
Pragmantax II
Zum aktuellen Stand der Linguistik und ihrer Teildisziplinen. Akten des 43. Linguistischen Kolloquiums in Magdeburg 2008 / The Present State of Linguistics and its Sub-Disciplines. Proceedings of the 43rd Linguistics Colloquium, Magdeburg 2008
Zusammenfassung
This volume contains the revised versions of 63 papers, written in German, English and French. It considers a broad spectrum of topics and findings from various areas of linguistics and thereby offers a critical review of the field. The authors address questions ranging from grammar, semantics, text and discourse pragmatics to issues from the field of applied linguistics. The volume is concluded by studies on contrastive linguistics and foreign language pedagogy.
Leseprobe
Inhaltsverzeichnis
- Cover
- Titel
- Copyright
- Autorenangaben
- Über das Buch
- Zitierfähigkeit des eBooks
- Inhaltsverzeichnis
- Vorwort der Herausgeber
- 1 Grammatik und Phraseologie
- Zum Prowort auf der morphologischen, semantischen, syntaktischen, textuellen und stilistischen Ebene
- Genus-Kategorien als Beispiel für das Zusammenspiel von Morphologie und Syntax in Sprachtheorie und Einzelsprachtheorie
- Nominalklammem im Deutschen
- Mehrgliedrige Nachfeldbesetzung und Nachfeldbesetzung durch Attribute. Versuch einer Typologie auf der Grundlage der Erzählung Unkenrufe von Günter Grass
- sein- und/oder werden-Passiv
- La grammaire syntagmatique et le phénomène de discontinuité
- Zur Analyse von Phasenverben in der frühen Transformationsgrammatik
- Wirtschaftsphraseologie als Schnittstelle zwischen Terminologie und Phraseologie
- Gebrauchte Fmger-Somatismen des Deutschen
- Ist Grammatik drin, wo Grammatiker draufsteht? Bemerkungen zum neuen „Duden-Sprachbuch“
- Okkasionelle Wortbildungskonstruktionen und das Konzept der performativen Sprache
- 2 Text- und Diskurspragmatik
- Medialität, Intermedialität und Kommunikationsformen
- Sagen, was man meint? Verbale Schutzwälle im argumentativen Diskurs
- Speaking out of Tum
- Multinational vs. Transnational - the Representation of Globalization Processes in the M edia
- Von der Wahrheitssemantik über Präsuppositionen zur Textpragmatik. Der stilistische Gebrauch von „I don’t know (that) p“
- Sentence-final Like: from Quotative to Discourse Marker
- Wie Missverständnis in Nichtverstehen übergeht: Analyse eines kommunikativen Unfalls“ beim Gesprächsdolmetschen
- Schlüsselwörter als Kulturobjekte im Diskurs der Werbung
- Wirtschaftsartikel der Frankfurter Allgemeinen Zeitung 2004-2006 und ihre Adressaten: Was uns die Schlagzeilen über die Nachrichtempfänger verraten
- Anglizismen im Fernsehen - Eine Analyse von Boulevardmagazinen
- Kontext als Redundanzraum
- Kohärenz, Kohäsion und segmentale Konnektivität in der Erzählung
- Konsequent Foucault: Textlinguistik > Linguistische Diskursanalyse (LDA) > Kritische Diskursanalyse (KDA)
- Die Verwendung von Zitat(fragment)en bei Kommunikationsverben in deutschen und niederländischen Zeitungstexten
- Identitätskonstitution der Leserbriefschreibenden in der Braunschweiger Zeitung und Volksstimme bzw. Magdeburger Volksstimme 1979-1999
- Paratexte in wissenschaftlichen Veröffentlichungen
- 3 Semantik und Lexikologie
- Syntagmatic Relations in Russian Corpora and Dictionaries
- Die Inhaltsebene von Online-Zeitungen
- Universal Concepts in a Cognitive Perspective
- Adaptivität und modulare Sprachtheorie am Beispiel von bel et bien
- A Purring and Screeching Human Being: Different Measures of Linguistic Acceptability
- Entraining Metaphors in the English Resultative Constructions
- Übersetzungsprobleme im Bereich der lexikalischen Semantik. Eine Analyse anhand der Blechtrommel von Günter Grass in der Übertragung ins Polnische
- Instability of Grammatical Gender: Tentative Explanations
- Semantic and Pragmatic Aspects of Definiteness
- Polish Secondary Basic Colour Terms: Possible Prototypical Reference Points and Their Stability
- Modelle der linguistischen Bedeutungsbeschreibung -eine klassifizierende Schwerpunktsetzung
- Ergebnisse einer web-basierten Umfrage zur Graduonymie
- 4 Kontrastive Studien und Fremdsprachendidaktik
- Textlinguistik in Polen und in Deutschland. Begriffe, Probleme, Perspektiven - Darstellung eines Projekts
- The Acquisition of English Dative Alternation by Turkish Adult Learners of English
- Wie schreiben Wissenschaftler in einer L2
- Die Rolle der Strategien beim Wortschatziemen
- A Critical Look at the Effects of Questioning on Adult L2 Acquisition
- Didaktische und lexikografische Aspekte deutsch-polnischer Kinderwörterbücher
- Hals- und Beinbruch! - In bocca al lupo! Zu einigen Somatismen im Deutschen und Italienischen
- Pragmatik der Anrede: ein Vergleich von deutschen, portugiesischen und vietnamesischen Anredesystemen
- Marker der reportativen Evidentialität im Deutschen und ihre polnischen Äquivalente
- Zur Lexikon-Grammatik-Schnittstelle in einer kontrastiven Grammatik
- Einige Aspekte der metonymischen Übersetzung. Kausale Metonymie im Prädikatbereich
- 5 Angewandte Linguistik
- Linguistik als problemlösende Wissenschaft. Herausforderungen an die heutige Linguistik
- One World, One English
- Zur Erforschung deutscher und russischer politischer Sprache. Kurzer Überblick aus der Sicht einer russischen Auslandsgermanistin
- Digitale Edition „Der Zürcher Sommer 1968“
- „Ein Volk, das seine Toten ehrt, ehrt sich selbst“ - Zur Semantik des Erinnerns in Gedenkreden
- Politolinguistik als Diskurs analyse - Zum methodologischen Stand und zur Perspektive gegenwärtiger politolinguistischer Forschungen
- Muss man Spracherhebungen ernst nehmen? Zur Interpretation von Umfrageergebnissen zum Niederdeutschen
- Wünschenswertes schön formulieren - die Kunst des schönen Redens und die Werbung
- Some Linguistic Aspects of Cross-cultural Business Communication
- Translating English Predicatives into Russian
- Zur Bedeutung der Onomastik für die Substratforschung am Beispiel des slawischen Substrates in Österreich
- Das Magdeburger Familiennamenbild im 17. und 18. Jahrhundert
- Der Backtranslation-Score: Automatische Evaluierung maschineller Übersetzungen ohne manuell übersetzte Vergleichstexte
- Autorenverzeichnis
- Reihenübersicht
← 10 | 11 → Vorwort der Herausgeber
Das 43. Linguistische Kolloquium fand vom 10. bis zum 13. September 2008 in Magdeburg statt und wurde getragen von den Instituten für Germanistik und für Fremdsprachliche Philologien sowie dem Sprachenzentrum der Otto-von-Guericke-Universität. Das Rahmenthema lautete:
„Pragmantax II. Zum aktuellen Stand der Linguistik und ihrer Teildisziplinen“.
