichkeit
- Discourse and Social Construction
- Festung EU: die Flüchtlingsproblematik im Spiegel der internationalen Presse – eine Diskursanalyse
- Mehrdeutigkeit auf der Textebene: Wann sind Texte mehrdeutig?
- Interkulturelle Linguistik Intercultural Linguistics
- Ausfahrt freihalten – Nu parcaţi! Performative Texte im interkulturellen Vergleich
- Das Konzept „russische Seele“ in den modernen deutschen Medien und seine Transformation im deutschen Sprachbewusstsein
- Onomastica of the Divine: the problem of «inclusive language» in God-Talk as a linguistic phenomenon
- Soziolinguistik Sociolinguistics
- Samischsprachige Medien und deren Rolle bei der Bewahrung der samischen Sprache in Norwegen
- Sophistry – a Success Recipe for Romanian Politicians
- Morphologie und Syntax Morphology and Syntax
- Bidirectional Change: Some Examples from Derivational Morphology
- Grammatischer Kontext der depräpositionalen Richtungsadverbien
- Modern Aspects of D. Irimia’s Contribution to the Development of Romanian Grammar and Stylistics
- Lexikologie und Semantik Lexicology and Semantics
- Das zweisprachige Wörterbuch – „notwendiges Übel“ oder Medium kritischen Sprachvergleichs?
- Rheinisches und oberdeutsches (bairisch-österreichisches) Wortgut im Siebenbürgisch-Sächsischen – mit Fallbeispielen
- Co-reference and a Sequence of Designators
- Kontrastive Linguistik Contrastive Linguistics
- Diminutiv als Denotat im Slowenischen und im Deutschen
- Verb-Nomen-Komposita im Deutschen und im Serbischen
- Possessive Konstruktionen in der deutschen und litauischen Phraseologie: Idiome mit der Bedeutung ‘reich sein’
- Wann drücken reflexive Verbformen ein possessives Verhältnis aus? Einige deutsch-litauische Überlegungen
- Computerlinguistik Computational Linguistics
- Extracting Translation Equivalents from Monolingual Corpora for Statistical Machine Translation
- Attitudes and Habitudes of Romanian Consumers of Online Media
- Angewandte Linguistik Applied Linguistics
- Mediensprache Deutsch für georgische Journalistikstudenten
- Computergestützte Präsentation als Mittel des interdisziplinären Fremdsprachenunterrichts
- CLIL am Beispiel des Fachsprachenkurses Unternehmenskommunikation
- Medienrelevante Aspekte von Texten an der Schnittstelle von Technik und Öffentlichkeitsarbeit
- Autorenverzeichnis/List of Authors
- Reihenübersicht
Zum Thema des Kolloquiums
Der vorliegende Band erscheint als Ergebnis des 46. Linguistischen Kolloquiums, das vom 14. bis zum 17. September 2011 in Sibiu stattgefunden hat. Das Linguistische Kolloquium wurde an der Fakultät für Journalistik der Lucian-Blaga-Universität Sibiu organisiert und fand zum ersten Mal in Rumänien statt. An der Organisation beteiligten sich Kolleginnen und Kollegen der Fakultät, dazu 24 freiwillige Studentinnen und Studenten zusammen mit Ioana Creţu, der Leiterin des Organisationsteams. Die 60 Teilnehmerinnen und Teilnehmer stammten aus 17 Ländern in Europa und den USA und von insgesamt 33 verschiedenen Universitäten. An der feierlichen Eröffnung beteiligten sich, außer der Leitung der Fakultät, die Vizerektorin für internationale Beziehungen, Vertreter des Deutschen Generalkonsulats Hermannstadt und der Vorsitzende des Kreisrates, Herr Martin Bottesch.
Zur langen Tradition des Kolloquiums gehört, das Rahmenthema der Tagung eher breit festzulegen, was sich auch in diesem Fall bewährt hat. Die gestellte Frage «Quo vadis, Kommunikation?» soll zusammen mit dem Untertitel Kommunikation – Sprache – Medien hervorheben, dass die Medienproblematik in der heutigen Kommunikation eine bedeutende Rolle spielt und zugleich immer wieder entweder Ausgangspunkt oder Anwendungsgebiet von Betrachtungen zu den traditionellen Kernbereichen der Linguistik oder zur Angewandten Linguistik ist. Damit schließt das 46. Linguistische Kolloquium mit dieser Formulierung auch an den Titel der Akten des 37. Linguistischen Kolloquiums (Sprache und die modernen Medien) an, das unter der Leitung von Prof. Rolf Herwig im September 2002 in Jena stattgefunden hat.
Auf die Problematik der Kommunikation gehen viele Autoren und Autorinnen im vorliegenden Band ein, darüber hinaus betreffen ihre Beiträge auch andere Thematiken, die den traditionellen linguistischen Subdisziplinen zuzuordnen sind. Insgesamt wurden fast 60 Vorträge gehalten, von denen 44 für die Publikation eingereicht wurden und im vorliegenden Band abgedruckt werden. Die Beiträge sind auf die neun Sektionen der Tagung aufgeteilt: Medienlinguistik, Pragmatik und Diskursanalyse, Interkulturelle Linguistik, Soziolinguistik, Syntax und Morphologie, Lexikologie und Semantik, Kontrastive Linguistik, Computerlinguistik und Angewandte Linguistik.
Plenarvorträge
In das Rahmenthema leiten die vier Plenarvorträge ein, jedoch aus verschiedenen Perspektiven. Der erste Plenarvortrag Ist das Deutsche demokratischer geworden? Von der Hochsprache zur Standardsprache von Prof. Heinrich Weber von der Eberhard-Karls-Universität Tübingen bietet die Perspektive der Sprachgeschichte. Ausgehend von der Petrus-Frage Quo vadis? fragt sich Prof. Weber, in welche Richtung sich das ← 11 | 12 → Deutsche seit dem 19. Jh. entwickelt hat und wie diese Entwicklung zu bewerten ist. Um diese Frage zu beantworten, werden zwei Zeitabschnitte der deutschen Sprache einander gegenübergestellt, nämlich die Zeit um 1900 und die Gegenwart, etwa ein Jahrhundert später, und es wird versucht, Art und Grad des Sprachwandels zu charakterisieren. Prof. Weber ist der Meinung, dass das Deutsche in seiner neuen Sprachperiode tatsächlich „demokratischer“ geworden ist. Nach außen habe es seinen Anspruch aufgegeben, „Weltsprache“ zu sein. Im Innern sei es nicht mehr die an den Klassikern orientierte „Hochsprache“ einer bildungsbürgerlichen Elite. Dadurch habe sich auch die Norm ihres Gebrauchs verändert: Es gehe heute in der Sprache nicht mehr um Schönheit und Reinheit, sondern um Funktionalität und Verständlichkeit.
Im Vortrag von Prof. Ralf Hohlfeld (Universität Passau) Öffentlichkeit im digitalen Zeitalter: Umbruch oder Abbruch der gesellschaftlichen Kommunikation? wird das Für und Wider der Neukonstituierung von Öffentlichkeit diskutiert. Prof. Hohlfeld zeigt, dass Medienwelt und Öffentlichkeit sich derzeit in einer radikalen Umbruchphase befinden und dass durch das Verschmelzen von Plattformen und das Kreuzen von Kommunikationskanälen die gesellschaftliche Kommunikation einen ebenso rapiden wie radikalen Umbruch erfährt. Der Autor ist der Meinung, dass die neu entstandene Netzwerköffentlichkeit die soziale Kommunikation verändert. Die zentrale Frage, ob die neuen technischen Möglichkeiten tatsächlich zu einer transparenteren, informierteren und meinungsvielfältigeren integrierten Gesellschaft führen, könne jedoch nur empirisch beantwortet werden.
Die Ausführungen von Prof. Heinz-Helmut Lüger von der Universität Koblenz-Landau, die sich ausschließlich an ausgewählten Beispielen der deutschen Tagespresse orientieren, machen deutlich, dass die Entwicklung des journalistischen Kommentars trotz eines gewissen Wandels maßgeblich von Kontinuität bestimmt ist. Im Plenarvortrag Kontinuität im Wandel? Journalistisches Kommentieren zwischen Tradition und Innovation unterstreicht Prof. Lüger, dass große Veränderungen zweifellos das Layout kennzeichnen und dass sowohl für Print- wie auch für Online-Ausgaben heute eine mehrkanalige und modular strukturierte Berichterstattung bestimmend ist. Es wird ausgeführt, dass es für den Leser verschiedene Orientierungshilfen gibt, die im Unterschied zur Ganzlektüre eine selektive Informationsentnahme erleichtern. Ein großes Beharrungsvermögen zeigen dagegen die makrostrukturellen Eigenschaften von Kommentaren.
Der letzte Plenarvortrag Sur la situation de la langue dans la littérature contemporaine des leider inzwischen verstorbenen Kollegen aus Belgien Prof. Eugène van Itterbeek geht von der Betrachtung der Sprache in der Gegenwartsliteratur anhand von vier Schriftstellern aus: Herta Müller, Éduard Glissant, Paul Austen und Louis-Férdinand Céline.