Dieser Titel, der Manchem schon mit Blick auf die Tagung auf den ersten Blick ein wenig kryptisch erschienen sein mag, wurde für den nunmehr vorliegenden Tagungsband beibehalten. Der Grund für die Wahl dieses Titels war, dass wir das Tagungsthema - wie es der Tradition des Linguistischen Kolloquiums entspricht - sehr weit fassen wollten, damit möglichst viele Vor- bzw. Beitragende ihre vielfältigen Forschungsinteressen und -Schwerpunkte einbringen konnten. Der Untertitel sollte hervorheben, dass Beiträge, die eine kritische Bestandsaufnahme - des Faches und/oder seiner Teildisziplinen - versuchen, besonders erwünscht waren. Mit „Pragmantax II“ schließen wir aber zugleich an den Titel der Akten des 20. Linguistischen Kolloquiums an, das unter der Leitung von Karl-Hermann Körner und Armin Burkhardt im September 1985 in Wolfenbüttel stattfand. Die schon damals den Haupttitel bildende Kontamination aus Pragmatik, Semantik und Syntax entstammt dem Aufsatz „Where to do things with words“ des amerikanischen Sprachphilosophen und Linguisten John Robert Ross1, der diesen Terminus, im Anschluss an Fillmore, zur Bezeichnung der „mixed components“ in der Generativen Transformationsgrammatik verwendet. Der Begriff schien uns besonders geeignet, die gewünschte thematische Breite unserer Tagung hervorzuheben.
Vielleicht gab auch die Gestaltung des Tagungsplakats, das auf der folgenden Seite abgedruckt ist, ein paar Rätsel auf, die natürlich an dieser Stelle gelüftet werden sollen. Die zentrale Idee, die zu der maßgeblich von Linda Guddat gestalteten Graphik führte, war die, dass einerseits Kommunikation dargestellt und andererseits an für die deutsche und europäische Kulturgeschichte wichtige Magdeburger Persönlichkeiten erinnert werden sollte. Präsentiert werden daher, von links nach rechts: Carl Leberecht Immermann (1796-1840), der Autor des Münchhausen-Romans, Eike von Repgow (ca. 1180-1233), der Verfasser des „Sachsenspiegels“, der Schriftsteller und Pädagoge Heinrich Zschokke (1771— 1848), dem wir auch unsere Fakultätsadresse verdanken, und last - und ganz ← 11 | 12 → bestimmt nicht least - Hermann Paul (1846-1921), der Autor der Prinzipien der Sprachgeschichte“ und des Deutschen Wörterbuchs“, der ebenfalls in Magdeburg geboren und aufgewachsen ist, bevor er in Berlin und Leipzig studierte und dann in Freiburg als außerordentlicher und schließlich in München als ordentlicher Professor forschte und lehrte. Zwischen Zschokke, von Repgow und Immermann finden Sie außerdem zwei unbekannte zeitgenössische Sprachwissenschaftlerinnen bzw. Sprachwissenschaftler, die dabei sind, Großes zu verkünden. Indem Kommunikation zwischen historischen Persönlichkeiten unterschiedlicher Zeiten abgebildet wird, wird das zentrale Plakatmotiv auch zur metonymischen Darstellung von Diskurs.
Ach ja, und einen derjenigen, die auf unserem Plakat abgebildet sind, hätten wir fast vergessen: Otto von Guericke, den großen Physiker und Namenspatron unserer Universität.

Die ursprünglich differenziertere Gliederung der Tagung in Sektionen spiegelt sich weitgehend in der stärker zusammenfassenden Kapitelgliederung des vorliegenden Bandes wider:
1. Grammatik und Phraseologie
2. Text- und Diskurspragmatik
3. Semantik und Lexikologie
4. Kontrastive Studien und Fremdsprachendidaktik
5. Angewandte Linguistik
← 12 | 13 → Die einzelnen Beiträge wurden innerhalb der Sektionen folgendermaßen angeordnet: Die vier Plenarvorträge - von Gerd Antos/Karlfried Knapp, Anthea Fraser Gupta, Werner Holly und Victor Zakharov/Maria Khokhlova - sind im jeweiligen Kapitel den anderen, alphabetisch angeordneten Beiträgen vorangestellt. Diese alphabetische Reihenfolge wird an einigen Stellen jedoch unterbrochen, um thematisch eng zusammengehörende Beiträge nebeneinander zu stellen.
Zu danken haben wir v.a. unserer Universität, die die Räumlichkeiten für die Tagung bereitgestellt hatte, und unseren Instituten, die sich auch finanziell beteiligt haben. Besonderer Dank gilt auch Anja Blachney, die das Abstract-Heft erstellt, und Linda Guddat, die das Tagungsplakat entworfen hat, sowie Dirk Osterloh, der für unsere EDV-Aktivitäten verantwortlich zeichnete.
Dafür, dass der Band zum 43. Linguistischen Kolloquium mit so großer Verspätung erscheint, entschuldigen wir uns. Es liegt v.a. daran, dass der Band zum Vorgängerkolloquium erst jetzt der Öffentlichkeit vorgelegt worden ist und beim Erscheinen der Akten die Reihenfolge der Kolloquien eingehalten werden sollte. Immerhin hat die lange Publikationsgeschichte dazu geführt, dass wir uns jetzt noch mehr freuen, den fertigen Band endlich vorlegen zu können. Den Autorinnen und Autoren danken wir für die angenehme Zusammenarbeit und ihre Geduld.
Magdeburg, im September 2013
Renate Belentschikow
Angelika Bergien
Armin Burkhardt
Karin Ebeling
Katrin Schöpe ← 13 | 14 →
1In: Cole, Peter/Morgan, Jeiry L. (eds.): Speech Acts. (Syntax and Semantics. Vol. 3.) New York-San Francisco-London 1975, S. 233-256.
← 14 | 15 → 1.
Grammatik und Phraseologie ← 15 | 16 →
← 16 | 17 → Zum Prowort auf der morphologischen, semantischen, syntaktischen, textuellen und stilistischen Ebene
Im folgenden Beitrag soll es darum gehen, eine an sich weitestgehend bekannte Thematik, die häufig nur dem Bereich der Morphologie zugeordnet wird, unter verschiedenen Gesichtspunkten zu beleuchten, wobei die Grenzen einzelner Teildisziplinen der Linguistik überschritten werden.
1 Morphologie
Traditionellerweise verbindet man den Begriff Prowort mit der Wortart Pronomen. Das ist ein Fürwort, das für ein Nomen (ein Substantiv) steht, also dieses ersetzt. Es handelt sich somit um eine Substituendum-Substituens-Relation.
Der neue Mantel des Vaters → er1
Die Funktion der Substitution können aber nicht nur Pronomina erfüllen, sondern es gibt noch andere Pro-Lexeme: Pro-Verben, Pro-Adjektive, Pro-Adverbien. Und auch das Pronomen ist nur eine der beiden Möglichkeiten, wie man Substantive ersetzen kann (s. unten). Daher könnte man eine neue Kategorie einführen, eine Art Pro-Substantiv (i.w.S.), das in zwei Unterarten zerfällt: in das traditionelle Pronomen (s. oben) und in solche Substantive (Pro-Substantive i.e.S.), die als Substitute fungieren. Der Oberbegriff Pro-Wort oder Pro-Lexem hätte demnach vier Ko-Hyponyme (Pro-Substantiv, Pro-Verb, Pro-Adjektiv, Pro-Adverb) und das Pro-Substantiv wäre seinerseits ein Oberbegriff für das Pronomen und Pro-Substantiv i.e.S.

← 17 | 18 → Pro - Sub stantiv (i. w. S):
Das ist zunächst einmal das traditionelle Pronomen, ein Substituens eines Substantivs (als Substituendums). Das sog. Pro-Substantiv (i.e.S.) ist aber keine selbstständige Wortart für sich (wie das Pronomen), sondern es gehören dazu Substantive mit einer sehr allgemeinen Bedeutung, wie z.B. das Ding, das Zeug, die Sache; aber auch Substantive wie die Angelegenheit, das Problem, der Um-stand, ja sogar solche wie die Kränkung, die Kritik usw. Es geht offenbar um eine offene Reihe. Dazu jedoch mehr im nächsten Unterkapitel zur Semantik.
Pro-Verb:
Hierzu werden Verben gerechnet mit analog zum Pro-Substantiv einer sehr unpräzisen Bedeutung, mit denen man andere Verben ersetzen kann, wie z.B. tun, machen, aber auch erledigen, bewirken, zustande bringen, herbeiführen u.a.m.
Pro-Adjektiv:
Hier geht es nach demselben Prinzip um Ersatzmöglichkeiten für vollsemantische Adjektive, wie z.B. (ein) solcher, (ein) ähnlicher, (ein) gleicher; interessanterweise bietet sich hier sogar eine interrogative Variante an: was für (ein, welche).
Pro-Adverb:
Zu dieser Reihe kann man verschiedene Arten der Adverbien zählen, wie z.B. dort, hier, oben, jetzt, morgen, so, anders, aber auch andere besondere Arten der Adverbien wie Pronominaladverbien (z.B. darum, dazu) und Konjunktionaladverbien (z.B. daher, trotzdem).
2 Semantik
Unter dem semantischen Gesichtspunkt ist allen Pro-Wörtern gemeinsam, dass sie entweder
a) eine Null-Semantik aufweisen und sich nur über gewisse grammatische Kategorien definieren lassen; für das Pronomen er gilt z.B.: Nominativ (Kasus), Singular (Numerus), männlich (Genus)
oder
b) eine (sehr) reduzierte Semantik in Spuren aufweisen (Ding, machen, solch, so).
Die Pronomina (Variante a) sind daher synsemantisch und können referentiell mit einer breiten Palette verschiedener Substituenda kombiniert werden, vorausgesetzt dass sie über die genannten grammatischen Kategorien (s. oben) miteinander kongruieren. Pro-Substantive. Pro-Adjektive, Pro-Adverbien und Pro-Verben ← 18 | 19 → (Variante b) sind zwar autosemantisch, aber ihre semantische Struktur, ihre Begriffsintension ist sehr unpräzis und undifferenziert, deshalb können auch sie sich referentiell auf Vieles beziehen und als Ersatz dafür dienen. In diesem Fall spricht man von sog. Allerweltswörtern oder Passepartout-Wörtern. Insgesamt gilt hier das Prinzip der indirekten Proportionalität: Je spezifischer ein Pro-Wort in semantischer Hinsicht ausgeprägt ist, je mehr Merkmale (Seme) seine semantische Struktur aufweist, umso größer ist einerseits seine Begriffsintension, umso geringer und begrenzter ist andererseits seine referentielle Extension.
Diese Relationen sollen am folgenden Diagramm veranschaulicht werden.

Diagramm 1: Verhältnis zw. semantischer Differenzierung und paradigmatischer Einsetzbarkeit von Prowörtern - demonstriert am Pronomen und am Pro-Substantiv
← 19 | 20 → Je mehr wir uns auf der Abszissenachse nach rechts hin bewegen, um so präziser sind die angeführten Pro-Lexeme (bzw. deren lexikalische Kategorien - Hyperonyme, Fachausdrücke, Eigennamen) semantisch herausdifferenziert, um so geringer ist der referenzielle Umfang, auf den sie sich stellvertretend beziehen können (was man an den sinkenden Werten auf der Ordinatenachse ablesen kann und was sich im Diagramm in der nach rechts hin fallenden Kurve niederschlägt).