Zu den Beiträgen in diesem Band
Direkt an das Rahmenthema knüpfen die vielen Beiträge der Sektion Medienlinguistik: Maurice Vliegen befasst sich mit der lexikalischen Subjektivität in den heuti ← 12 | 13 → gen Zeitungen am Beispiel der Verwendung der Verben grinsen und lachen, Janja Polajnar untersucht die Rolle der rekontextualisierten Werbeslogans in Zeitungstexten. Ana Tavčar betrachtet die Thema-Rhema-Gliederung durch die Besetzung des Nachfeldes in deutschen journalistischen Texten, Bernd Spillner beschreibt die Wirkung von non-verbalen Elementen in Pressetexten. Urszula Żydek-Bednarczuk untersucht mediale Metaphern, die wir wahrscheinlich alle aus der Fachliteratur oder aus dem Alltag kennen, deren metaphorischer Wert uns jedoch vielleicht nicht bewusst ist: globales Dorf, Konsumgesellschaft, surfen etc. Nikolina Borčić und Maja Anđel stellen anhand der politischen Reden und der Zeitungsinterviews von Angela Merkel und Ivo Josipović die These auf, dass das Geschlecht der Redner das sprachliche Register beeinflusst. Es gibt auch Untersuchungen zu Pressetexten aus anderen Ländern: Ioana Creţu bespricht die Medienlandschaft Rumäniens und die Grenzen der Pressefreiheit, die Rolle der rumänischen Presse in der sprachlichen Entwicklung des 19 Jahrhunderts wird von Anca David hervorgehoben. Besondere Gattungen in der rumänischen und französischen Presse analysiert Andra Catarig, während Ioana Ciocan und Sabina Špes Spracherscheinungen in den modernen Medien beziehungsweise im journalistischen Text beschreiben.
Weitere Autoren und Autorinnen rücken diverse Fragestellungen zum Diskurs in den Vordergrund (Manfred Uesseler, Raluca Soare, Tanja Škerlavaj, Stojan Bračič, Kaja Dolar, Bärbel Treichel, Alexandra Todoran, Tanja Becker), Klaus-Dieter Gottschalk thematisiert die Rethorik der (Selbst-)Demütigung von Herta Müller.
Einige Beiträge sind den syntaktischen und morphologischen Fragestellungen der Systemlinguistik zuzuordnen (Camiel Hamans, Roswitha Althoff/Irene Doval, Odette Arhip).
Im Bereich der Kontrastiven Linguistik, beziehungsweise der Angewandten Linguistik bewegen sich die Beiträge von Darko Čuden, Mihaela Lalić, Virginija Masiulionytė/Loreta Semėnienė, Justina Daunorienė, Marina Andrazashvili, Manana Kutelia, Elisabeth Lazarou und Voichiţa Ghenghea.
Schließlich stützen sich die Beiträge von Nora Căpăţână, Valentina Stepanenko, Vladimir Alexeev, Zsuzsana Szilvási, Arash Farhidnia, Sigrid Haldenwang, Kazimierz Sroka, Reinhard Rapp, Minodora Sălcudean auf Aufsätze aus weiteren Teildisziplinen der Linguistik, wie der Interkulturellen Linguistik, der Soziolinguistik und der Computerlinguistik sowie der Lexikologie und der (historischen) Semantik.
Danksagung
Unser Dank geht an die Herausgeberin und die Herausgeber der Reihe Linguistik International und an das Internationale Organisationskomitee des Linguistischen Kolloquiums, die uns immer wieder Mut gemacht haben. Ein ganz besonderer Dank gilt Herrn Prof. Dr. Heinrich Weber, der unser Vorhaben und unsere Arbeit vielfältig unterstützt und dadurch zum Erscheinen des Bandes beigetragen hat.
Wir bedanken uns auch recht herzlich bei unserer Ansprechpartnerin im Peter Lang Verlag, Frau Ute Winkelkötter, die die Herausgabe des Bandes in der Schlussphase betreut hat. ← 13 | 14 →
Deutschsprachige Beiträge dieses Bandes hat unsere Kollegin Dr. Liane Junesch, englischsprachige Frau Manuela Wedgwood und französische Frau Friederike Weber redigiert, wofür allen besonderen Dank gebührt. Ein besonderer Dank gilt der Leiterin des Deutschen Kulturzentrums in Sibiu, Ada Tănase, für die finanzielle Unterstützung der redaktionellen Arbeiten durch das Deutsche Kulturzentrum.
An dieser Stelle ist auch all denjenigen zu danken, dank dener das Kolloquium zustande gekommen ist: dem ganzen Organisationsteam, besonders meiner Kollegin Ioana Ciocan und Roger Pârvu, Projektleiter der Evangelischen Akademie Siebenbürgen, sowie Alex Ujupan (Carpathian Travel), Raluca Sfîriac (Quartett Intermezzo) und Günter und Regina Klingeis, die bei der Durchführung der Tagung mitgeholfen und für das Rahmenprogramm gesorgt haben.
| Sibiu, im Februar 2015 | Ioana Creţu |
← 14 | 15 →
1 Zur Fragestellung und Methode
Die folgenden Ausführungen gelten einem Teilaspekt des Rahmenthemas, das die Veranstalter für das 46. Linguistische Kolloquium in Sibiu/Hermannstadt gewählt haben. Das Rahmenthema lautet „Quo vadis, Kommunikation?“ und ist aufgeteilt in die Teilthemen Kommunikation, Sprache und Medien. Die Frage „Quo vadis?“ stammt aus einer Petrus-Legende. Auf der Flucht vor Neros Christenverfolgungen soll Petrus Jesus begegnet sein und ihn gefragt haben: „Wohin gehst Du?“. Dieser habe geantwortet, er wolle sich noch einmal kreuzigen lassen. Daraufhin sei Petrus umgekehrt, um in Rom den Märtyrertod zu erleiden (vgl. Büchmann 1964, 452). Die Frage „Quo vadis?“ hat also mit der Richtung zu tun, in die jemand geht, und mit der Möglichkeit der Umkehr.