Pronomina (z.B. er, damit) sowie Pro-Substantive i.e.S. - etwa Ding, Zeug, Sache (für Konkreta) und Sache, Angelegenheit, Umstand (für Abstrakta)3 - sind als wertneutrale Allerweltswörter ohne Einschränkungen einsetzbar:
Vorsatz X. Damit kann ich mich (nicht so leicht) anfreunden.
Vorsatz X. Mit dieser Angelegenheit kann ich mich (nicht so leicht) anfreunden.
Allerweltswörter wie Versuch, Gedanke, Thema, Problem, Erklärung, Geschichte, Schlamperei, Bemühungen, Scheiße (s. obige Tabelle) können schon soweit spezifisch sein, dass es bei der Substitution zu Blockierungen kommen kann:
Vorsatz X. Mit dieser Erklärung kann ich mich (nicht) anfreunden. (neutral)
Vorsatz X1. Mit dieser Schlamperei kann ich mich nicht anfreunden. (abwertend)
Der letzte Satz kann kein bejahender Satz sein, weil Schlamperei negativ konnotiert und mit sich anfreunden semantisch nicht kongruent ist.
Die Grenze zwischen Autosemantika und Synsemantika (Allerweltswörtern/ Passepartout-Wörtern) ist jedoch fließend oder verwischt sich sogar.4
3 Syntax
Eines der zentralen Probleme scheint unter dem syntaktischen Gesichtspunkt die Abgrenzung von Pro-Wort und Korrelat zu sein. Aus Platzgründen wird dies im Folgenden nur vordergründig in beschränktem Umfang präsentiert. Zu diesem Zweck werden einige Sätze gegenübergestellt und es wird der Frage nachgegangen, in welchen Fällen es sich um ein Prowort und wann um ein Korrelat handelt bzw. nach welchen Kriterien diese Abgrenzung vorgenommen werden ← 20 | 21 → kann.5 Als methodisches Hilfsmittel werden die operationellen Verfahren Weglassbarkeit und Ersetzbarkeit herangezogen.
Weglassbarkeit:
Ich weiß es, dass er kommt. (Korrelat)
Ich weiß Ø, dass er kommt. (Null-Korrelat)
Ich weiß Ø, er kommt. (Null-Korrelat)
Er kommt, das weiß ich. (Korrelat)
Er kommt, Ø weiß ich / ich weiß. (Null-Korrelat)
Ich weiß es. Er kommt. (Prowort)
Ich weiß. Er kommt. (markiert, weil Null-Prowort)
Festzuhalten ist: Das Unterscheidungskriterium ist offenbar nicht in der Semantik zu suchen - auch Korrelate sind im Prinzip mit der Bezugsgröße referenzidentisch -, sondern auf der syntaktischen Ebene. Ein Wort ist innerhalb eines komplexen Satzes Korrelat, weil seine dominante Funktion darin besteht, Beziehungen zu anderen Teilsätzen herzustellen und dadurch als eine Art Formmittel kohäsiv zu wirken. Transphrastisch gesehen - in zwei verselbstständigten Sätzen - kann jedoch dasselbe Wort nur als (meist obligatorisches) Prowort fungieren. Prowörter sind nicht weglassbar. Korrelate sind entweder obligatorisch oder weglassbar.
Ersetzbarkeit:
Ich weiß es. Er kommt.
Ich weiß das/etwas. Er kommt.
Er hat sich damit/mit der Erklärung begnügt, dass ....
Es hat sich gestern ein Unfall ereignet.
Daraus folgt: Prowörter sind ersetzbar. Korrelate sind entweder ersetzbar oder nicht ersetzbar.
Schon die obigen Belege haben gezeigt, dass man der Vielschichtigkeit dieser Problematik nur gerecht werden kann, wenn man die Satzgrenze überschreitet. Prowörter können bzw. müssen daher auch unter dem textlinguistischen Aspekt betrachtet werden.
← 21 | 22 → 4 Textlinguistik
In der transphrastischen Textperspektive von ProWörtern spielen viele Faktoren eine Rolle, vor allem jedoch
a) Beziehung des Prowortes zum Bezugsausdruck und
b) die Entfernung der Bezugsgröße vom Prowort.
Mit Bezug auf a) unterscheidet die textuelle Ebene die rückwärtsweisende/anaphorische und die vorausweisende/kataphorische Pronominalisierung (Letzteres auch als Präpronominalisierung bekannt) (vgl. a. Bračič/Fix/Greule 2006: 8, 75).
Was die Entfernung der Bezugsgröße anbelangt - Punkt b), ist es - um Mehrdeutigkeiten zu vermeiden - wichtig, dass bei dislozierten Beziehungen auf lange topologische Distanz deutlich gemacht wird, auf welche der möglichen Bezugsgrößen ein Prowort verweist.
An das obige Unterkapitel zur Semantik anknüpfend kann man von einer Grundregel ausgehen, dass Prowörter allemal semantisch weniger spezifisch sind als ihre Bezugsgrößen, also ihre Begriffsintension geringer ist. Deshalb steht in Satzabfolgen auf der Textebene ein Oberbegriff (Hyperonym) in der Regel hinter dem Unterbegriff (Hyponym).
Sie hat sich einen alten VW-Käfer zugelegt. Mit dem Auto ist sie (nicht) zufrieden.
Damit ist sie (nicht) zufrieden.
Sie ist (nicht) zufrieden. (Null-Prowort)
Warum sind Pro-Wörter in der Regel nachgestellte Hyperonyme? Das lässt sich mithilfe der Gesetzmäßigkeiten der Thema-Rhema-Gliederung erklären: Das Rhema aus Satz 1 (einen alten VW-Käfer) ist aus der Perspektive des Nachsatzes ein Anker (Schwarz 2000: passim), an dem Satz 2 aufgehängt ist. Die Wiederaufnahme des Rhemas aus Satz 1 (einen alten VW-Käfer) durch das Thema in Satz 2 (Auto) ist eher ein strukturell-operativer Vorgang, ein logistisches Prozedere, das es ermöglichen soll, dass der Text durch das Anknüpfen des Folgesatzes fortgesetzt wird (Rekurrenz - vgl. Bračič/Fix/Greule 2006: 5).

Zu diesem Zweck braucht man kein lexisches Element, das semantisch sehr informativ ist. Der informativ-kommunikative Höhepunkt mit Gipfelakzent ← 22 | 23 → (Fokus) ist in diesem zweiten Satz erst am Ende, im Rhema zu suchen (nicht zufrieden).6
5 Stilistik
Das Prowort ist aus stilistischer Sicht ein Paralexem, das die eigentlichen Ausdrucksvarianten substituiert. Das Anderssagen ist ein immanentes Anliegen jeder Sprachschöpfung. Unser ganzes sprachliches Schaffen ist von dem Wunsch geprägt, sich (mindestens ein wenig) anders als erwartet, sprich origineller auszudrücken, Eindruck zu machen, aufzufallen. (Vgl. Sandig 2006: 153ff.) In Abhängigkeit vom Tätigkeitsbereich (Funktionalstil) zielt man darauf ab, einen Text durch angemessene Wahl und Kombination von Ausdrucksvarianten stilistisch derart zurechtzuschneiden, dass er einer konkreten kommunikativen Situation (Thema, Ziel, Adressat) optimal angepasst ist. Ein Segment dieser an sich breit aufgefächerten Thematik soll im Weiteren an einem kurzen Textausschnitt demonstriert werden. Es handelt sich in erster Linie um die kataphorische Pronominalisierung (Präpronominalisierung), die als Mittel der stilistischen Wirkung unter die Lupe genommen werden soll.
Textbeleg:
Dämonen im Schädel
1.) Es soll aufhören! 2.) Nur: Wie hört es auf? 3.) Man kann ein Glas Wasser trinken. 4.) Zwei Tassen Kaffee. 5.) Tabletten schlucken. 6.) Sich Spritzen geben lassen. 7.) Den Kopf gegen die Wand hauen. 8.) Das Gehirn operieren lassen. 9.) Sich umbringen. 10.) All das tun Menschen, um sie loszuwerden, die Krankheit, die sie stört, nervt, quält oder ihnen gar das Leben unerträglich macht: Kopfschmerzen. 11.) Noch vor 50 Jahren galt das Leiden als gottgegeben, noch vor 20 Jahren wurde das Thema in medizinischen Lehrbüchern in wenigen Sätzen abgehandelt. (aus Stern 11/2008/134; Satznummerierung von S.B.)
Der Textausschnitt beginnt mit unpersönlichen Pronomina (es in Satz 1 und Satz 2), die referentiell am wenigsten bestimmt sind und sich auf fast alles beziehen können. (S. das Diagramm 2 unten.) Sie in Satz 10 ist differenzierter bezüglich des Geschlechts. Krankheit im selben Satz ist semantisch schon viel bestimmter und steht mit dem Inhalt der Sätze 1-9 in einem logischen Zusammenhang. Die ← 23 | 24 → kommunikative Spannung (Erwartung), die auch wegen des semantisch nichttransparenten Titels durch Ungewissheit am Textbeginn eingeleitet wird, wird an dieser Stelle teilweise abgemildert, der informative Höhepunkt kommt jedoch erst am Ende des 10. Satzes durch dem Nachtrag Kopfschmerzen zustande. Leiden (Satz 11) ist ein Synonym von Krankheit, beide zusammen sind Ko-Hyperonyme von Kopfschmerzen. Thema in Satz 11 ist in seiner Semantik schon wieder ziemlich allgemein, jedoch differenzierter als die Pronomina sie oder gar es in Sätzen 1 und 2. (vgl. die Niveauunterschiede im Diagramm unten.) Im Text entsteht durch diese Präpronominalisierung eine Steigerung (Klimax), die von zwei weiteren quasi untergeordneten, eingeschalteten Steigerungen und einer Antiklimax begleitet ist. Klimax 2: Sätze 3-9 (Gegenmaßnahmen, ohne genau zu wissen, wogegen speziell sie gerichtet sind); Klimax 3: Verben in Satz 10 (stören, nerven, quälen, das Leben unerträglich machen)', Antiklimax: Satz 11 (mit Bezug auf die Behandlung von Kopfschmerzen in der Vergangenheit, als man dem Übel praktisch unbeholfen ausgeliefert war, was auch ikonisch, in wenigen Worten (gottgegeben, das Thema in wenigen Sätzen abgehandelt) zum Ausdruck gebracht wird. Aus diesen Spannungslinien und der entgegenwirkenden abrupten Retardierung entsteht in dieser Textpassage eine besondere Rhythmisierung.

6 Zusammenfassung
Prowörter i.w.S. weisen in morphologischer Hinsicht eine ziemlich kompliziert aufgebaute, die traditionellen Vorstellungen überschreitende Phänomenologie auf und sind auch syntaktisch relevant (Pro-Wort vs. Korrelat, ihre Ersetzbarkeit und Weglassbarkeit im einfachen und im komplexen Satz). Ihre Verwendung im Text kann mit semantischen Kriterien (Begriffsintension und Begriffsextension, Thema-Rhema-Gliederung) nahe gelegt werden, sie können im Text kohäsiven, kommunikativen und stilistischen Zwecken dienen.
← 24 | 25 → 7 Literatur
Bračič, Stojan/Fix, Ulla/Greule, Albrecht (2006): Textgrammatik-Textsemantik-Textstilistik. Ein textlinguistisches Repetitorium. Ljubljana.
Eroms, Hans-Werner (1986): Funktionale Satzperspektive. Tübingen.
Helbig, Gerhard/Buscha, Joachim (2001): Deutsche Grammatik. Berlin, München. Wien, Zürich, New York.
Sandig, Barbara (2006): Textstilistik des Deutschen. Berlin, New York.
Schwarz, Monika (2000): Indirekte Anaphern in Texten. Studien zur domänengebundenen Referenz und Kohärenz im Deutschen. Tübingen. ← 25 | 26 →
1Ein Beleg aus Helbig/Buscha (2001: 205), aus dem hervorgeht, dass die fehlenden Artikelwörter und Attribute nach der Transformation im Pronomen repräsentiert sind.