Als germanistischer Linguist wende ich mich dem Teilthema „Sprache“ zu und stelle das Deutsche in den Mittelpunkt. Ich frage, in welche Richtung sich das Deutsche seit dem 19. Jh. entwickelt hat und wie diese Entwicklung zu bewerten ist. Das Rahmenthema und der Titel dieses Beitrags sind in übertragenem Sinn zu verstehen. Die Kommunikation kann nicht „gehen“ und eine Sprache kann nicht „demokratisch“ sein. Wohl aber können sich Kommunikationsmittel und Kommunikationspraxis in bestimmte Richtungen weiterentwickeln, und eine Sprache kann Züge aufweisen, die einer demokratisch verfassten Gesellschaft mehr oder weniger gut entsprechen. Wir wollen also fragen, ob sich das Deutsche in eine Richtung entwickelt hat, die zu einer demokratischen Verfassung passt.
Um diese Frage zu beantworten, werde ich – nach einigen methodischen Vorbemerkungen – zwei Zeitabschnitte der deutschen Sprache einander gegenüberstellen, nämlich die Zeit um 1900, als es das Deutsche Reich mit Kaiser Wilhelm II. an der Spitze noch gab, und die Gegenwart etwa ein Jahrhundert später, und dann versuchen, Art und Grad des Sprachwandels zu charakterisieren.
Bei der Sprachgeschichte stütze ich mich in erster Linie auf das monumentale dreibändige Werk zur neuhochdeutschen Sprachgeschichte, das mein akademischer Lehrer Peter von Polenz zwischen 1991 und 1999 veröffentlicht hat. Peter von Polenz war nicht nur Chronist der neueren Sprachgeschichte, sondern auch – wenigstens um 1970 – Anreger von Veränderungen. Methodisch will ich mich auf den rumänischen Romanisten, Linguisten und Sprachphilosophen Eugenio Coseriu berufen, der seit 1962 in Tübingen gewirkt hat und von dem ich viel gelernt habe.
Die deutsche Sprachgeschichte wird seit einem Vorschlag Wilhelm Scherers (vgl. Scherer 1878) gewöhnlich in Perioden von 300 Jahren Dauer eingeteilt, nämlich Althochdeutsch von 750 bis 1050, Mittelhochdeutsch von 1050 bis 1350, Früh ← 17 | 18 → neuhochdeutsch von 1350 bis 1650 und Neuhochdeutsch ab 1650. Eine intensivere Erforschung des Neuhochdeutschen hat erst in den letzten Jahrzehnten eingesetzt. Ob die Tatsache bedeutsam ist, dass 1950 wieder eine Periode von 300 Jahren zu Ende ging, wird uns weiter unten noch beschäftigen.
Man kann, wie ich meine, Sprachgeschichte unter vier Gesichtspunkten betrachten. Ich bezeichne sie – teilweise in Anlehnung an Termini Coserius – als „Architektur der Sprache“, „Sprachstruktur“, „Sprachgebrauch“ und „Sprachbewusstsein“.
1. Die Architektur einer komplexen „historischen Sprache“ (vgl. Coseriu 2007, 24–25), wie es das Deutsche ist, betrifft nach meiner Interpretation einerseits ihre Situierung im Feld der benachbarten Sprachen und andererseits ihre innere Gliederung in verschiedene Varietäten, nämlich Dialekte, Soziolekte und Sprachstile. In diesem Rahmen ist auch zwischen gesprochener und geschriebener Sprache sowie zwischen der Hoch- oder Standardsprache und mehr oder weniger begrenzten Umgangssprachen, Sondersprachen, Fachsprachen und Ortsdialekten zu unterscheiden.
2. Die Sprachstruktur, die ungefähr Saussures langue entspricht, umfasst die Formen und Regeln, die für eine bestimmte Varietät oder – in der Terminologie Coserius – für eine bestimmte „funktionelle Sprache“ (vgl. Coseriu 2007, 25–28) gelten. Auch hier ist wieder eine doppelte Untergliederung möglich:
a. Man kann unterscheiden zwischen der „Sprachnorm“, d. h. den normalerweise verwendeten lexikalischen und grammatischen Formen, dem „Sprachsystem“ im engeren Sinne, d. h. den bedeutungsrelevanten Unterscheidungen, die eine Sprache macht, und dem „Typus“, d. h. den allgemeineren Regularitäten, denen das Sprachsystem folgt (vgl. Coseriu 2007, 266–278). Zur Verdeutlichung seien die folgenden Beispiele angeführt: Der heutigen Norm des Deutschen entspricht das Relativpronomen der; das Relativpronomen welcher gehört zwar noch zum System des Deutschen, ist aber heute eher ungebräuchlich und entspricht darum nicht mehr der Norm. In der Norm der Gegenwartssprache wird ein Satzbau bevorzugt, der komplexe Satzgefüge vermeidet. Es gibt darum weniger Nebensätze mit Verb-Endstellung und mehr Hauptsätze mit Verb-Zweitstellung. Wenn es nun in der Norm mehr Sätze mit Verb-Zweitstellung als solche mit Verb-Endstellung gibt, wirkt sich das auf den vorherrschenden Sprachtypus aus. Denn nach Greenberg (1963) gehören Nebensätze zum SOV-Typus mit der Abfolge Subjekt-Objekt-Verb, Hauptsätze weisen dagegen überwiegend die Folge Subjekt-Verb-Objekt auf und sind wie das Englische SVO-Sätze.
b. Die Sprachstruktur weist eine Reihe von Ebenen auf, nämlich Lexikon und Grammatik, und bei der Grammatik die Phonologie als Ebene der Laute, die Graphemik als Ebene der Buchstaben, die Morphologie und die Wortbildung als Ebene der Wörter sowie die Syntax als Ebene des Satzes.
3. Der Gesichtspunkt des Sprachgebrauchs betrifft die Texte und Textsorten, die in einer Sprachgemeinschaft auftreten; Brigitte Schlieben-Lange (1983) hat hierfür den Terminus „Traditionen des Sprechens“ geprägt. Georg Stötzel und Martin ← 18 | 19 → Wengeler (1995) beispielsweise haben die „Geschichte des öffentlichen Sprachgebrauchs in der Bundesrepublik Deutschland“ untersucht und anhand von Zeitungen herausgearbeitet, mit welchen „kontroversen Begriffen“ man über Themen wie „Markt- und Planwirtschaft“, die „deutsche Frage“, den „Terrorismus“, die „feministische Sprachkritik“ usw. gesprochen hat. Während man den überlieferten Sprachgebrauch des Althochdeutschen noch als „Bibel- und Kirchentexte“, den des klassischen Mittelhochdeutschen als „Ritterdichtung“ oder „höfische Dichtung“ zusammenfassen konnte, ist jede Gesamtdarstellung des Sprachgebrauchs um 1900 oder um 2000 wegen der unendlichen Fülle und Vielfalt des Stoffes zum Scheitern verurteilt. Man kann nur Schwerpunkte oder auffällige Tendenzen herausarbeiten, muss aber den Vorwurf der Subjektivität oder Einseitigkeit hinnehmen.
4. Das Sprachbewusstsein betrifft die Einstellung und den Grad der Wertschätzung, die die Sprecher gegenüber ihrer Sprache haben. Diese Einstellung zeigt sich in verschiedenen Bereichen: im Sprachunterricht, in Beiträgen zur Sprachpflege und Sprachkritik, im Stand der linguistischen Forschung und Lehre, im öffentlichen Sprachgebrauch, in der Sprachwahl bei bestimmten Textsorten usw.
In den beiden nächsten Abschnitten will ich das Deutsche um 1900 und das Deutsche der Gegenwart unter den genannten vier Gesichtspunkten betrachten. Abschließend stelle ich die Frage, ob die Veränderungen, die das Deutsche im 20. Jh. erfahren hat, es rechtfertigen, den Beginn einer neuen sprachgeschichtlichen Periode anzusetzen. Nach dem Periodisierungsschema von Wilhelm Scherer endete nämlich 1950 wieder eine 300-jährige Epoche.
2 Das Deutsche um 1900
2.1 Architektur
In den Jahren um 1900 befand sich das 1871 gegründete „Deutsche Reich“ auf dem Höhepunkt seiner politischen, militärischen und wirtschaftlichen Macht. Obwohl es einen demokratisch gewählten Reichstag gab, lag die eigentliche Macht beim Hohenzollernkaiser Wilhelm II. und den Landesfürsten, beim Adel und beim Militär. Das aufstrebende Großbürgertum musste sich mit wirtschaftlichem Reichtum begnügen, das „Proletariat“ sich seinen Anteil am Wohlstand erst allmählich erkämpfen. Eng verbündet mit dem Deutschen Reich war die österreichisch-ungarische Doppelmonarchie, ein Vielvölkerstaat, in dem nur die Ungarn die gleichen Rechte wie die Deutschen hatten.