2Bei dieser Einteilung wird an dieser Stelle nicht auf die Möglichkeit eingegangen, dass Prowörter auch ganze (Teil)Sätze vertreten können. S. dazu weiter unten.
3Sache ist ambivalent und steht für Konkreta wie Abstrakta.
4An der Grenze zwischen a) (synsemantisch) und b) (autosemantisch) stehen etwa Fragepronomina wer und was. Bei wer kann man folgende morphologische Kategorien bestimmen: Nominativ (Kasus), Null-Numerus, Null-Genus; dafür eine semantische Kategorie ‘belebt’ (in Opposition zu ‘unbelebt’ bei was). Hier hängt also die Einsatzfähigkeit des Pro-Wortes von einer Kombination grammatischer Kategorien mit semantischen Merkmalen ab. Auch Pro-Adverbien sind z.T. semantisch bestimmbar (vgl. die Opposition dort vs. hier).
5Die Schwierigkeiten bei dieser Abgrenzung rühren hauptsächlich daher, dass Prowürter und Korrelate häufig homonym sind.
6Immerhin kann das Thema als ein in erster Linie der Kohäsion dienendes Struktur-element bisweilen auch Thematisiert werden: Sie hat sich einen alten VW-Käfer zugelegt. Mit der lahmen Ente ist sie nicht zufrieden. Indirekt wird hier also im zweiten Satz vermittelt, dass das Auto keinen starken Motor hat. Zwischen den ersten und den zweiten Satz ließe sich ein Zwischensatz einschalten: Ihre Erwerbung ist eine lahme Ente. (Vgl. Eroms 1986: 81 ff.)
1 Das Problem
Bei den Genus-Kategorien ist unstrittig, dass die Genus-Unterscheidung bei den Substantiven „inhärent“ ist, während sie bei den adjektivischen Wörtern – das sind die Adjektive, die Artikel und die adjektivischen Pronomina – eine kongruenzbedingte Formvariation ist: Adjektivische Wörter können im Gegensatz zu den Substantiven nach Genus flektieren. Daher fasst z.B. Eisenberg (2004: 20) das Genus bei den adjektivischen Wörtern als „Einheitenkategorisierung“ auf und das Genus bei den Substantiven als „Wortkategorisierung“. Genauso unstrittig ist auch, dass diese Genus-Unterscheidungen miteinander Zusammenhängen. Bisher ungeklärt ist jedoch:
(1) Wie lassen sich die Zusammenhänge und die Unterschiede dieser Genus-Unterscheidungen in einer axiomatisch aufgebauten Theorie erfassen? Insbesondere: Müssen die Genus-Begriffe – das sind der Begriff „Genus“ selbst sowie die Bezeichnungen für die einzelnen Genera – Grundbegriffe sein oder können sie definiert werden, und wenn ja: wie?
Dabei fasse ich Theorien im Wesentlichen als strukturierte Aussagenmengen auf, bei denen sich Axiome, Definitionen und (beweishare) Theoreme unterscheiden lassen.1 Bei empirischen Theorien sollte außerdem der konzeptuelle Kern, in dem die Begriffe eingeführt werden, möglichst voraussetzungsarm sein, damit der eigentlich empirische Gehalt auch als solcher formuliert werden kann (vgl. Budde 2000: 22ff.).
Antworten auf die Fragen in (1) werden regelmäßig vorausgesetzt in Untersuchungen zur Genus – Zuordnung (z.B. Fischer 2005, Chan 2005, di Meola 2007, Conzett 2006, Feigs 2007, Lingua 116.2006, II. 8), zur Genus – Kongruenz (z.B. Corbett 1991: Kap. 5–9) und zum historischen wie typo-logischen Verg1eich von Genus – Systemen (z.B. Froschauer 2003, ← 27 | 28 → Corbett 1991, Corbett/Fraser 2000). Im Folgenden werde ich meine Antwort auf die Fragen in (1), die ich im Rahmen einer umfangreicheren Untersuchung ausgearbeitet habe (Budde i.V.), skizzieren. Diese Antwort lässt sich in zwei Thesen zusammenfassen:
These 1:
Eine grammatische Genus-Unterscheidung bildet ein 3-stufiges System aus.
| ■ | einer morphologischen Klassifikation auf der Ebene der Wortstämme | _ Wortstamm-Genera |
| ■ | einer oder mehreren syntaktischen Klassifikationen auf der Ebene der Wortformen | _ Wortform-Genera |
| ■ | einer syntaktischen Klassifikation auf der Ebene der lexikalischen Wörter | _Wort-Genera |
These 2:
Die Genus-Begriffe können in der Sprachtheorie im Wesentlichen gemäß der allgemeinen Definitionsrichtung in (2) definiert und in einer Einzelsprachtheorie gemäß der allgemeinen Identifikationsrichtung in (2) identifiziert werden.
(2) Axiomatische Rekonstruktion der traditionellen Sprachwissenschaft
Allgemeine Definitionsrichtung

Allgemeine identifikationsrichtung
Nach einer kurzen Erläuterung der wesentlichen Voraussetzungen meiner Lösung werde ich die einzelnen Stufen des Genus-Systems am Beispiel des Deutschen im Umriss kennzeichnen.
2 Voraussetzungen der Lösung
Wie Eisenberg (2004: 14f.) fasse ich grammatische Kategorien als Mengen auf, nicht als Eigenschaften oder Merkmale. Grammatische Kategorien sind des Weiteren Gegenstand von Einzelsprachgrammatiken. Einzelsprachgrammatiken basieren auf Idiolektgrammatiken, wobei ein Idiolekt als homogener Anteil eines Sprachbenutzers an einer Einzelsprache wie dem Deutschen aufgefasst wird (vgl. Lieb 1993). Idiolekte sind durch Idiolektsysteme festgelegt, die aus mehreren ← 28 | 29 → Komponenten bestehen, u.a. auch aus solchen, die bestimmte grammatische Kategorien enthalten.