Während der Preußenkönig Friedrich II. noch in der zweiten Hälfte des 18. Jh. am liebsten französisch sprach, wurde Deutsch nun die alles dominierende Sprache nicht nur des deutschen Nationalstaats, sondern auch der westlichen Teile von Österreich-Ungarn. Für die deutschsprachige Schweiz und für Luxemburg, dessen Oberschicht gern französisch sprach, dauerten die älteren Verhältnisse fort. ← 19 | 20 →
Innerhalb Deutschlands und Österreich-Ungarns gab es viele Minderheitssprachen: Französisch in Lothringen, Dänisch in Schleswig, Sorbisch in Brandenburg und Sachsen, vor allem aber Polnisch in den östlichen Teilen Preußens. In Österreich-Ungarn dominierte das Deutsche die anderen Sprachen. Im Deutschen Reich waren vor allem die Polen Germanisierungstendenzen ausgesetzt, die zu heftigen Konflikten führten; in Österreich-Ungarn war das Verhältnis zu den Tschechen sehr gespannt.
Zum ersten Mal in seiner Geschichte hatte das Deutsche keine Sprache mehr über sich. Latein hatte seine Bedeutung als Sprache der Wissenschaft fast vollständig verloren. Französisch war nach dem deutschen Sieg über Frankreich 1870 auch in Diplomatie und Politik weniger dominierend. Englisch war auf dem Kontinent noch nicht zur Weltsprache aufgestiegen. Das Deutsche stand auf gleicher Augenhöhe mit dem Englischen und Französischen. Die wissenschaftlichen Erfolge Deutschlands stärkten das Deutsche als Wissenschaftssprache.
Weniger günstig sah es für das Deutsche im Innern aus, wenn man darunter die normgerechte Hochsprache versteht. Das Hochdeutsche war in erster Linie Schriftsprache und nur sekundär gesprochene Sprache. Es war in frühneuhochdeutscher Zeit aus der Sprache der Kanzleien hervorgegangen, vor allem der sächsischen Kanzlei in Meißen. Durchgesetzt hatte sich die Meißnische Sprachform durch die Lutherbibel, die sich stärker an der gesprochenen Sprache orientierte und dank der Sprachbegabung Luthers stilistisch vorbildlich war. In der Barockzeit dominierten wieder die Juristen mit ihren langen, verschachtelten Sätzen. Erst Mitte des 18. Jh. entstand unter französischem und aufklärerischem Einfluss eine literaturgeeignete Sprachform, die von Autoren wie Johann Christoph Gottsched und Johann Christoph Adelung propagiert und kodifiziert wurde. In dieser Sprache schrieben die Klassiker, die zum Vorbild für das Bildungsbürgertum des 19. Jh. wurden. Das Bürgertum kompensierte fehlende Macht und fehlenden Reichtum mit dem Stolz auf seine Bildung, die zu einer Art Ersatzreligion wurde:
Die Gymnasien und (…) die Höhere-Töchter-Schulen zusammen haben im 19. Jh. das gefördert, was man pauschal bildungsbürgerliches Deutsch nennen und als Sozialsymbol (…), d. h. als sprachliche Leit- und Orientierungsnorm für das Bildungsbürgertum und die von ihm beeinflußten Ober- und Mittelschichten erklären kann. (Polenz 1999, 58).
Das Bildungsdeutsch wurde mit besonderer Strenge und Präzision vermittelt. Man legte größten Wert auf die Normen der Orthografie und Hochlautung, strebte nach überregionaler Einheitlichkeit, verwendete einen schriftsprach-typischen Satzbau und setzte sich sprachkritisch mit Abweichungen von diesem Ideal auseinander (vgl. Polenz 1999, 59).
Das Sprachideal der bürgerlichen Bildungselite stammte aus der Antike, galt für das Lateinische, wurde an den Lateinschulen und philosophischen Fakultäten der Universitäten tradiert und im 19. Jh. vom Gymnasium übernommen. Im Römischen Reich der Kaiserzeit war die Beherrschung von Grammatik, Rhetorik und Dialektik Kennzeichen der Zugehörigkeit zur Oberschicht; das umfangreiche Lehrbuch von ← 20 | 21 → Quintilian, die „Ausbildung des Redners“, zeigt die Bedeutung dieses Stoffes für die Oberschicht-Erziehung. Die Rhetorik forderte, dass die Sprache puritas (Reinheit), perspicuitas (Klarheit bzw. Verständlichkeit) und ornatus (Schönheit bzw. Schmuck) aufweisen soll. Das Bildungsbürgertum mit seiner Antikenbegeisterung konnte an diese Tradition anknüpfen und sie auf das Deutsche übertragen; die Vermittlung bildete das von Wilhelm von Humboldt geschaffene humanistische Gymnasium.
Unterhalb der Hochsprache und außerhalb der Schriftsprache bestanden die Umgangssprachen und Dialekte weiter, besaßen aber als nicht normgerecht geringeres Ansehen. Die in Norddeutschland verbreitete Verwechslung von Dativ und Akkusativ wie z. B. bei Ich kenne Ihnen nicht konnte ein Mädchen gesellschaftlich diskreditieren, wie Angelika Linke an einem literarischen Beispiel gezeigt hat (vgl. Linke 1996, 232).
Die ältere Germanistik stellt die Varietäten des Deutschen in Form einer Pyramide dar, mit einer kleinen hochsprachlichen Spitze, einer breiteren umgangssprachlichen Mitte und einer großen Basis, die die verschiedenen Dialekte repräsentiert; man vergleiche Grafik 1.
Grafik 1: Varietätenpyramide
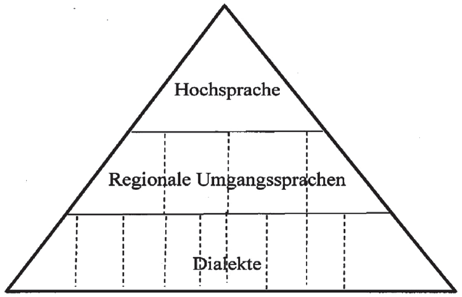
Hochdeutsch war die Sprache einer Elite, es war eine besondere, gehobene Sprachform, Hochsprache im wörtlichen Sinn. ← 21 | 22 →
2.2 Sprachstruktur
Hinsichtlich der Sprachstruktur ist auf der Ebene der Buchstaben und Laute vor allem die Norm betroffen. Um 1900 bestanden zwei Schriften nebeneinander, die deutsche Frakturschrift und die lateinische Antiqua. Bei der Orthografie ist 1902 die Vereinheitlichung gelungen: Dudens „Regeln für die deutsche Rechtschreibung“ wurden im Reich verbindlich; Österreich-Ungarn und die Schweiz schlossen sich an. Die Aussprache wurde wenigstens für die Bühne durch Theodor Siebs ab 1898 vereinheitlicht.
Bei Morphologie und Wortbildung setzen sich Tendenzen fort, die schon vorher bestanden, z. B. der Ersatz des Genitivs durch Präpositionalgefüge (Die Dramen von Schiller statt die Dramen Schillers), Rückgang des Konjunktivs (er sagt, dass er kommt statt Er sagt, dass er komme) oder Substantivbildungen aus Verben und Adjektiven (Verzicht leisten statt verzichten). Der Wortschatz verändert sich durch neue Wortbildungen, die aus den Bedürfnissen der fortschreitenden Technik oder puristisch motivierten Eindeutschungen entstehen, z. B. Bahnsteig für Perron, Rückfahrkarte für Retourbillet.
In der Syntax ist noch der „bildungsbürglich-akademisch-administrative Nebensatzstil“ (Polenz 1999, 353) dominierend, der sich durch eine komplizierte Hypotaxe mit Klammerbildungen auszeichnet. Drei Beispiele mögen das illustrieren, eines aus der Literatur, eines aus einer Reichstagsrede und eines aus den Medien. Werden mehrere Ganzsätze zitiert, erhalten sie eine Nummerierung in eckigen Klammern. Die Teilsätze sind durch Nummerierung in runden Klammern und die Nebensätze je nach Grad durch ein, zwei oder drei Sterne gekennzeichnet; Nominalisierungen werden durch Kursivschrift markiert. Die spitzen Klammern im Text markieren Teilsätze, die von anderen Teilsätzen eingeklammert sind. Das erste Beispiel stammt aus Fontanes „Effi Briest“:
(1) Rasch und sicher ging die Wollnadel der Damen hin und her, (2*) aber während die Mutter kein Auge von der Arbeit ließ, (3) legte die Tochter, > (4*) die den Rufnamen Effi führte, > von Zeit zu Zeit die Nadel nieder (5) und erhob sich, (6*) um unter allerlei kunstgerechten Beugungen und Streckungen den ganzen Kursus der Heil- und Zimmergymnastik durchzumachen. […] (Fontane 2007, 127.655–66)
Der Satz enthält drei syndetisch mit und und aber gereihte Teilsätze, nämlich (1), (3) und (5); von (3) hängen zwei Nebensätze ersten Grades ab, nämlich der Temporalsatz (2) mit während und der Attributsatz (4) die den Rufnamen Effi führte, von (5) die finale Infinitivkonstruktion mit um…zu. Als Nominalisierung kann die kursiv geschriebene Konstruktion betrachtet werden, die dem Satz indem sie sich auf verschiedene Weisen kunstgerecht beugte und streckte entspricht.