Namen für grammatische Kategorien wie Nf(-,S1) = Nomenform-von-S1 = {haus1, diesem1, altes1, ...} werden mithilfe der Auswahlfunktion aus Relationsbezeichnungen wie Nf = Nomenform = {(haus1, S1), (casa1, S2), (maison1, S3), (diesem1, S1), (altes1, S1), ...} abgeleitet (S1 sei ein Idiolektsystem des Standardgegenwartsdeutschen, S2 und S3 seien Idiolcktsystcme des Lateinischen bzw. Französischen).2 Während die Relationsnamen in der Sprachtheorie abstrakt einzuführen sind, und zwar möglichst durch Definitionen, müssen die Kategorien in den Einzelsprachtheorien identifiziert und im Einzelnen beschrieben werden. Am Ende wird dadurch auch die Relation selbst indirekt und schrittweise genauer bestimmt. Dabei zeigt sich, dass sich die wesentlichen Teile der traditionellen Sprachwissenschaft gemäß (2) rekonstruieren lassen.3 Was das im Konkreten heißt, ist in Budde (2000) bereits für die Wortarten gezeigt worden und soll hier am Beispiel der Genus-Kategorien illustriert werden. Beginnen wir mit den Wortform-Genera, wobei wir das Deutsche als Beispiel heranziehen.
3 Wortform-Genera am Beispiel des Deutschen
Wortform-Genera dienen bei den adjektivischen Wörtern zur Beschreibung der Wortformen: Paradigmen dieser Wörter lassen sich mithilfe von Paradigmentafeln wie in (3) und (4) beschreiben. Dabei sind freie Varianten wie dies1 und dieses1 im Nom und Akk Sg des Neutrums ebenso zugelassen wie kombinatorische Varianten, hier: die starken und schwachen Adjektivformen. Auch für eine prädikativ verwendbare Adjektivform wie hart1 gibt es einen natürlichen Platz, wenn man mit Lieb (1992:17) sogenannte neutrale Kategorien zulässt: Dies sind Kategorien, die bei der systematischen Neutralisierung von Unterscheidungen vorkommen, z.B. im Deutschen bei der Neutralisierung der Genus-Unterscheidung im Plural.
← 29 | 30 → 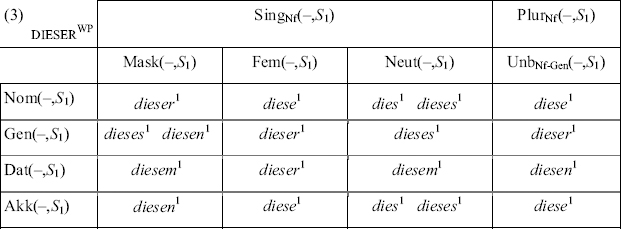

Paradigmen wie die in (3) und (4) setzen Klassifikationssysteme wie die in (5) angedeuteten voraus. Dabei lässt sich zeigen, dass das flache System in (a) dem stärker hierarchischen System in (b) vorzuziehen ist. Und wir werden gleich sehen, dass die Nf-Genera tatsächlich sogar Klassifikationen auf der Menge der Nomenformen selbst bilden und nicht nur – wie mit der gestrichelten Linie als Alternative angedeutet – Klassifikationen auf einer Teilmenge dieser Formen (S1 sei wieder ein Idiolektsystem des Standardgegenwartsdeutschen).
(5) Vorausgesetztes Klassifikationssystem auf Nf(–, S1):
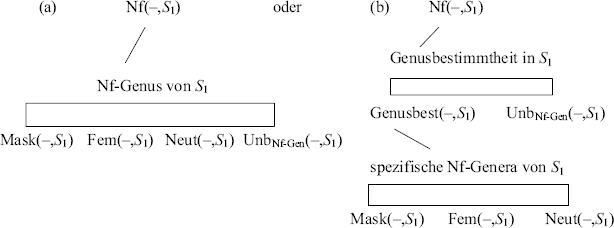
← 30 | 31 → Zu beachten ist nun erstens, dass nur funktionale Formvariation in den paradigmeninternen Kategorisierungen der Wortformen erfasst wird: Die Kategorien in den Kategorisierungen heißen daher auch „Funktionskategorien“ (vgl. insbes. Lieb 1992, 2005). Funktionskategorien kommen in syntaktischen Strukturen vor und dienen dort zur Identifizierung von syntaktischen Funktionen, die die Grundlage der Bedeutungskomposition sind, oder werden im Rahmen der Bedeutungskomposition unmittelbar interpretiert (vgl. z.B. Lieb 1983: 329ff.). Dass die Formvariation paradigmenintern ist, hängt mit traditionellen Anforderungen zusammen wie obligatorische Realisierung, Abgeschlossenheit und Oppositionsbildung (vgl. z.B. Diewald 1997: 9). Das System der Funktionskategorien gehört nach Lieb (1992: 27) zu einer Komponente des Idiolektsystems.
Zweitens sollten wir von den Klassifikationen nur verlangen, dass einige der Wörter, deren Formen in ihren Kategorisierungen eine Kategorie aus der Klassifikation enthalten,4 nach dem entsprechenden Gesichtspunkt flektieren, und nicht, dass alle Wörter dieser Art nach dem entsprechenden Gesichtspunkt flektieren.5 Damit können auch Kategorisierungen von Substantivformen Nf-Genera enthalten, und zwar auch in Sprachen wie dem Deutschen, wo die Genus-Unterscheidung bei den Substantiven eine sog. verdeckte, nicht unmittelbar an Formmerkmalen der Substantivformen selbst erkennbare Unterscheidung ist (vgl. Corbett 1991: 62f.).
← 31 | 32 → Wenn wir nun noch berücksichtigen, dass bei der Identifizierung der Substantivparadigmen auch in Sprachen wie dem Deutschen eine Genus-Unterscheidung bei den Substantiv Stämmen vorausgesetzt werden muss, dann macht es sogar in der Tat Sinn, die Genus-Unterscheidung auch auf die Substantivformen zu beziehen.
Setzen wir also die Wortform-Genera in Sprachen wie dem Deutschen als Klassifikation auf der Menge der Nomenformen insgesamt an und prüfen, was sich damit für die Wort-Genera ergibt – eine Entscheidung, für die sich übrigens bei näherer Betrachtung noch weitere gute Gründe finden lassen.
4 Wort-Genera
Wort-Genera sind Mengen lexikalischer Wörter, wobei ein lexikalisches Wort im Sinne von Lieb (1992: 43ff.) sich als Paar aus einem Wortparadigma P und einer zugehörigen lexikalischen Bedeutung b auffassen lässt. Und ein Wortparadigma ist nach Eisenberg (2004: 15 u. passim) eine Menge kategorisierter Wortformen, d.h. genauer: eine Menge von Paaren (f,J), wobei f eine Wortform und J eine Kategorisierung oder ‘Beschreibung’ dieser Wortform ist. Paradigmentafeln dienen dazu, diese Menge – eine Zuordnung von Kategorisierungen zu Wortformen – übersichtlich darzustellen (zu den Details vgl. Lieb 1992, 2005).
Damit ergeben sich Definitionen für die Wort-Genus-Begriffe fast schon automatisch: Wir brauchen bei einem substantivischen Wort nur nachzusehen, welches Nf-Genus in seinem Paradigma vorkommt. Z.B. ist ein Maskulinum ein substantivisches Wort, das in einem Paradigmen-Element die Wortform-Kategorie Mask(–,S) enthält. Lediglich bei der Kategorie UNBNF-GEN(–,S) müssen wir aufpassen: Wenn wir die Genus-Neutralisierung im Plural6 dadurch erfassen, dass wir sämtlichen Pluralformen, auch denen der Substantive, UnbNf-Gen(–,S) zuordnen, dann enthält ein Maskulinum wie TISCHW in seinem Paradigma sowohl Kategorisierungen mit dem Nf-Genus Mask(–,S) als auch solche mit UnbNf-Gen(–,S). Wörter, die als Ganze für Genus unbestimmt sind – wie das Plurale tantum LEUTEW – dürfen dahingegen in ihrem Paradigma in sämt – lichen Kategorisierungen nur die neutrale Kategorie UnbNf-Gen(–,S) enthalten. Wir können daher folgendermaßen definieren:
← 32 | 33 → (6) Definitionen (in der Sprachtheorie): Sei S ein Idiolektsystem.
a. (P,b) ist ein MASK[ULINUM] von S genau dann, wenn gilt [gdwg]:
(i) (P,b) ist ein substantivisches Wort von S,
(ii) es gibt ein (fJ) ϵ P mit Mask(–,S) ϵ J.
b. (P,b) ist ein FEM[ININUM] von S gdwg: ... [analog].
c. (P,b) ist ein NEUTR[UM] von S gdwg: ... [analog],
d. (P,b) ist ein UNB[ESTIMMT-FÜR]W-GEN[US][-WORT] von S gdwg:
(i) (P,b) ist ein substantivisches Wort von S,
(ii) für alle (f,J) ϵ P gilt: UnbNf-Gen(–,S) ϵ J.
Die Bedingungen (i) schließen adjektivische Wörter aus. Und Genus-Schwankungen (der/das Joghurt) und Genus-Split (z.B. Genus I im Singular und Genus II im Plural; vgl. Corbett 1991: 150ff.) lassen sich durch nicht-leere Durchschnitte MASK/NEUT(– ,S) usw. erfassen.
Für unser Idiolektsystem S1 des Standardgegenwartsdeutschen können wir nun in einer Theorie des Deutschen beweisen: Die Wort-Genera von S1, das sind gerade MASK(–,S1), FEM(–,S1), NEUT(–,S1) und UNBW-GEN(–,S1), bilden eine Klassifikation auf der Menge der substantivischen Wörter von S1.
Was uns jetzt noch fehlt, ist eine Definition des Begriffs „Wort-Genus“ selbst. Diese ist aber leicht, wenn wir uns den Übergang von den Nf-Genera zu den Wort-Genera in (6) noch einmal genauer ansehen: Die Wortgenera sind gerade diejenigen nicht-leeren Mengen L, zu denen es ein Nf-Genus K gibt, so dass ein substantivisches Wort (P,b) genau dann zu L gehört, wenn K ein spezifisches Nf-Genus wie Mask(–,S) ist und das Wort in wenigstens einem Paradigmenelement K enthält; oder wenn K die Kategorie UnbNf_Gen(–,S) ist und das Wort in sämtlichen Paradigmenelementen nur K als Genus-Kategorie enthält:
(7) Definition (in der Sprachtheorie): Sei S ein Idiolektsystem.
Wort-Genus(S)
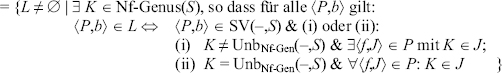
In der Sprachtheorie kann (und muss) sichergestellt werden, ggf. durch ein Axiom, dass für jedes Nf-Genus höchstens eine Menge L dieser Art existiert. Außerdem ist zuzulassen, dass es Idiolcktsystcme S gibt, in denen UnbNf-Gen(–,S) nur bei adjektivischen Wörtern vorkommt und damit UNBNw-GEN(–,S) = Ø ist. Da Ø aber nicht Element einer Klassifikation sein kann, Wort-Genus(S) aber eine Klassifikation sein soll, muss L = Ø explizit ausgeschlossen werden.
Von den Wort-Genera kommen wir nun ebenfalls sehr einfach zu den Wortstamm-Genera.
Details
- Seiten
- 762
- Erscheinungsjahr
- 2014
- ISBN (Hardcover)
- 9783631651667
- ISBN (PDF)
- 9783653044980
- ISBN (MOBI)
- 9783653986174
- ISBN (ePUB)
- 9783653986181
- DOI
- 10.3726/978-3-653-04498-0
- Sprache
- Deutsch
- Erscheinungsdatum
- 2014 (Juli)
- Schlagworte
- Kontrastive Linguistik Phraseologie Lexikologie Language Pedagogy Grammatik
- Erschienen
- Frankfurt am Main, Berlin, Bern, Bruxelles, New York, Oxford, Wien, 2014. 762 S., 1 farb. Abb., 13 s/w Abb., 68 Tab., 24 Graf.
- Produktsicherheit
- Peter Lang Group AG
Biographische Angaben
Katrin Schöpe (Band-Herausgeber:in)
Renate Belentschikow (Band-Herausgeber:in)
Angelika Bergien (Band-Herausgeber:in)
Armin Burkhardt (Band-Herausgeber:in) ![]()
Die Herausgeber sind Professoren und Wissenschaftliche Mitarbeiter der Universität Magdeburg und forschen dort als Linguisten in der Anglistik, Germanistik und Slavistik. The editors are professors and researchers at Magdeburg University in the areas of English, German and Slavic Linguistics.