Das zweite Beispiel stammt aus einer Reichstagsrede des SPD-Vorsitzenden August Bebel aus dem Jahr 1871 und zeigt, dass auch Politiker, die nicht der alten Elite angehörten, selbst in mündlicher Rede den komplexen Satzbau des bildungsbürgerlichen Deutschen beherrschten: ← 22 | 23 →
(1) Es scheint mir überhaupt, (2*) als wenn die Religionsinteressen im neuen Deutschen Reich alles andere ausmerzen sollten; (3) denn in zwei Sitzungen, > (4*) die ich die Ehre habe (5**) hier anwesend zu sein, > habe ich außer Religiösem kaum etwas anderes zu hören bekommen, (6*) so daß einem Manne >, (7**) der mit den religiösen Dogmen vollständig gebrochen hat,> es eine gewisse Selbstüberwindung kostet, (8**) einer solchen Verhandlung länger zuzuhören! (Kuhn 1970, 48–49)
Der Satz enthält acht Teilsätze. Die Sätze (1) und (3) sind Hauptsätze. Vom ersten Hauptsatz ist der mit als wenn eingeleitete Nebensatz ersten Grades (2) abhängig, der zweite Hauptsatz enthält den Relativsatz (4) und den weiterführenden Nebensatz (6); von der Substantivgruppe die Ehre im Relativsatz (4) ist die attributive Infinitivkonstruktion zweiten Grades (5) hier anwesend zu sein abhängig; der weiterführende Nebensatz (6) enthält den Relativsatz (7) der … gebrochen hat und die attributive Infinitivkonstruktion (8) einer solchen Verhandlung länger zuzuhören.
Als drittes Beispiel soll ein Kommentar aus dem „Reutlinger Generalanzeiger“ vom 4. Januar 1912 dienen, der die anstehenden Reichstagswahlen betrifft:
(1) Die Regierung aber, > (2*) die den Wählern vorwirft, (3**) daß sie die Situation nicht erfaßt hätten, (4**) und ein einfaches klares Ja oder Nein von ihnen verlangt, > treibt selbst die schlimmste Vogelstraußpolitik, (5*) da sie nicht sehen will, (6**) daß das deutsche Volk schon längst vor Bethmann Hollweg und seinen philosophischen Wahlbetrachtungen die Scheidelinie gefunden hat, (7***) die nicht nur für die bevorstehenden Wahlen, (8***) sondern für unser ganzes politisches Leben der nächsten Zeit maßgebend geworden ist. (GEA 4.1.1912, 1)
Von den acht Teilsätzen ist nur der erste ein Hauptsatz. Der Attributsatz (2) zu Regierung, der noch zum Vorfeld des Hauptsatzes gehört, enthält die koordinierten Objektsätze zweiten Grades (3) und (4). Im Nachfeld steht der mit da eingeleitete Adverbialsatz (5), von dem wiederum der Objektsatz zweiten Grades (6) abhängt. Die koordinierten Attributsätze (7) und (8) sind Nebensätze dritten Grades.
In Bezug auf den Wortstellungstypus ist das Deutsche ein Mischtypus. In den drei Beispielen treten sechzehn Nebensätze bzw. Infinitivkonstruktionen mit Verb-Endstellung und nur sechs Verbzweitsätze auf. Die Nebensätze gehören zum Kopf-zuletzt- oder SOV-Wortstellungstypus, die Verbzweitsätze zum Kopf-zuerst- oder SVO-Typus. In der Hochsprache um 1900 dominiert also der SOV-Typus.
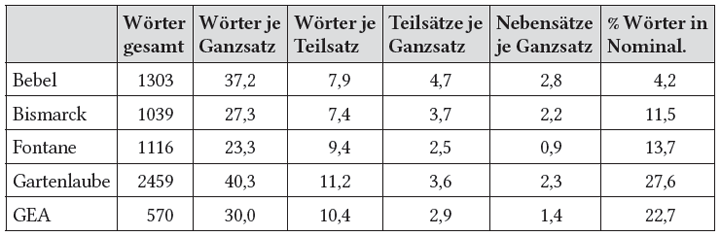
Die folgende Tabelle mit Texten von jeweils einigen Seiten Umfang zeigt, dass die um 1900 gültige Sprachnorm lange Sätze von 23 bis 40 Wörtern Umfang und mit zwei bis vier Teilsätzen bevorzugte, von denen je nach Autor knapp die Hälfte oder die Mehrzahl Nebensätze waren. Auch Nominalisierungen waren schon in Gebrauch, wenn auch mit sehr unterschiedlicher Häufigkeit. ← 23 | 24 →
Tabel1e 1: Satzkomplexität um 1900
2.3 Sprachgebrauch
Auf den Sprachgebrauch vor 100 Jahren näher einzugehen, ist schon wegen seiner Uferlosigkeit wenig sinnvoll. Ich beschränke mich darum auf ein Zitat aus dem Lesebuch für die Sonntagsschulen der Pfalz, das nach Form und Inhalt für den Stil des damaligen Obrigkeitsstaates stehen mag:
Details
- Pages
- 502
- Publication Year
- 2016
- ISBN (Hardcover)
- 9783631661611
- ISBN (PDF)
- 9783653057409
- ISBN (MOBI)
- 9783653966039
- ISBN (ePUB)
- 9783653966046
- DOI
- 10.3726/978-3-653-05740-9
- Language
- German
- Publication date
- 2015 (September)
- Keywords
- Medienlinguistik Pragmatik Diskursanalyse Grammatiktheorie
- Published
- Frankfurt am Main, Berlin, Bern, Bruxelles, New York, Oxford, Wien, 2015. 502 S.
- Product Safety
- Peter Lang Group AG
